AI-POWERED DOCS
What do you want to know?
Bước 4: Huấn Luyện Mô Hình AI
Các vùng quan tâm (ROI) của bạn đã được thiết lập. Bây giờ là lúc dạy cho AI biết như thế nào là "tốt" và "xấu".
Ba quy tắc cơ bản của việc huấn luyện
Trước khi làm bất cứ điều gì khác, hãy ghi nhớ ba quy tắc này. Chúng áp dụng dù bạn đang huấn luyện một classifier hay segmenter, với 5 hình ảnh hay 500 hình ảnh.
Quy tắc 1: Chỉ gán nhãn dựa trên hình ảnh
Đừng bao giờ nhìn vào bộ phận vật lý (hoặc đặt nó dưới kính hiển vi) để quyết định xem nó tốt hay xấu. Nếu bạn không thể nhìn thấy lỗi trong hình ảnh camera, AI không thể học được nó.
AI không phải là phép màu. Nó chỉ có thể làm việc với những gì camera nhìn thấy. Nếu bạn gán nhãn một bộ phận là "lỗi" dựa trên điều gì đó bạn nhận thấy khi chạm vào nó hoặc phóng to dưới kính lúp, nhưng hình ảnh camera trông vẫn ổn, bạn đang dạy AI nhìn thấy một thứ không tồn tại.
Nếu bạn không thể gán nhãn chỉ từ hình ảnh, hãy quay lại bước Install và sửa lại cài đặt vật lý: ống kính tốt hơn, ánh sáng tốt hơn, lắp đặt gần hơn, góc khác.
Quy tắc 2: Kiểm tra lại nhãn hai lần và ba lần
Việc gán nhãn sai xảy ra với mọi người; các kỹ sư có kinh nghiệm cũng vậy. Nhưng một nhãn sai trong một tập dữ liệu nhỏ có thể phá hỏng kết quả của bạn.
Với 5 hình ảnh huấn luyện, một nhãn sai làm hỏng 20% dữ liệu huấn luyện của bạn. Điều đó thật thảm họa.
Trước mỗi lần huấn luyện: Nhấp vào View All ROIs và xác minh từng chú thích một. Đây là điều dễ sửa nhất và có tác động lớn nhất.
Quy tắc 3: Bắt đầu nhỏ, lặp lại nhanh
Đừng gán nhãn 50 hình ảnh rồi nhấn train. Thay vào đó, hãy tạo một vòng lặp chặt chẽ: Gán nhãn 10-15 hình ảnh mỗi lớp, huấn luyện (khoảng 30 giây), kiểm tra và cố gắng phá nó, sau đó thêm dữ liệu có mục tiêu vào những chỗ nó thất bại. Lặp lại chu kỳ này 2-4 lần.
Vòng lặp này là con đường nhanh nhất để có một mô hình tốt.
Quy trình huấn luyện từng bước
1. Chụp hình ảnh huấn luyện ban đầu
Với recipe của bạn đang hoạt động và các bộ phận đang được đưa qua (hoặc được đặt thủ công), hãy chụp hình ảnh. Bạn cần tối thiểu 10-15 hình ảnh mỗi lớp để bắt đầu.
Đối với một kiểm tra pass/fail đơn giản:
- 10-15 hình ảnh của các bộ phận tốt
- 10-15 hình ảnh của các bộ phận lỗi
2. Xác định các lớp
Trong giao diện gán nhãn, thêm các lớp mà mỗi loại kiểm tra cần. Đối với một classifier, điều này có thể là:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
Hãy giữ đơn giản lúc đầu. Bạn luôn có thể thêm các lớp sau.
3. Gán nhãn các hình ảnh
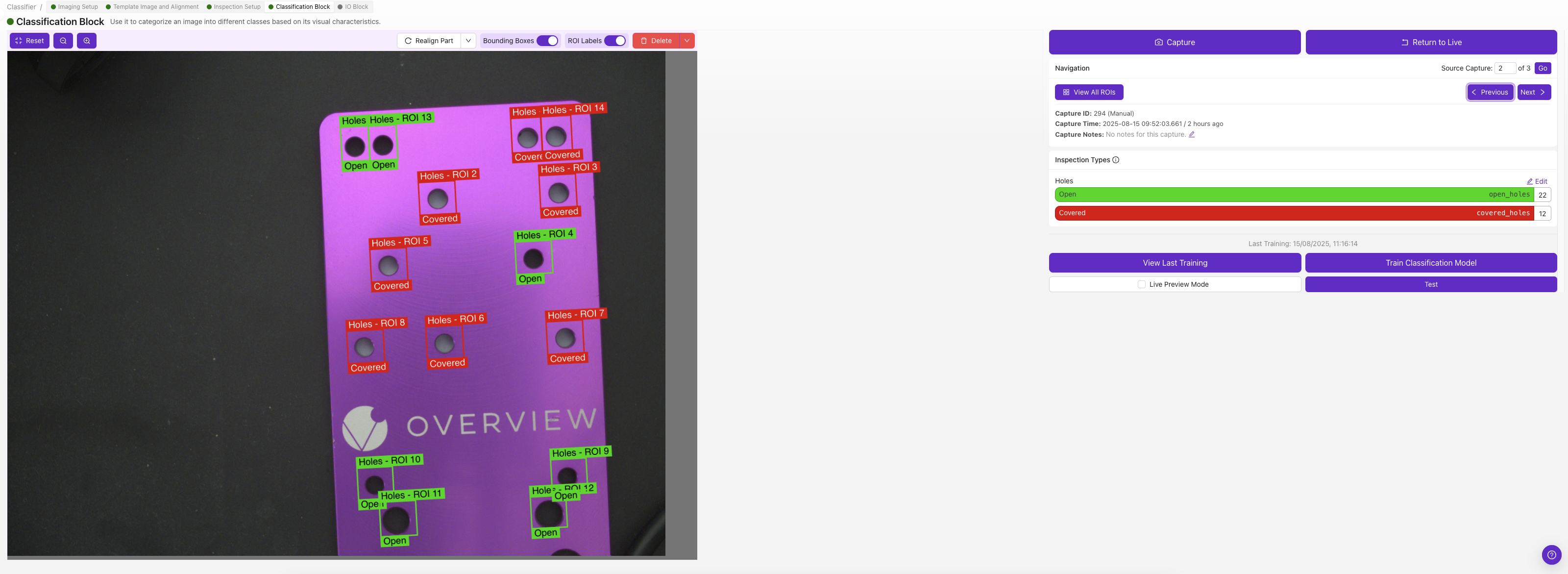
Mỗi ROI nhận một lớp phân loại riêng — chọn lớp mô tả ROI đó trong hình ảnh đó (ví dụ: "pass" hoặc "fail").
OV10i chỉ hỗ trợ classifier. Để phân đoạn ở cấp độ pixel, bạn cần OV20i hoặc OV80i.
4. Huấn luyện mô hình
Nhấp vào Train. Classifier cung cấp hai chế độ huấn luyện:
- Fast mode — khoảng 30 giây đến một phút. Tốt nhất để lặp lại nhanh trong quá trình thiết lập, kiểm tra tính hợp lý của nhãn, và các bộ phận dễ/được phân tách rõ ràng. Độ chính xác thấp hơn so với production mode nhưng cho phép bạn thấy tín hiệu nhanh.
- Production mode — mất nhiều thời gian hơn nhưng tạo ra một mô hình chính xác hơn đáng kể. Luôn sử dụng Production mode trước khi triển khai lên dây chuyền. Đối với các bộ phận khó, các lỗi khó phân biệt, hoặc bất kỳ thứ gì bạn sẽ tin tưởng trong sản xuất, Production mode là câu trả lời đúng.
Một nhịp điệu tốt: lặp lại trong Fast mode trong khi bạn đang dọn dẹp nhãn và thêm dữ liệu, sau đó chạy Production một khi kết quả trông tốt — và một lần nữa trước khi triển khai.
5. Kiểm Tra với Live Preview

Nhấp vào Live Preview Mode và cho các bộ phận chạy qua. Bảng Test hiển thị class dự đoán và confidence score cho mỗi ROI. Hãy chú ý đến:
- Các trường hợp dễ nhận được kết quả đúng với độ tin cậy cao
- Những chỗ model gặp khó khăn (độ tin cậy thấp, hoặc kết quả sai)
- Các trường hợp ranh giới — thường là bất kỳ trường hợp nào dưới 70% độ tin cậy
Hãy thử làm nó thất bại. Tìm các trường hợp mà model bị lỗi. Những kết quả có độ tin cậy thấp đó chính là lộ trình cho vòng gán nhãn tiếp theo.
6. Thêm dữ liệu có mục tiêu
Đừng thêm hình ảnh mới một cách ngẫu nhiên. Hãy thêm các hình ảnh nhắm cụ thể vào các kiểu lỗi bạn đã tìm thấy:
- Nếu model nhầm vết xước với phản chiếu, hãy thêm nhiều ví dụ của cả hai
- Nếu model bỏ sót các lỗi nhỏ, hãy thêm nhiều hình ảnh về các lỗi nhỏ
- Nếu model thất bại với các bộ phận ở góc, hãy thêm nhiều ví dụ ở góc
7. Huấn luyện lại và kiểm tra lại
Lặp lại các bước 4-6 từ hai đến bốn lần. Mỗi lần lặp sẽ cải thiện độ chính xác. Để có hướng dẫn chi tiết hơn — bao gồm cách thêm hình ảnh mới vào model hiện có mà không mất quá trình huấn luyện trước đó — xem Thêm Dữ Liệu & Huấn Luyện Lại.
Augmentations: dạy AI xử lý các biến thể
Augmentations sẽ sửa đổi ngẫu nhiên các hình ảnh huấn luyện của bạn trong quá trình huấn luyện — điều chỉnh độ sáng, thêm xoay, tinh chỉnh độ tương phản, v.v. Mỗi hình ảnh được đưa vào AI hàng trăm lần với các augmentations hơi khác nhau, nhưng nhãn vẫn giữ nguyên. Đây là cách bạn tạo ra một model có khả năng chống chịu tốt với điều kiện thực tế mà không cần phải chụp ví dụ cho mọi biến thể có thể xảy ra.
Những gì nên bật mặc định
Một lượng nhỏ biến thể về brightness (độ sáng) hầu như luôn đáng để bật — ngay cả nhà máy được kiểm soát chặt chẽ nhất cũng có đèn trần nhấp nháy, bóng đổ thay đổi theo ca làm việc, và LED bị trôi nhẹ theo thời gian. Brightness augmentation giúp model có khả năng chống chịu với tất cả những điều đó về cơ bản là miễn phí.
Rotation: hữu ích, nhưng hãy chú ý đến hình dạng ROI
Rotation augmentation rất tốt nếu các bộ phận của bạn thực sự có thể đến ở các góc khác nhau (ốc vít lỏng trên băng tải, bộ phận đặt bằng tay, bất cứ thứ gì không được giữ trong đồ gá). Nhưng nó tương tác với hình dạng ROI:
- ROI vuông: rotation augmentation hoạt động tốt — hình ảnh đã xoay vẫn nằm gọn trong khung ROI.
- ROI không vuông trên classifier: việc xoay có thể cắt xén hình ảnh. Khi một ROI cao và hẹp được xoay 45°, các góc của nội dung đã xoay sẽ nằm ngoài khung và model sẽ huấn luyện trên hình ảnh không đầy đủ. Nếu bộ phận của bạn có thể xoay, hãy làm ROI vuông hoặc dựa vào Aligner để xử lý xoay từ đầu để bạn không cần rotation augmentation ở đây.
Khi nào KHÔNG sử dụng một augmentation cụ thể
Quy tắc chung: đừng augment thuộc tính mà bạn đang kiểm tra. Nếu bạn đang cố gắng phát hiện hướng, rotation augmentation sẽ dạy model rằng các bộ phận bị lộn ngược vẫn "tốt."
- Kiểm tra tính nhất quán của màu sắc? Đừng sử dụng saturation augmentation.
- Kiểm tra độ mờ/lấy nét? Đừng sử dụng motion blur augmentation.
- Kiểm tra hướng? Đừng sử dụng rotation augmentation (và có lẽ cũng đừng sử dụng Aligner).
Sự đa dạng của dữ liệu rất quan trọng
Dữ liệu huấn luyện của bạn nên đại diện cho toàn bộ phạm vi mà AI sẽ thấy trong sản xuất:
- Các thời điểm khác nhau trong ngày (nếu ánh sáng thay đổi)
- Các lô bộ phận khác nhau (bề mặt hoàn thiện có thể khác nhau đôi chút)
- Các bộ phận ở các vị trí khác nhau trong khung hình
- Cả các trường hợp dễ và khó
Tập trung vào các trường hợp khó nhất. Nếu dữ liệu huấn luyện của bạn bao gồm 10 bộ phận khó phân loại nhất, thì 90% các bộ phận dễ sẽ trở nên đơn giản đối với AI.
Khả năng học cao
AI của camera OV được thiết kế để tiếp tục cải thiện với nhiều dữ liệu hơn. Không giống như nhiều hệ thống AI bị chững lại sau 20 hình ảnh, mô hình này tiếp tục cải thiện với 50, 100, thậm chí hơn 500 hình ảnh. Hầu hết các kiểm tra hoạt động tốt với 5-10 hình ảnh, nhưng nếu bạn có một bài toán đa lỗi phức tạp, đừng ngần ngại tiếp tục thêm dữ liệu.
Tăng tốc với dữ liệu tổng hợp: Defect Studio
Sẽ thế nào nếu bạn cần huấn luyện cho một lỗi hiếm khi gặp? Một con vít bị thiếu mà bạn phải cố ý gỡ ra, một vết xước bạn phải tạo ra, một vết nứt xảy ra một lần trong một nghìn bộ phận? Việc đợi hàng tháng để thu thập đủ ví dụ là không thực tế.
OV Auto-Defect Creator Studio tại tools.overview.ai giải quyết vấn đề này. Nó tạo ra các hình ảnh lỗi tổng hợp giống thực tế, nhanh hơn tới 10.000 lần so với việc đợi các lỗi thực tế xuất hiện trên dây chuyền sản xuất.
Cách hoạt động: 5 bước đơn giản
- Tải lên một hình ảnh tốt của bộ phận
- Đánh dấu khu vực mà lỗi sẽ xuất hiện
- Mô tả lỗi bằng tiếng Anh đơn giản (ví dụ: "deep scratch across the surface" hoặc "missing solder joint")
- Tạo các biến thể lỗi (AI tạo ra kết quả giống thực tế)
- Xuất các hình ảnh tổng hợp trực tiếp vào tập huấn luyện của bạn
Tại sao dữ liệu tổng hợp hoạt động
Các hình ảnh được tạo ra không chỉ là các artifact "dán lên". Chúng là các biến thể giống thực tế phù hợp với ánh sáng, góc camera và bề mặt bộ phận thực tế của bạn. AI hiểu được vật lý của cách các lỗi trông như thế nào trong điều kiện chụp ảnh cụ thể của bạn.
Các trường hợp sử dụng:
- Lỗi hiếm: Huấn luyện cho các chế độ lỗi mà bạn chưa bao giờ (hoặc hiếm khi) thấy
- Ra mắt sản phẩm mới: Xây dựng kiểm tra trước khi bộ phận lỗi đầu tiên rời khỏi dây chuyền
- Trường hợp biên: Tạo các ví dụ ranh giới để cải thiện ranh giới quyết định của AI
- Tăng cường dữ liệu: Bổ sung các tập dữ liệu nhỏ với sự đa dạng tổng hợp
Xem nó hoạt động
Cách tiếp cận tốt nhất: trước tiên huấn luyện với 3-5 hình ảnh thực ban đầu của bạn, xác định những nơi AI gặp khó khăn, sau đó sử dụng Defect Studio để tạo các ví dụ tổng hợp có mục tiêu cho các chế độ lỗi cụ thể đó. Dữ liệu thực dạy nền tảng; dữ liệu tổng hợp lấp đầy khoảng trống.
Danh Sách Kiểm Tra Huấn Luyện
Trước khi tiếp tục, hãy xác nhận:
- Đã chụp hình ảnh ban đầu, tối thiểu 10-15 hình mỗi class
- Tất cả nhãn đã được kiểm tra kỹ (View All ROIs)
- Đã huấn luyện và kiểm tra với Live Preview
- Đã xác định các chế độ lỗi và thêm dữ liệu mục tiêu
- Đã hoàn thành 2-4 vòng lặp gán nhãn → huấn luyện → kiểm tra
- Kết quả đáp ứng kỳ vọng
Model đã được huấn luyện và trông tốt? Chuyển sang Bước 5: Thiết Lập Outputs.