KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
Schritt 4: KI-Modell trainieren
Ihre Regions of Interest (ROIs) sind festgelegt. Jetzt ist es an der Zeit, der KI beizubringen, wie "gut" und "schlecht" aussehen.
Die drei Grundregeln des Trainings
Bevor Sie loslegen, verinnerlichen Sie diese drei Regeln. Sie gelten unabhängig davon, ob Sie einen Classifier oder einen Segmenter trainieren, mit 5 oder 500 Bildern.
Regel 1: Labeln Sie ausschließlich anhand des Bildes
Schauen Sie sich niemals das physische Teil an (oder legen Sie es unter ein Mikroskop), um zu entscheiden, ob es gut oder schlecht ist. Wenn Sie den Defekt im Kamerabild nicht sehen können, kann die KI ihn auch nicht lernen.
Die KI ist keine Zauberei. Sie kann nur mit dem arbeiten, was die Kamera sieht. Wenn Sie ein Teil als "defekt" labeln, basierend auf etwas, das Sie durch Tasten oder Vergrößern unter einer Lupe bemerkt haben, das Kamerabild aber in Ordnung aussieht, bringen Sie der KI bei, etwas zu sehen, das gar nicht existiert.
Wenn Sie nicht allein anhand des Bildes labeln können, kehren Sie zum Install-Schritt zurück und korrigieren Sie den physischen Aufbau: bessere Optik, bessere Beleuchtung, nähere Montage, anderer Winkel.
Regel 2: Überprüfen Sie Ihre Labels doppelt und dreifach
Falsche Labels passieren jedem; auch erfahrenen Ingenieuren. Aber ein einziges falsches Label in einem kleinen Datensatz kann Ihre Ergebnisse zerstören.
Bei 5 Trainingsbildern beschädigt ein falsches Label 20 % Ihrer Trainingsdaten. Das ist katastrophal.
Vor jedem Trainingslauf: Klicken Sie auf View All ROIs und überprüfen Sie jede einzelne Annotation. Das ist das am einfachsten zu behebende und gleichzeitig wirkungsvollste Element.
Regel 3: Klein anfangen, schnell iterieren
Labeln Sie nicht 50 Bilder und drücken Sie dann auf Train. Erstellen Sie stattdessen einen engen Zyklus: Labeln Sie 10–15 Bilder pro Klasse, trainieren Sie (ca. 30 Sekunden), testen Sie und versuchen Sie, das Modell zu brechen, und fügen Sie dann gezielt Daten dort hinzu, wo es versagt. Wiederholen Sie diesen Zyklus 2–4 Mal.
Dieser Zyklus ist Ihr schnellster Weg zu einem guten Modell.
Schritt-für-Schritt-Trainingsablauf
1. Erste Trainingsbilder aufnehmen
Mit aktivem Rezept und durchlaufenden (oder manuell platzierten) Teilen nehmen Sie Bilder auf. Sie benötigen mindestens 10–15 Bilder pro Klasse, um zu beginnen.
Für eine einfache Pass/Fail-Inspektion:
- 10–15 Bilder von guten Teilen
- 10–15 Bilder von defekten Teilen
2. Klassen definieren
Fügen Sie in der Labeling-Oberfläche die Klassen hinzu, die jeder Inspektionstyp benötigt. Für einen Classifier könnte dies sein:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
Halten Sie es zu Beginn einfach. Sie können jederzeit weitere Klassen hinzufügen.
3. Bilder labeln
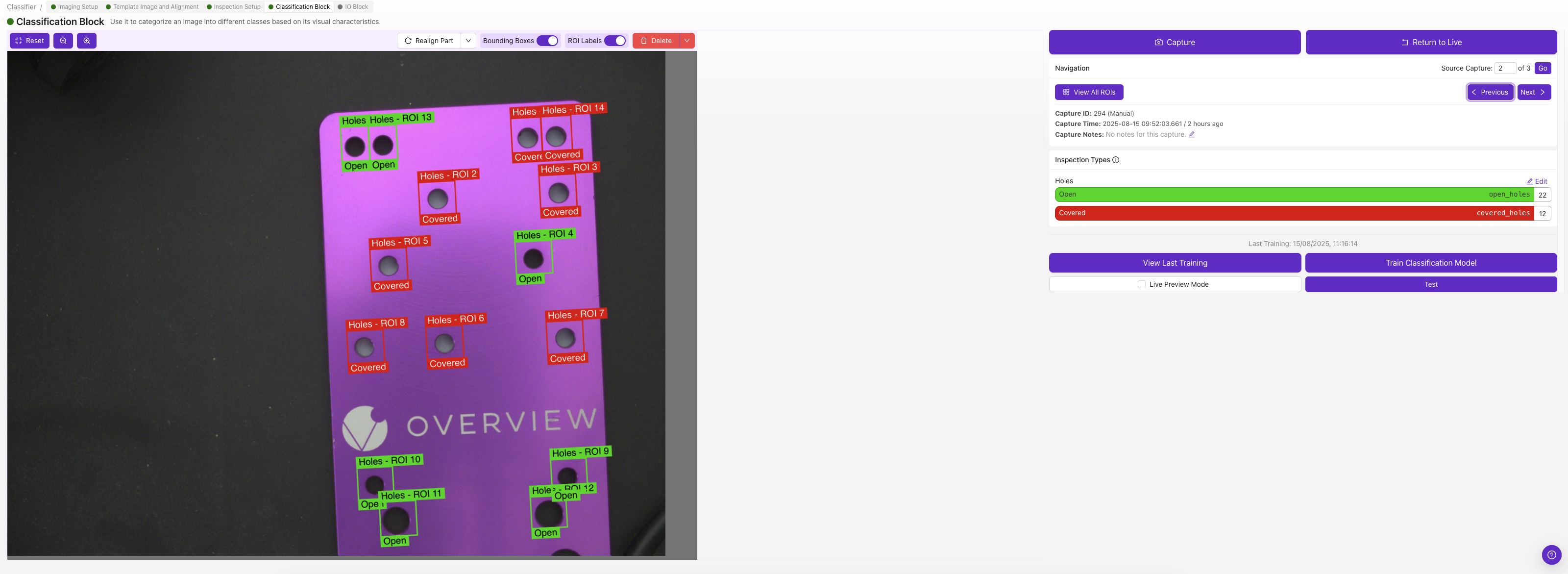
Jede ROI erhält ihre eigene Klassifikationsklasse — wählen Sie die Klasse, die diese ROI in diesem Bild beschreibt (z. B. "pass" oder "fail").
Der OV10i unterstützt nur Classifier. Für pixelgenaue Segmentierung benötigen Sie einen OV20i oder OV80i.
4. Modell trainieren
Klicken Sie auf Train. Der Classifier bietet zwei Trainingsmodi:
- Fast mode — etwa 30 Sekunden bis eine Minute. Am besten geeignet für schnelle Iterationen während der Einrichtung, zur Plausibilitätsprüfung Ihrer Labels und für einfache/gut trennbare Teile. Die Genauigkeit ist geringer als im Production mode, aber Sie sehen schnell ein Signal.
- Production mode — dauert länger, liefert aber ein deutlich genaueres Modell. Verwenden Sie vor dem Deployment in die Linie immer den Production mode. Für schwierige Teile, schwer zu unterscheidende Defekte oder alles, worauf Sie sich in der Produktion verlassen müssen, ist der Production mode die richtige Wahl.
Ein guter Rhythmus: Iterieren Sie im Fast mode, während Sie Labels bereinigen und Daten hinzufügen, und führen Sie dann den Production mode aus, sobald das Ergebnis gut aussieht — und erneut vor dem Deployment.
5. Test mit Live-Vorschau

Klicken Sie auf Live Preview Mode und führen Sie Teile durch. Das Test-Panel zeigt die vorhergesagte Klasse und den Confidence Score für jede ROI an. Achten Sie auf:
- Einfache Fälle, die mit hoher Confidence das richtige Verdikt erhalten
- Schwierigkeiten (geringe Confidence oder falsches Verdikt)
- Grenzfälle – typischerweise alles unter 70 % Confidence
Versuchen Sie, das Modell an seine Grenzen zu bringen. Finden Sie die Fälle, in denen es scheitert. Diese Verdikte mit geringer Confidence sind Ihre Roadmap für die nächste Labeling-Runde.
6. Gezielte Daten hinzufügen
Fügen Sie keine zufälligen neuen Bilder hinzu. Fügen Sie Bilder hinzu, die gezielt auf die gefundenen Fehlermodi abzielen:
- Wenn Kratzer mit Reflexionen verwechselt werden, fügen Sie mehr Beispiele von beiden hinzu
- Wenn kleine Defekte übersehen werden, fügen Sie mehr Bilder kleiner Defekte hinzu
- Wenn Teile in den Ecken nicht erkannt werden, fügen Sie mehr Eckbeispiele hinzu
7. Erneut trainieren und testen
Wiederholen Sie die Schritte 4–6 zwei- bis viermal. Jede Iteration sollte die Genauigkeit verbessern. Für eine detailliertere Anleitung – einschließlich des Hinzufügens neuer Bilder zu einem bestehenden Modell, ohne das vorherige Training zu verlieren – siehe Daten hinzufügen & Erneutes Training.
Augmentations: Der KI beibringen, mit Variationen umzugehen
Augmentations modifizieren Ihre Trainingsbilder während des Trainingsprozesses zufällig – durch Anpassung der Helligkeit, Hinzufügen von Rotation, Verändern des Kontrasts usw. Jedes Bild wird der KI hunderte Male mit leicht unterschiedlichen Augmentations zugeführt, aber das Label bleibt gleich. So machen Sie ein Modell robust gegenüber realen Bedingungen, ohne ein Beispiel für jede mögliche Variation erfassen zu müssen.
Was standardmäßig aktiviert werden sollte
Eine geringe Brightness-Variation lohnt sich fast immer – selbst die kontrollierteste Fabrik hat Deckenbeleuchtung, die flackert, Schatten, die sich während der Schicht verschieben, und geringfügige LED-Drift im Laufe der Zeit. Brightness-Augmentation macht das Modell quasi kostenlos widerstandsfähig gegen all das.
Rotation: nützlich, aber achten Sie auf die ROI-Form
Rotation-Augmentation ist großartig, wenn Ihre Teile tatsächlich in unterschiedlichen Winkeln ankommen können (lose Schrauben auf einem Förderband, handplatzierte Teile, alles, was nicht in einer Vorrichtung gehalten wird). Aber sie interagiert mit der ROI-Form:
- Quadratische ROI: Rotation-Augmentation funktioniert sauber – das rotierte Bild passt weiterhin in den ROI-Rahmen.
- Nicht-quadratische ROI bei einem Classifier: Rotation kann das Bild beschneiden. Wenn eine hohe, schmale ROI um 45° gedreht wird, fallen die Ecken des rotierten Inhalts aus dem Rahmen, und das Modell trainiert auf einem unvollständigen Bild. Wenn sich Ihr Teil drehen kann, machen Sie entweder die ROI quadratisch oder verlassen Sie sich auf den Aligner, um die Rotation vorgelagert zu handhaben, sodass Sie hier keine Rotation-Augmentation benötigen.
Wann eine bestimmte Augmentation NICHT verwendet werden sollte
Die allgemeine Regel: Augmentieren Sie nicht die Eigenschaft, die Sie inspizieren. Wenn Sie die Orientierung erkennen wollen, lehrt die Rotation-Augmentation das Modell, dass auf dem Kopf stehende Teile immer noch „gut" sind.
- Inspektion auf Farbkonsistenz? Verwenden Sie keine Saturation-Augmentation.
- Inspektion auf Unschärfe/Fokus? Verwenden Sie keine Motion-Blur-Augmentation.
- Inspektion auf Orientierung? Verwenden Sie keine Rotation-Augmentation (und wahrscheinlich auch nicht den Aligner).
Datenvielfalt ist entscheidend
Ihre Trainingsdaten sollten die gesamte Bandbreite dessen abbilden, was die KI in der Produktion sehen wird:
- Verschiedene Tageszeiten (falls sich die Beleuchtung ändert)
- Verschiedene Teilechargen (Oberflächenbeschaffenheit kann leicht variieren)
- Teile in unterschiedlichen Positionen innerhalb des Bildausschnitts
- Sowohl einfache als auch schwierige Fälle
Konzentrieren Sie sich auf die schwierigsten Fälle. Wenn Ihre Trainingsdaten die 10 am schwierigsten zu klassifizierenden Teile enthalten, sind die 90 % der einfachen Teile für die KI trivial.
Hohe Lernkapazität
Die KI der OV-Kamera ist darauf ausgelegt, sich mit mehr Daten kontinuierlich zu verbessern. Im Gegensatz zu vielen KI-Systemen, die nach 20 Bildern ein Plateau erreichen, verbessert sich dieses Modell mit 50, 100 oder sogar mehr als 500 Bildern weiter. Die meisten Inspektionen funktionieren bereits mit 5–10 Bildern hervorragend, aber bei einem komplexen Problem mit mehreren Defekten sollten Sie nicht zögern, weitere Daten hinzuzufügen.
Beschleunigung mit synthetischen Daten: Defect Studio
Was, wenn Sie für einen Defekt trainieren müssen, den Sie nur selten sehen? Eine fehlende Schraube, die Sie absichtlich entfernen müssten, ein Kratzer, den Sie erzeugen müssten, ein Riss, der einmal pro tausend Teile auftritt? Monatelang auf genügend Beispiele zu warten, ist nicht praktikabel.
Das OV Auto-Defect Creator Studio unter tools.overview.ai löst dieses Problem. Es generiert fotorealistische synthetische Defektbilder – bis zu 10.000-mal schneller, als auf das tatsächliche Auftreten von Defekten in der Produktionslinie zu warten.
So funktioniert es: 5 einfache Schritte
- Laden Sie ein einwandfreies Bild Ihres Teils hoch
- Markieren Sie den Bereich, in dem der Defekt erscheinen soll
- Beschreiben Sie den Defekt in einfachem Englisch (z. B. „deep scratch across the surface" oder „missing solder joint")
- Generieren Sie die Defektvariationen (die KI erstellt fotorealistische Ergebnisse)
- Exportieren Sie die synthetischen Bilder direkt in Ihren Trainingsdatensatz
Warum synthetische Daten funktionieren
Die generierten Bilder sind keine bloß „aufgeklebten" Artefakte. Es handelt sich um fotorealistische Variationen, die zu Ihrer tatsächlichen Beleuchtung, Ihrem Kamerawinkel und Ihrer Teileoberfläche passen. Die KI versteht die Physik dahinter, wie Defekte unter Ihren spezifischen Bildgebungsbedingungen aussehen.
Anwendungsfälle:
- Seltene Defekte: Trainieren Sie für Fehlermodi, die Sie noch nie (oder nur selten) gesehen haben
- Markteinführung neuer Produkte: Erstellen Sie eine Inspektion, bevor das erste fehlerhafte Teil vom Band läuft
- Grenzfälle: Generieren Sie Grenzbeispiele, um die Entscheidungsgrenze der KI zu verbessern
- Datenaugmentation: Ergänzen Sie kleine Datensätze mit synthetischer Vielfalt
In Aktion sehen
Der beste Ansatz: Trainieren Sie zunächst mit Ihren ersten 3–5 echten Bildern, identifizieren Sie, wo die KI Schwierigkeiten hat, und verwenden Sie dann Defect Studio, um gezielt synthetische Beispiele für diese spezifischen Fehlermodi zu generieren. Echte Daten vermitteln die Basis, synthetische Daten füllen die Lücken.
Trainings-Checkliste
Bevor Sie fortfahren, stellen Sie sicher:
- Erste Bilder aufgenommen, mindestens 10–15 pro Klasse
- Alle Labels doppelt überprüft (View All ROIs)
- Mit Live Preview trainiert und getestet
- Fehlermodi identifiziert und gezielte Daten hinzugefügt
- 2–4 Iterationen von Labeln → Trainieren → Testen abgeschlossen
- Ergebnisse entsprechen den Erwartungen
Modell trainiert und sieht gut aus? Weiter zu Schritt 5: Einrichten der Ausgaben.