AI 驱动文档
您想了解什么?
OCR (Optical Character Recognition)
OV80i 可以使用预训练的 OCR 模型,直接从相机图像中读取打印的文本、序列号、日期代码及其他字母数字字符。与分类器和分割器不同,OCR 无需训练数据,开箱即用。
OCR 适用于以下场景:
- 验证序列号或批号代码是否与预期值匹配
- 确认标签存在且可读
- 读取日期/有效期代码以实现可追溯性
- 在装配过程中检查零部件上的零件号
OCR 仅在 OV80i 上可用。OV20i 和 OV10i 不支持 OCR。
OCR 工作原理
OV80i 使用两阶段 AI 流水线进行文本识别:
- 文本检测:在感兴趣区域内查找文本位置,返回每个检测到的单词或文本区域的边界框。
- 文本识别:读取每个检测到的边界框内的字符,并返回带有置信度分数的文本字符串。
整个处理过程在相机的 NVIDIA Jetson Orin NX GPU 上运行,无需云端连接。
该模型可识别广泛的字符集,包括:
- 数字 (0-9)
- 拉丁字母 (A-Z, a-z, 带重音字符)
- 常用标点和符号
- 希腊字母
- 货币符号
- 数学运算符
字符集是固定的,无法自定义。该模型支持约 480 个字符,涵盖了大多数基于拉丁语系的工业打印文本。
先决条件
在设置 OCR 之前,您需要一台已经满足以下条件的相机:
- 已物理安装并保持稳定
- 已连接到网络并可在浏览器中访问
- 已对焦于包含待读取文本的部件
如果尚未完成上述步骤,请先按照入门指南操作:
第一步:创建新程序
每次检测都始于一个程序。程序是一个完整的包:包含图像设置、对齐、感兴趣区域 (ROI)、AI 模型和输出规则。
- 在左侧边栏导航至 All Recipes
- 点击右上角的 + New
- 为程序起一个描述性的名称(例如 "Serial Number Check"、"Label Verification")
- 点击 激活 将其设为活动程序,然后点击 Edit 打开程序编辑器
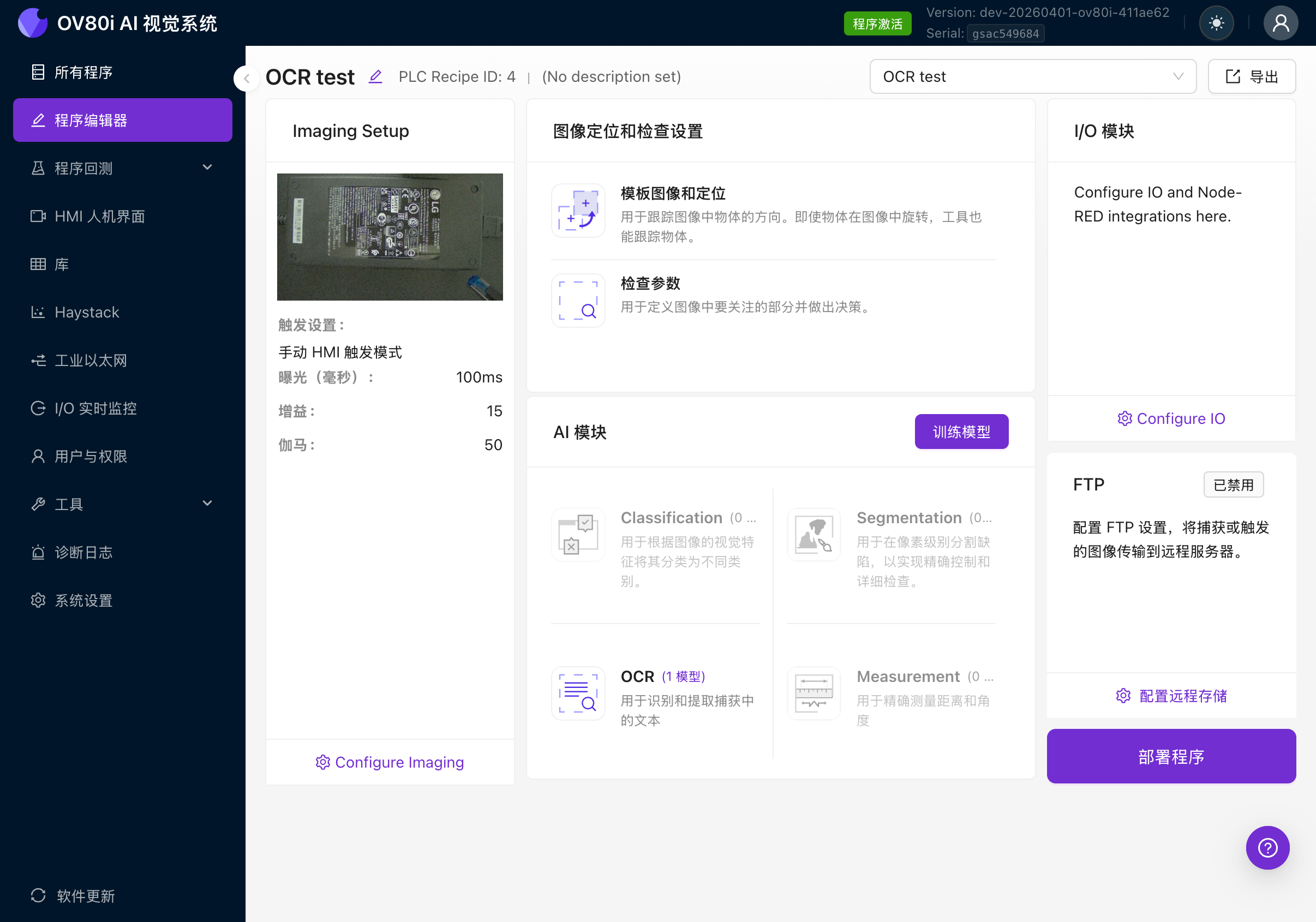
程序编辑器展示完整的检测流水线。您将从左到右依次操作:
- 图像设置(相机设置)
- Image Alignment & Inspection Setup(模板、ROI)
- AI模块(分类、分割、OCR、测量)
- Set Pass/Fail & IO Logic(输出规则)
有关创建程序的详细演练,请参阅 创建首次检测。
第二步:配置图像设置
良好的图像质量是 OCR 准确性的基础。文本必须清晰可见,且对比度强烈。
- 点击 Configure Imaging 或导航至 图像设置 选项卡
- 在观察实时预览的同时调整以下设置:
| 设置 | OCR 目标 |
|---|---|
| Exposure | 足够明亮以清晰看到所有文本。过暗会使字符消失在背景中;过亮会使白色标签过曝。 |
| Gain | 尽量保持低值。高增益会引入噪点,对检测器来说看起来就像文本伪影。 |
| Gamma | 调整以改善文本与背景之间的对比度。 |
| Focus | 文本必须清晰。如果字符看起来模糊不清,请调整 C-mount 镜头的对焦环。 |
OCR 准确性在很大程度上取决于图像质量。文本必须在相机图像中清晰可见,并与背景形成良好的对比。浅色背景上的深色文本或深色背景上的浅色文本均效果良好。请避免:
- 不均匀的光照在字符上产生阴影
- 光面标签上的眩光
- 曝光不足导致文本难以与背景区分
在实时预览中放大文本区域。您能清晰阅读每个字符吗?如果您都读不出来,AI 也无法识别。
有关所有成像设置的详细指南,请参阅 图像设置。
第三步:设置模板对齐
模板对齐告诉相机如何跟踪零件的位置和方向。这一步至关重要,因为零件并不总是落在传送带或夹具上的完全相同位置。
- 导航至 Template Image and Alignment 选项卡
- 将零件放置在相机的视野范围内
- 点击 Capture Template 拍摄参考图像
- 在始终存在且易于识别的特征上(例如,角点、徽标、安装孔)绘制 2-3 个小的模板区域
将模板区域尽可能放置在零件上相距较远的位置。这能显著减少对齐过程中的角度抖动。两个相距较近的区域会导致旋转稳定性较差;而位于对角线两端的两个区域则可提供出色的稳定性。
如果跳过对齐,您的 OCR ROI 将固定在绝对像素位置上。零件的任何移动都会导致 ROI 错过文本。生产使用时务必设置对齐。
有关模板对齐的详细指南,请参阅 对齐。
第四步:创建 OCR 感兴趣区域 (ROI)
现在您将精确定义相机应在零件的哪个位置查找文本。这是 OCR 准确性最重要的一步。
4a. 导航至 Inspection Setup
- 在程序编辑器中点击 Inspection Setup 选项卡
- 您将看到带有模板图像的 Inspection Editor
4b. 添加 OCR 模型
- 在右侧面板中,查找 Models 部分
- 如果未看到列出的 OCR 模型,请点击底部的 Add 按钮并选择 OCR
- OCR 模型将出现在 Models 列表中
每个程序只能有一个 OCR 模块。但是,您可以在该模块中创建多个 ROI,以读取零件不同区域的文本。
4c. 创建 OCR ROI
- 确保 OCR 模型行在 Models 列表中处于选中(高亮)状态
- 在 Region of Interest 部分点击 Add ROI
- 一个新的矩形 ROI 将出现在图像上
- 拖动 ROI 将其定位到您想要读取的文本上
- 通过拖动角点手柄调整其大小
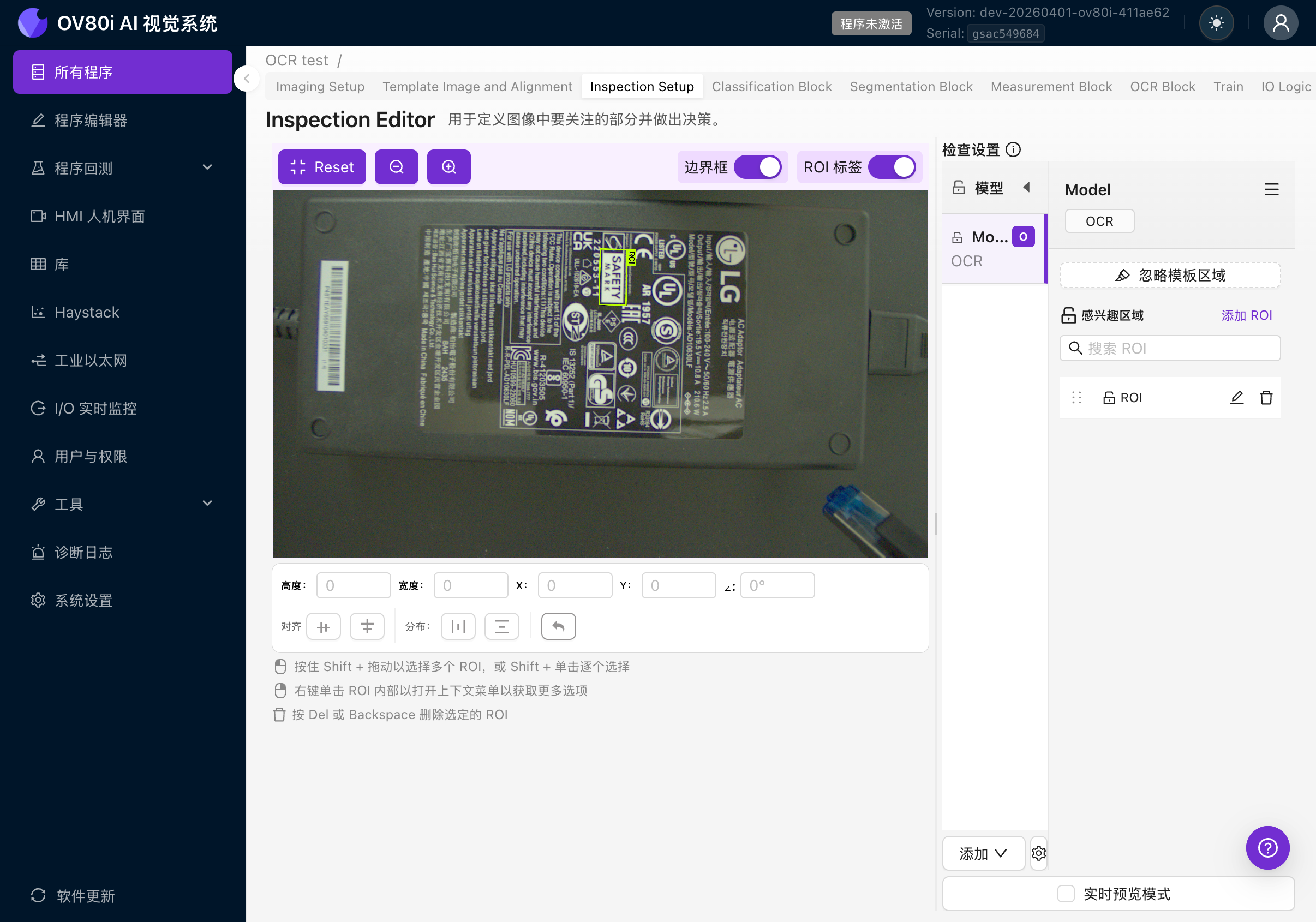
4d. 设置 ROI 方向
这是最重要的一点。您的 ROI 方向必须与您想要读取的文本方向相匹配。
OCR 引擎使用 ROI 的角度裁剪图像,然后将裁剪结果按文本水平方向进行处理。如果您的 ROI 角度与文本角度不匹配,引擎将尝试读取旋转后的文本并产生无意义的结果。
示例:
- 文本从左到右水平排列:ROI 角度应为 0 度
- 文本顺时针旋转 90 度:ROI 角度应为 90 度
- 文本上下颠倒:ROI 角度应为 180 度
- 文本呈 45 度角:ROI 角度应为 45 度
如何旋转 ROI:
- 点击 ROI 将其选中
- 使用 ROI 角点处的旋转手柄,或
- 直接在画布底部的位置字段中设置角度值
位置栏显示:H(高度)、W(宽度)、X 和 Y(位置),以及以度为单位的角度。
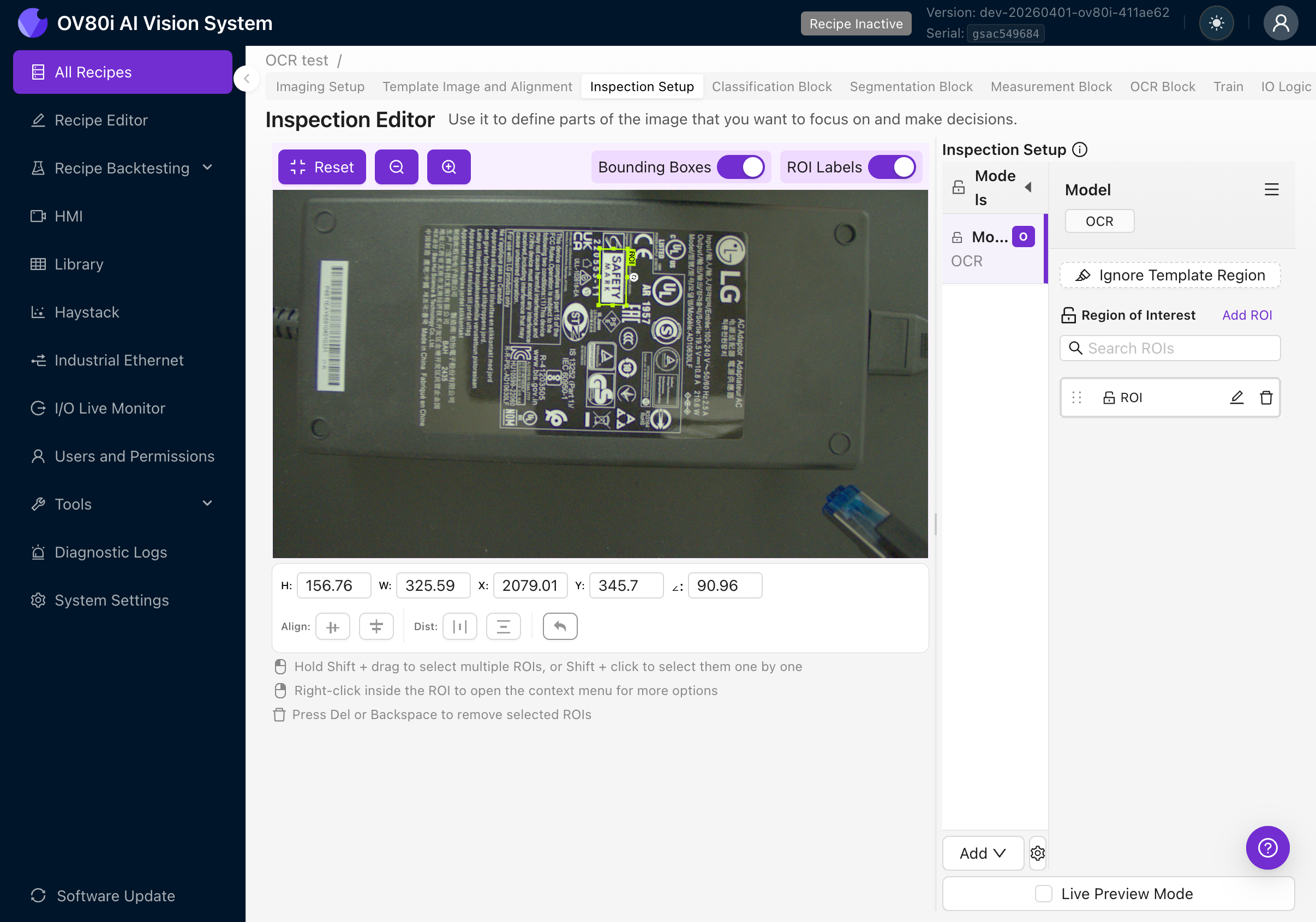
4e. 正确调整 ROI 大小
- 使 ROI 尽可能紧贴文本区域。多余的背景会引入噪声,并可能导致误检。
- 保留少量边距(10-20 像素),以避免字符在边缘被裁剪。
- 不要包含其他无需识别的文本。如果存在多个文本区域,请为每个区域创建单独的 ROI。
如果需要读取零件上多个区域的文本(例如序列号和日期代码),请为每个区域创建单独的 ROI。这样可以获得独立的结果,也使通过/失败规则更易于配置。
4f. 创建其他 ROI(可选)
为每个需要读取的文本区域重复步骤 4c-4e。每个 ROI 会在感兴趣区域列表中拥有自己的名称。双击名称可将其重命名为具有描述性的名称(例如 "Serial Number"、"Date Code"、"Part Label")。
使用复制粘贴可快速复制 ROI。名称会自动递增(例如 "ROI"、"ROI (1)"、"ROI (2)")。
第 5 步:配置和测试 OCR 模型
5a. 导航到 OCR 模型
点击程序编辑器选项卡栏中的 OCR Block 选项卡。左侧显示相机画面,右侧显示设置面板。
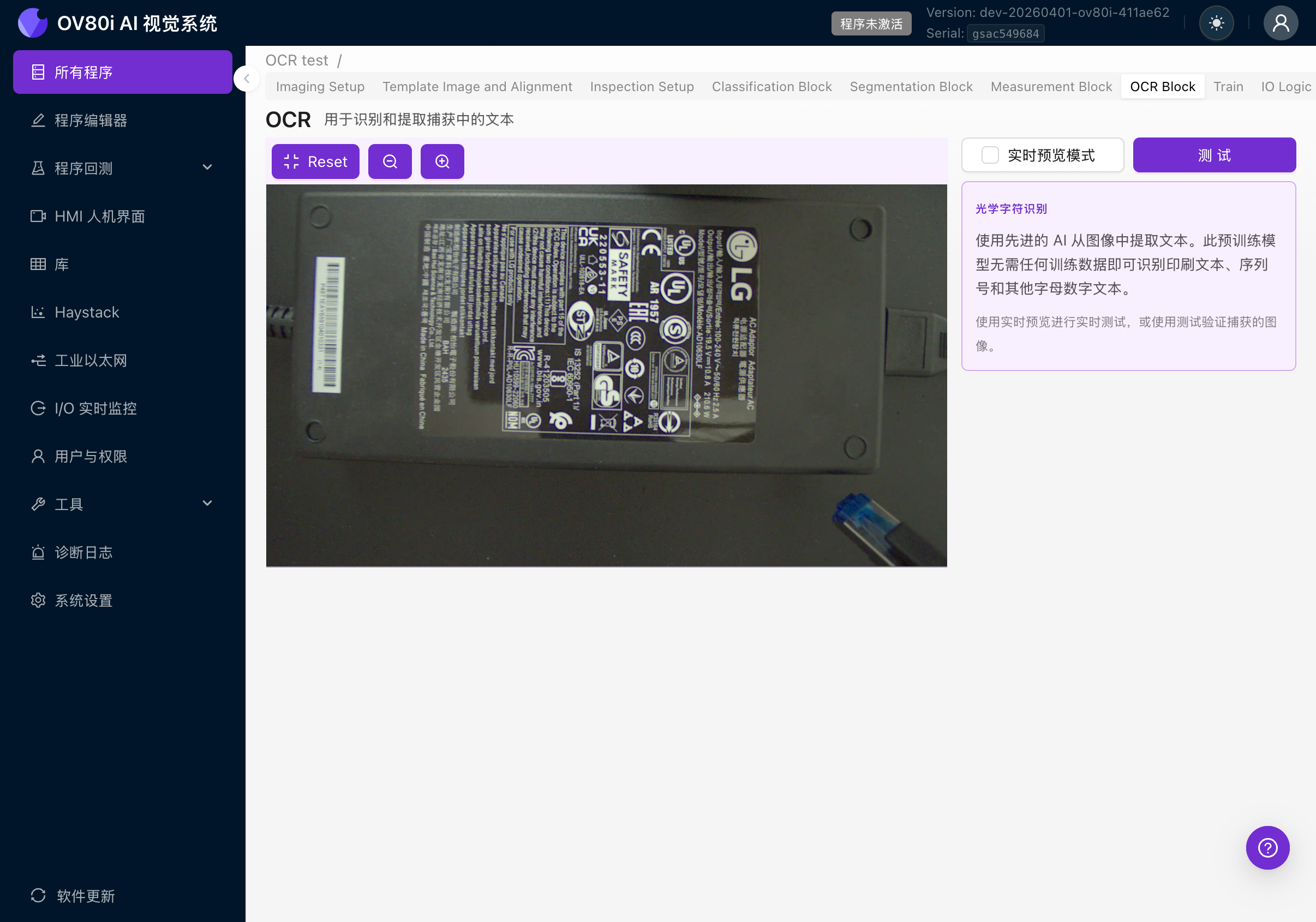
右侧面板显示:
- OPTICAL CHARACTER RECOGNITION 描述
- 说明这是一个预训练模型,无需训练数据
- 使用实时预览或测试进行验证的说明
5b. 启用实时预览
勾选右上角的 Live Preview Mode 复选框。相机将开始实时处理帧。
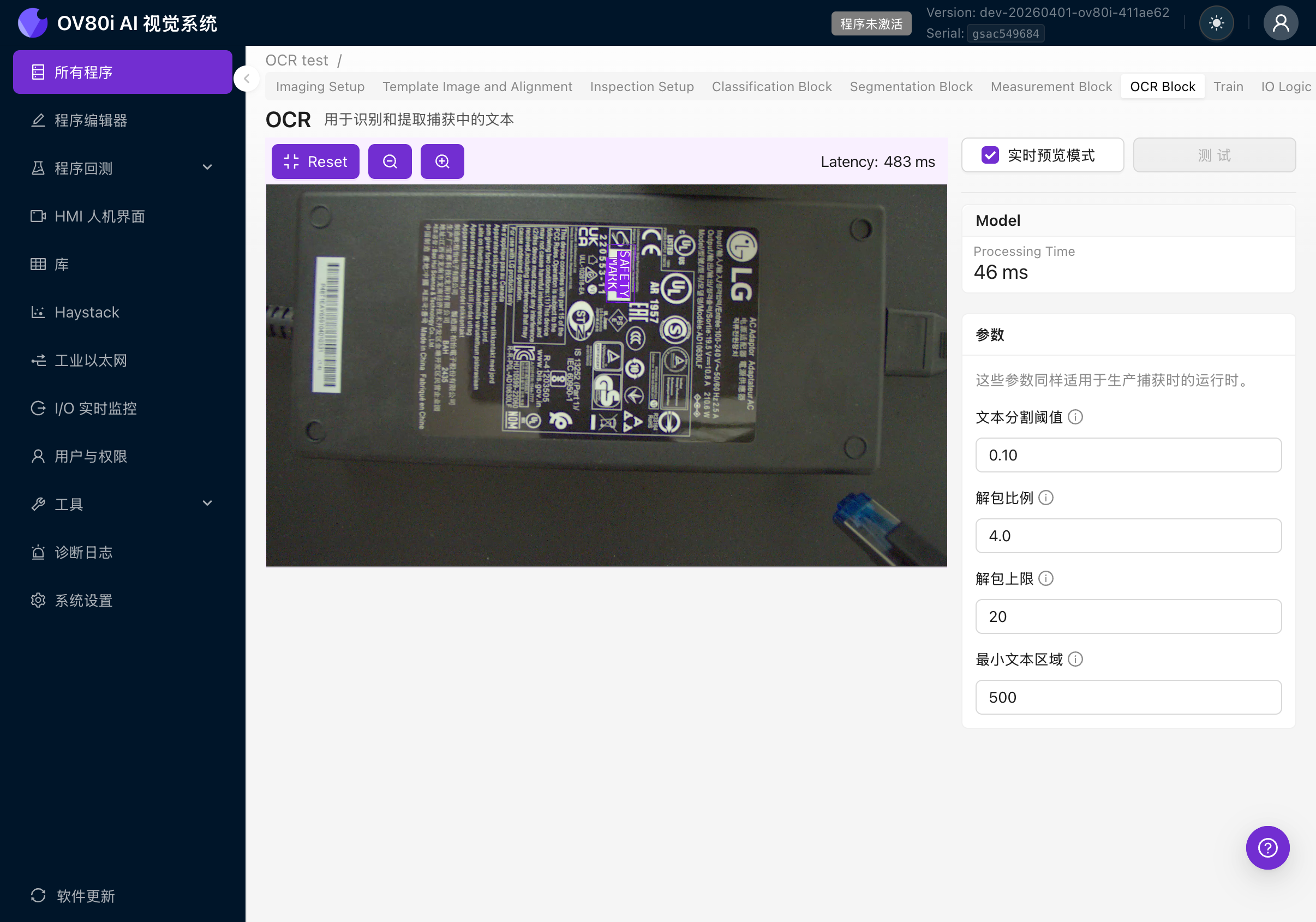
启用实时预览后,您将看到:
- Processing Time:OCR 模型每帧所需的处理时间
- Latency:包括图像捕获和渲染在内的总往返时间
- 紫色边界框叠加在相机画面上,标识检测到的文本区域
- 检测到的文本作为标签显示在每个边界框上
- 右侧的参数面板用于调整检测设置
5c. 验证 OCR 是否正确读取
启用实时预览后,将零件放置在相机下方并验证:
- 是否检测到所有文本区域? 您应该在 ROI 中的每个单词/短语周围看到紫色框。
- 文本是否被正确读取? 标签应与零件上的实际文本相匹配。
- 是否存在误检? 是否有非文本区域被错误地识别为文本?
- 轻微移动零件。 OCR 在不同位置是否仍能正常工作(这可测试对齐)?
如果文本未被检测到或读取错误,请检查:
- ROI 方向是否与文本方向一致(参见步骤 4d)
- ROI 是否正确定位在文本上方
- 图像质量是否良好(对焦清晰、对比度高、光照均匀)
- 尝试调整 OCR 参数(参见下一节)
第 6 步:调整 OCR 参数
启用实时预览后,右侧面板会显示四个可调参数。它们控制文本检测阶段(查找文本所在位置),而不是识别阶段(读取文本内容)。
| 参数 | 默认值 | 作用 |
|---|---|---|
| Text Segmentation Threshold | 0.10 | 检测器对某区域包含文本的置信度要求。值越高 = 检测越严格,误报越少但可能漏掉模糊文本。值越低 = 越灵敏,能捕捉模糊文本但可能产生误检。范围:0.0 到 1.0。 |
| Unclip Ratio | 4.0 | 从文本轮廓向外扩展检测边界框的程度。值越高 = 边界框越大。如果边界框裁剪到大字符的边缘,请增大此值。如果相邻单词合并到同一个框中,请减小此值。 |
| Unclip Ceiling | 20 | 扩展时的最大像素数。该值限制扩展幅度,使大文本上的高比率扩展不会生成过大的框。如果大文本在增大 Unclip Ratio 后仍被裁剪,请提高此值。 |
| Min Text Area | 500 | 检测到的文本区域的最小面积(以像素为单位)。小于此值的内容会被作为噪声丢弃。如果小的伪影被检测为文本,请增大此值。如果小但有效的文本被过滤掉,请减小此值。 |
从默认值开始。仅在实时预览中看到具体问题时才进行调整:
| 问题 | 要调整的参数 | 方向 |
|---|---|---|
| 非文本区域被检测为文本 | Text Segmentation Threshold | 增大 |
| 有效文本被漏检 | Text Segmentation Threshold | 减小 |
| 边界框裁剪到字符边缘 | Unclip Ratio | 增大 |
| 相邻单词合并到同一个框中 | Unclip Ratio | 减小 |
| 大文本上的框过大 | Unclip Ceiling | 减小 |
| 增大 Unclip Ratio 后大文本仍被裁剪 | Unclip Ceiling | 增大 |
| 噪声/伪影被检测为文本 | Min Text Area | 增大 |
| 小的有效文本被过滤掉 | Min Text Area | 减小 |
参数更改会在实时预览中立即生效,因此您可以迭代调整。这些参数不仅在预览期间有效,在生产捕获期间同样适用。
第七步:使用捕获的图像进行测试
通过实时预览调整参数后,请使用一系列生产样品验证 OCR。
7a. 使用测试面板
- 禁用实时预览模式(取消选中复选框)
- 点击 Test 按钮
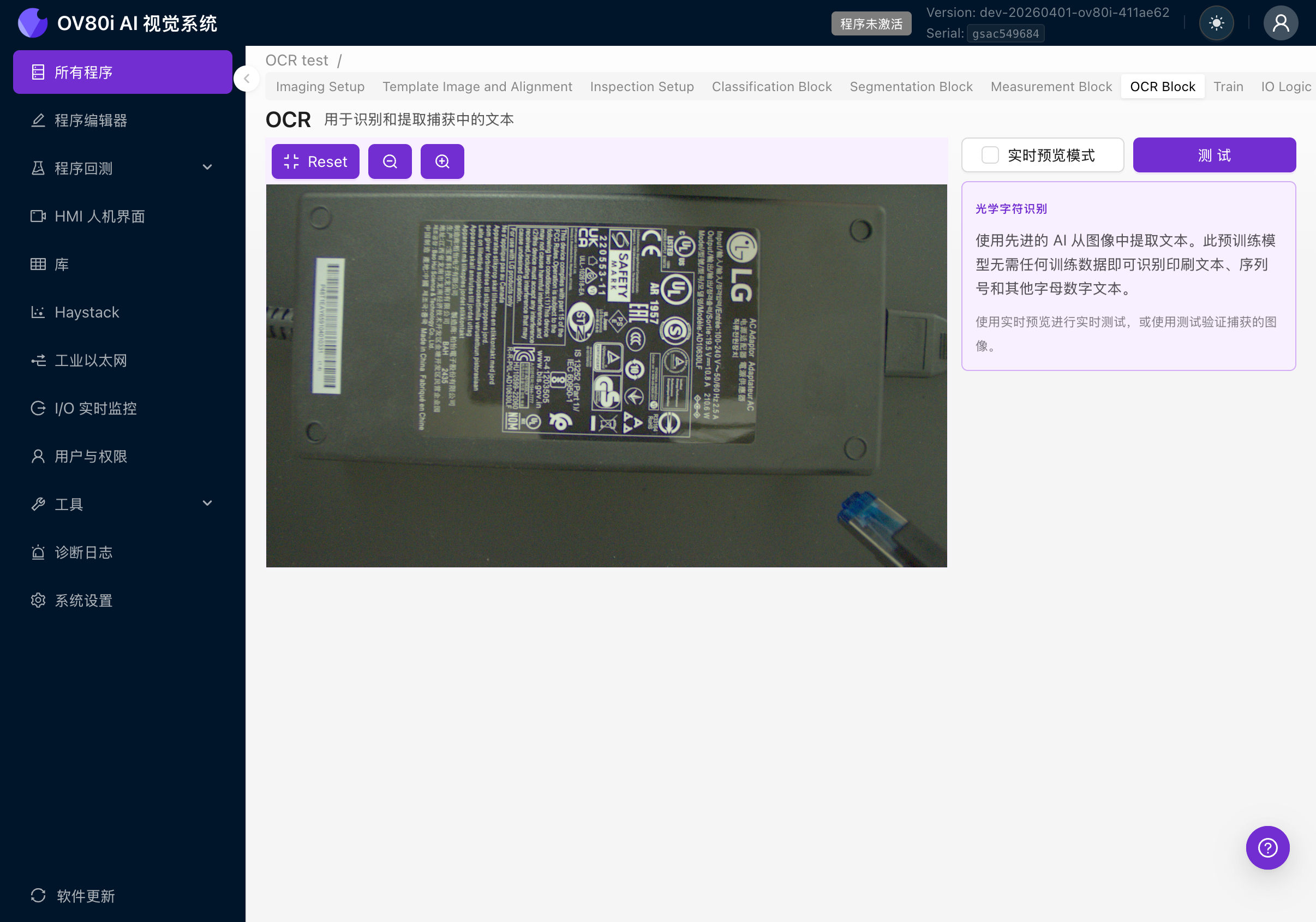
- 点击 Select From Library 从之前捕获的检测中选择图像,或点击 Upload Captures 从计算机上传图像
- 每个 ROI 的测试结果显示:
- Detected Text(以等宽/代码格式显示)
- Confidence(颜色编码标签:绿色高于 80%,橙色高于 50%,红色低于 50%)
- Detection Count(找到的文本区域数量)
7b. 需要关注的内容
- 一致性:对于相同的零件,OCR 每次读取的文本是否相同?
- 准确性:检测到的字符串是否与零件上的实际文本一致?
- 置信度分数:是否一直高于 80%?低置信度通常表示图像质量问题。
- 边缘案例:使用文本被涂污、褪色或部分遮挡的零件进行测试。
如果置信度分数持续低于 80%,请重新检查图像设置(第二步)。OCR 准确性与图像质量直接相关。任何参数调优都无法弥补模糊或光照不佳的图像。
第八步:设置通过/失败规则(IO 逻辑)
OCR 正确检测文本后,需要定义什么构成 pass 或 fail。导航至 IO Logic 选项卡。
基本模式
基本模式提供简单的基于规则的 UI 用于 OCR 通过/失败逻辑。无需 Node-RED 知识。
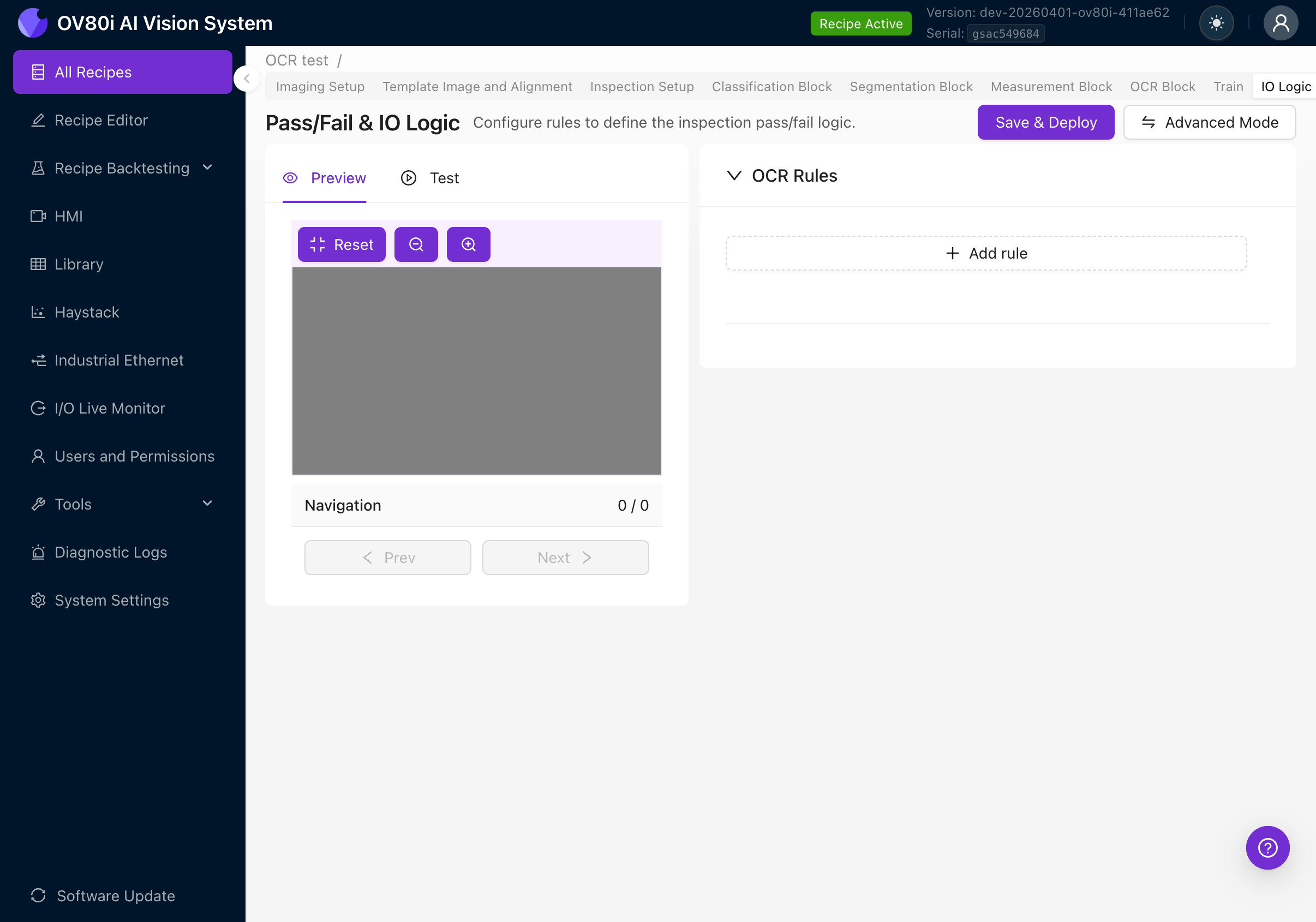
页面显示:
- 左侧的 Preview / Test 选项卡(用于根据规则可视化结果)
- 右侧的 OCR Rules 部分
- 用于激活规则的 Save & Deploy 按钮
- 切换到 Node-RED 的 Advanced Mode 按钮
创建规则
点击 + Add rule 创建通过/失败规则。每条规则有三个字段:
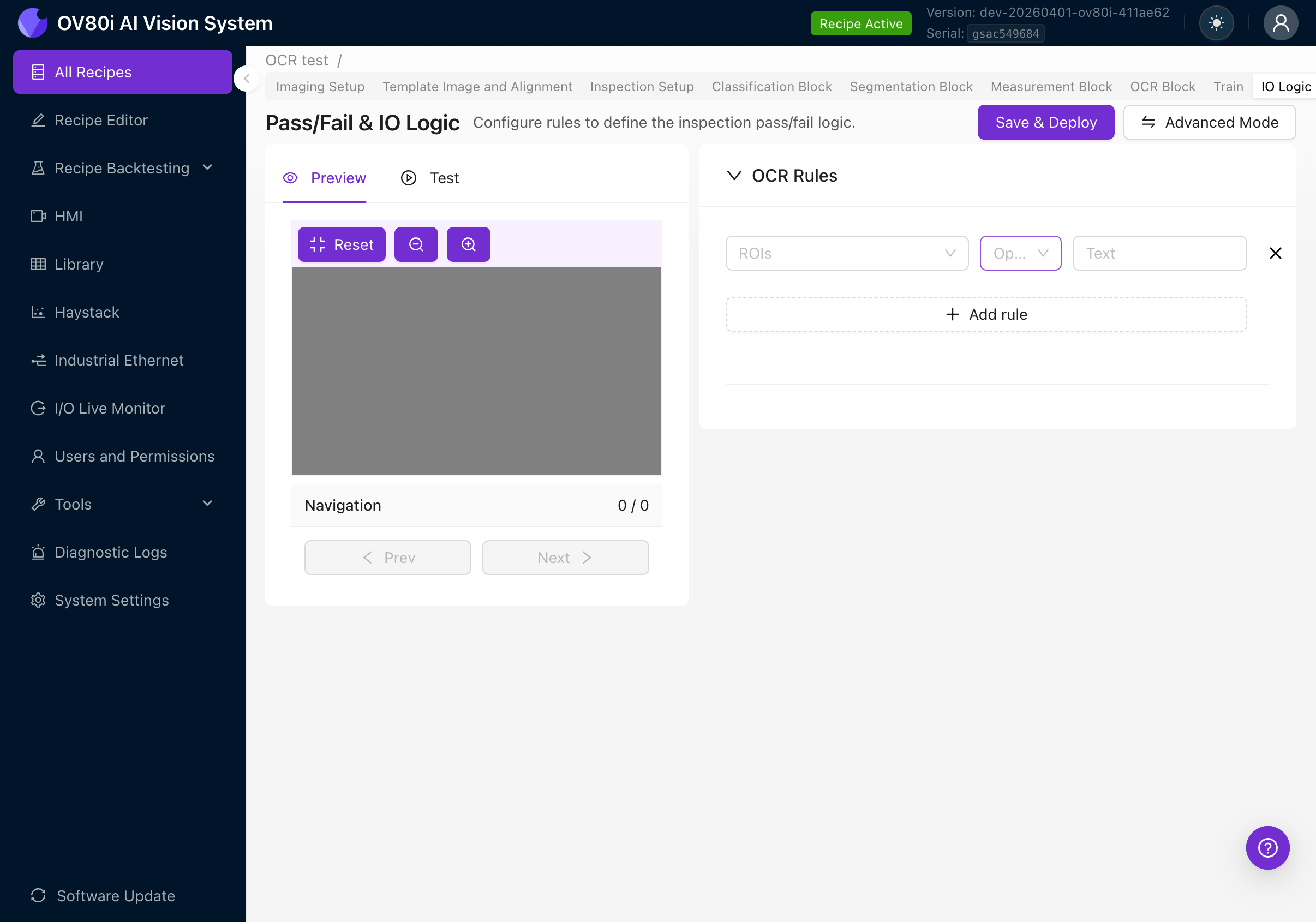
| 字段 | 描述 |
|---|---|
| ROIs | 要评估的 ROI。点击展开并选择 "All ROIs" 或指定特定区域。 |
| Operator | 对检测到的文本执行的比较。 |
| Text | 要比较的预期文本字符串。 |
可用运算符
点击 Operator 下拉菜单查看所有四个选项:
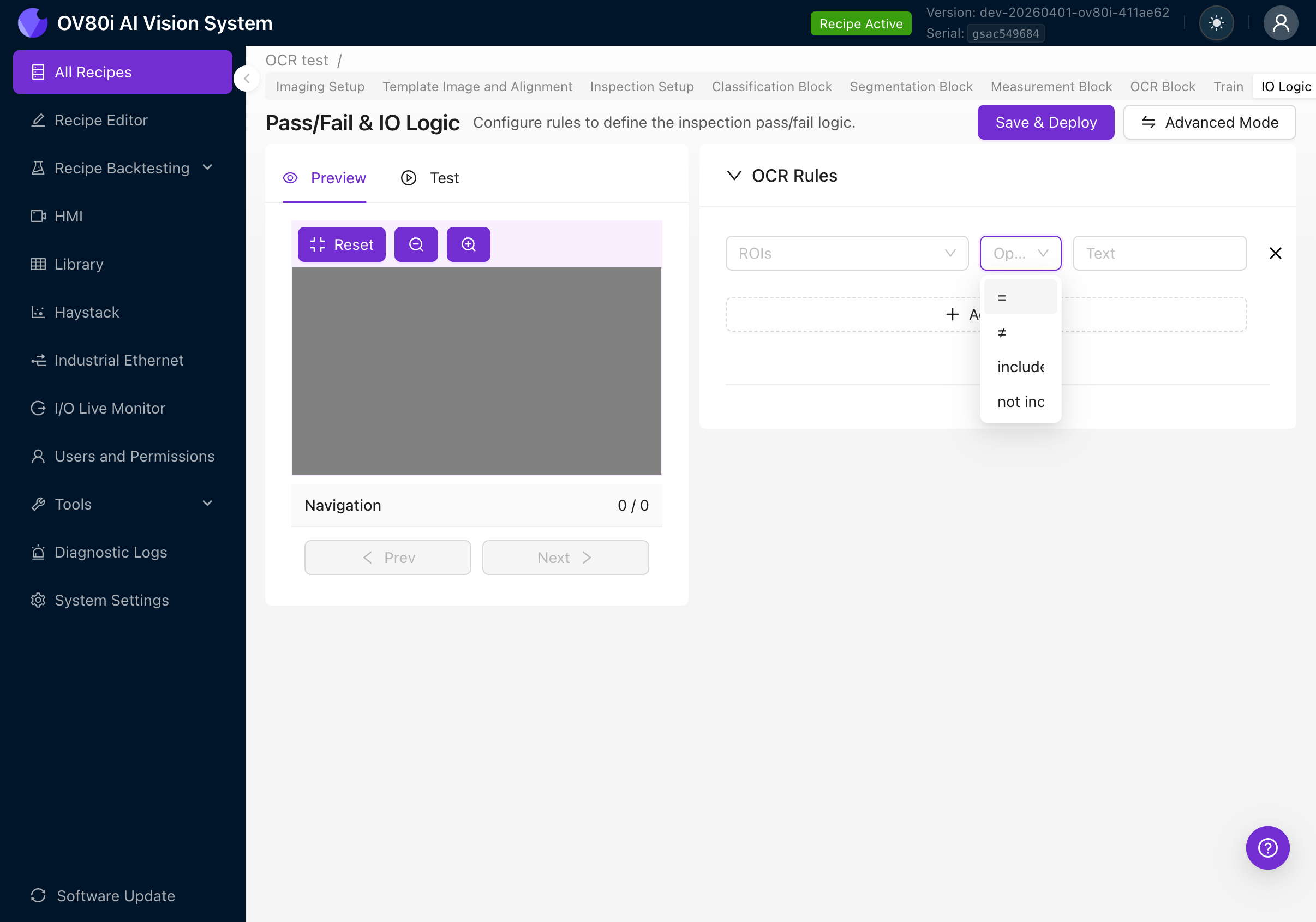
| 运算符 | 行为 | 示例用例 |
|---|---|---|
| = (equals) | 所有检测到的文本连接后必须与预期文本完全匹配 | 验证序列号读取结果恰好为 "SN-2025-0042" |
| != (not equals) | 连接后的文本必须不匹配预期文本 | 拒绝带有已知错误代码的零件 |
| includes | 连接后的文本必须包含预期文本作为子字符串 | 检查标签中某处包含 "SAFETY" 一词 |
| not includes | 连接后的文本必须不包含预期文本 | 确保已弃用的产品代码未出现 |
文本比较方式
当一个 ROI 包含多个检测到的文本区域时(例如,检测器将 "LOT" 和 "2025" 识别为单独的单词),所有独立的文本字符串将在比较前用空格拼接。
因此,如果检测器发现三个文本区域分别读取为 "LOT"、"2025" 和 "A1",拼接后的文本即为 "LOT 2025 A1"。您的规则将与此完整拼接字符串进行比较。
这意味着:
- 针对
"LOT 2025 A1"的 equals 规则将通过 - 针对
"2025"的 includes 规则将通过 - 仅针对
"LOT"的 equals 规则将失败(因为拼接后的文本包含的内容不止 "LOT")
多条规则
您可以通过再次点击 + Add rule 来添加多条规则。所有规则均采用 AND 逻辑:每条规则都必须通过,OCR 检查才会通过。如果任何一条规则失败,整个检测都会失败。
ROI 选择
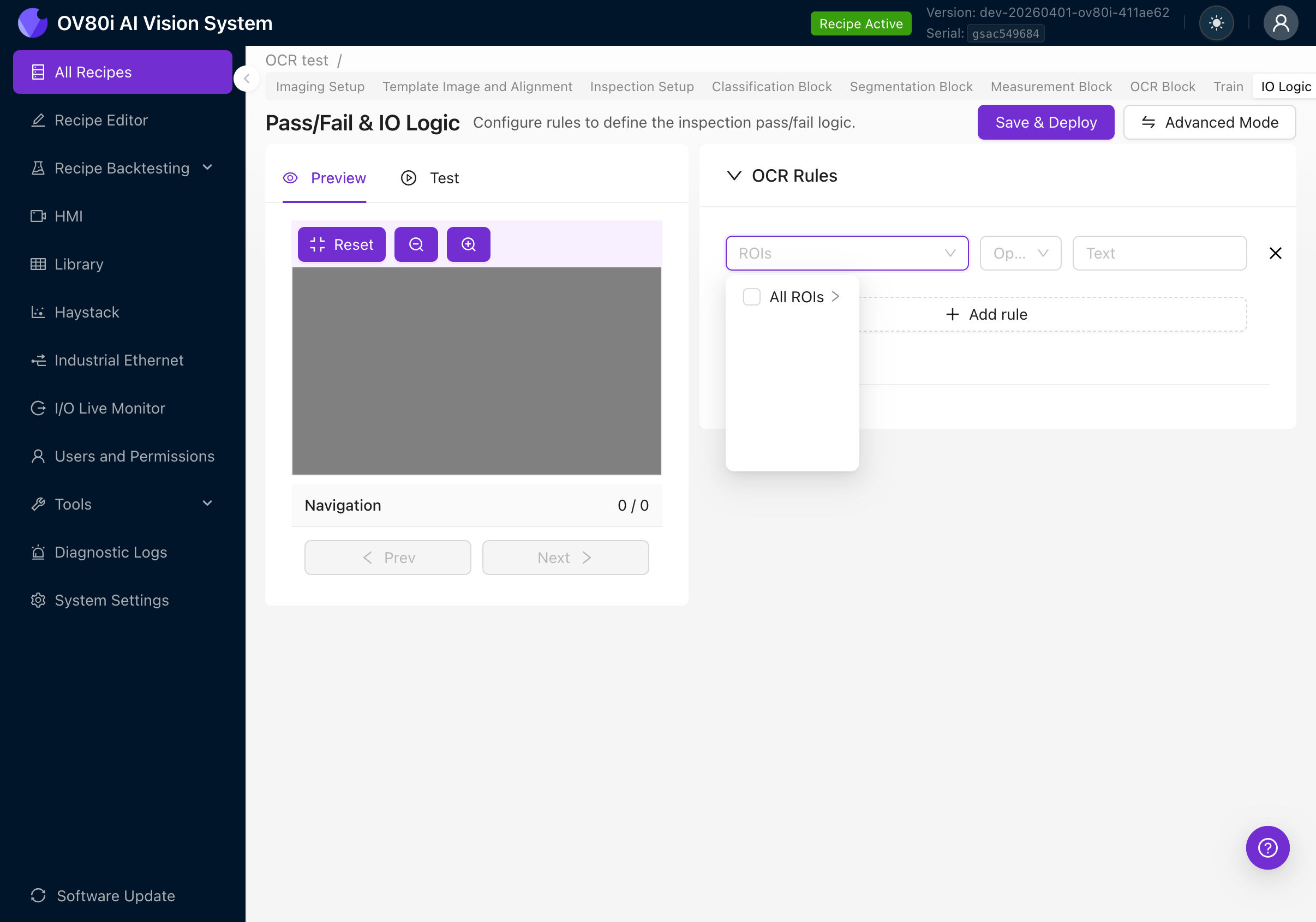
点击 ROIs 下拉菜单,选择该规则应用于哪个(哪些)区域:
- All ROIs:该规则评估所有 OCR 区域合并后的文本
- Specific ROI:展开以按名称选择单个 ROI(这就是为什么在第 4f 步中以描述性方式命名您的 ROI 很重要)
保存并部署
配置好规则后,点击 Save & Deploy 以激活它们。规则将立即对后续所有检测生效。
高级模式 (Node-RED)
对于基础模式无法处理的更复杂的 pass/fail 逻辑,请切换到高级模式。
点击 Advanced Mode 按钮,将显示一个确认对话框:
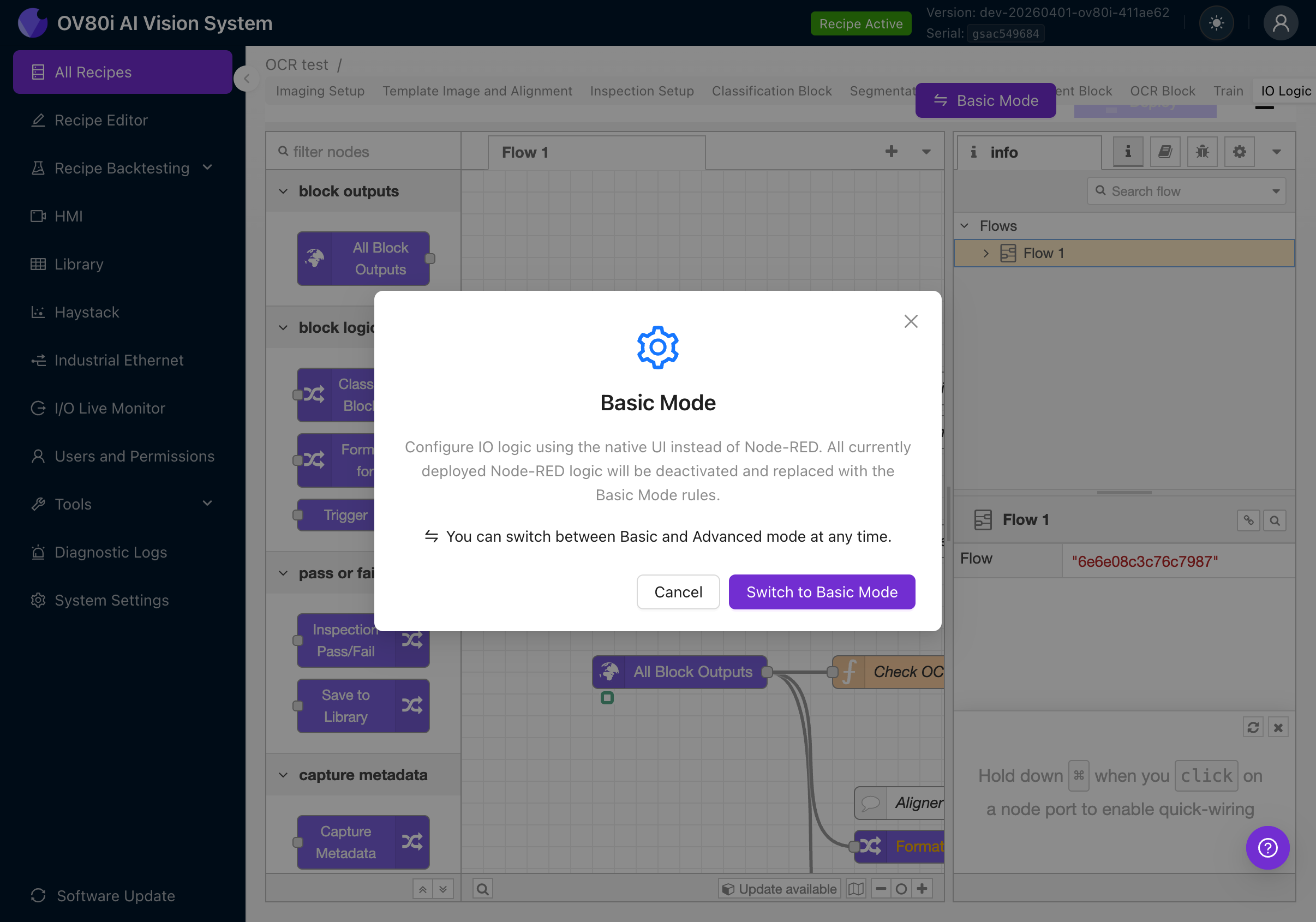
该对话框说明:
- 高级模式使用完整的 Node-RED 可视化编程环境
- 任何基础模式的规则都将被停用
- 您可以随时切换回基础模式
点击 Switch to Advanced Mode(如果您已处于高级模式,按钮将显示为 Basic Mode)。
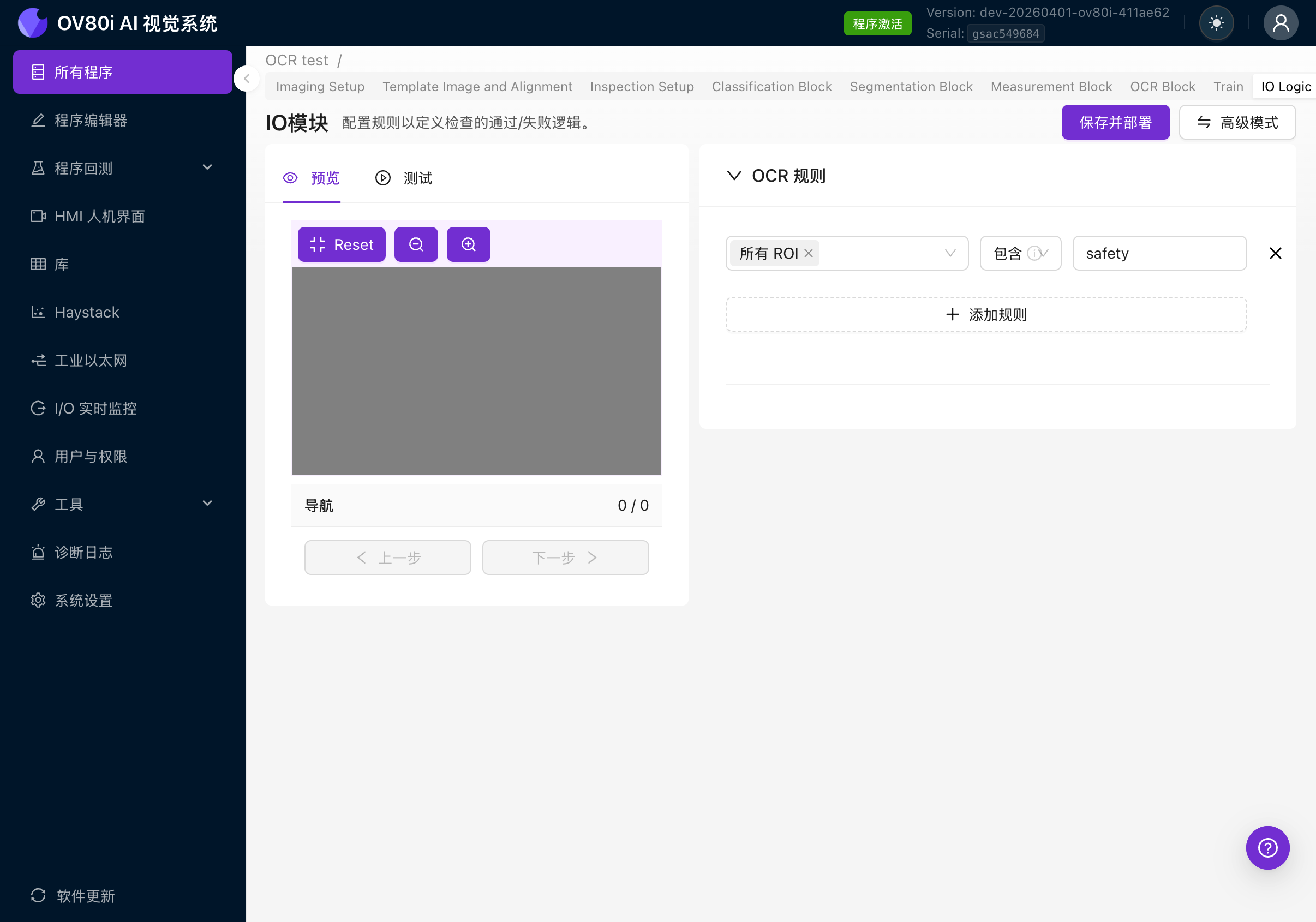
在高级模式下,您将看到一个 Node-RED 流程画布,其中包含预构建的节点,包括:
- All Block Outputs:接收来自所有 AI 模块的结果(分类、分割、OCR、测量)
- Check OCR(或类似节点):一个包含用于评估 OCR 结果的 JavaScript 的函数节点
- Classification Block Logic / Format Data for PLC / Trigger:用于集成的其他输出节点
- Inspection Pass/Fail:最终的通过/失败判定
- Save to Library:存储结果
Node-RED 中的 OCR 输出 Payload
在高级模式下,OCR 结果可在 msg.payload.ocr 对象中获取。这让您可以通过编程方式完整访问每个检测结果:
{
"predictions": [
{
"roi_id": 1,
"roi_name": "Serial Number",
"center_x_global": 450,
"center_y_global": 220,
"angle_global": 90,
"search_area_id": 1,
"detections": [
{
"text": "SN-2025-0042",
"confidence": 0.95,
"roi_bbox": {
"x": 10,
"y": 5,
"width": 120,
"height": 30,
"angle": 0
},
"global_bbox": {
"x": 450,
"y": 220,
"width": 120,
"height": 30,
"angle": 90
}
}
]
}
]
}
| 字段 | 说明 |
|---|---|
| roi_id | 产生此结果的 ROI 的数字 ID |
| roi_name | 您为 ROI 指定的名称(例如,"Serial Number") |
| center_x_global / center_y_global | ROI 在整帧坐标系中的中心位置 |
| angle_global | ROI 在整帧中的旋转角度 |
| search_area_id | 此 ROI 所属的检测类型 / 搜索区域 |
| detections | 在此 ROI 中找到的单个文本检测的数组 |
| detections[].text | 识别出的文本字符串 |
| detections[].confidence | 识别置信度,范围从 0.0 到 1.0(已限定区间) |
| detections[].roi_bbox | 相对于 ROI 裁剪原点的边界框位置 |
| detections[].global_bbox | 整个相机画面中的边界框位置(考虑了 ROI 旋转和对齐) |
使用 msg.payload.ocr.predictions[0].detections.map(d => d.text).join(" ") 即可获得与基础模式比较时所用相同的拼接文本字符串。
通过高级模式,您可以:
- 使用 JavaScript 对检测到的文本应用正则表达式模式
- 按置信度阈值过滤检测结果
- 将 OCR 结果与分类/分割结果结合用于复杂逻辑
- 为 PLC 输出格式化 OCR 文本(例如,通过 EtherNet/IP 发送检测到的序列号)
- 根据 OCR 内容向 Microsoft Teams 或电子邮件发送自定义消息
有关 Node-RED 的详细指南,请参阅 Node-RED Basics。
您可以随时使用 IO 逻辑 页面顶部的切换按钮在基础模式和高级模式之间切换。切换到基础模式时,任何已部署的 Node-RED 逻辑都将被停用,并被基础模式的规则替换。切换回高级模式时,Node-RED 流程将被恢复。
第 9 步:部署程序
完成 OCR 设置和测试后:
- 返回 程序编辑器(点击左侧边栏中的 程序编辑器)
- 点击右下角紫色的 部署程序 按钮
- 程序现已激活并正在运行检测
查看结果
HMI
HMI 页面显示实时检测结果。OCR 激活后,您将看到:
- 实时相机画面,检测到的文本周围带有紫色边界框
- 显示读取内容的文本标签
- 基于 IO 逻辑规则的通过/失败状态
- 运行统计信息:检测总数、通过数、失败数、良品率百分比
库
点击左侧边栏中的 库 可查看过往捕获的存储结果。每个捕获条目显示:
- 带有 OCR 叠加层的捕获图像
- 每个 ROI 的检测文本
- 置信度分数
- 通过/失败结果
故障排除
未检测到文本
| 可能原因 | 解决方法 |
|---|---|
| ROI 未定位在文本上 | 在检测设置中重新定位 ROI |
| ROI 方向与文本不匹配 | 旋转 ROI 以与文本方向对齐(第 4d 步) |
| 图像中文本过小 | 将相机移近或使用更长焦距的镜头 |
| 文本相对于 ROI 过小 | 使 ROI 更紧贴文本区域 |
| Min Text Area 过高 | 降低 Min Text Area 参数 |
| 光照不佳 / 对比度低 | 改善光照以最大化文本与背景之间的对比度 |
| 文本模糊 | 调整 C-mount 镜头的对焦并确认相机安装稳固 |
| 未设置对齐 | 文本检测需要对齐。设置模板对齐(第 3 步) |
检测到错误文本(误读)
| 可能原因 | 解决方法 |
|---|---|
| ROI 方向与文本方向不匹配 | 这是首要原因。旋转 ROI 以与文本方向对齐(第 4d 步) |
| 图像质量差或存在噪声 | 增加曝光、降低增益、改善光照 |
| Text Segmentation Threshold 过低 | 提高该值以过滤误检测的文本 |
| 重叠的文本区域合并为单个检测 | 降低 Unclip Ratio 以防止框合并 |
| 一个 ROI 中包含多行文本 | 如果读取顺序重要,请为每行创建单独的 ROI |
OCR 置信度持续偏低
| 可能原因 | 解决方法 |
|---|---|
| 光照均匀性差 | 确保文本区域光照均匀 |
| 文本上有眩光或反射(尤其是光面标签) | 调整光照角度以消除镜面反射。考虑使用漫射光照。 |
| 字体非常小或样式过于风格化 | 将相机移近或使用更长焦距的镜头以增大图像中的文本尺寸 |
| 文本损坏、褪色或部分印刷 | OCR 只能读取相机看到的内容。如果文本物理上已退化,准确度会降低。 |
| 图像设置中增益过高 | 降低增益。高增益会引入看起来像文本伪影的噪声。 |
通过/失败规则未按预期工作
| 可能原因 | 解决方法 |
|---|---|
| 文本拼接方式与预期不同 | 启用实时预览并检查确切检测到的文本。请记住,多个检测结果使用空格连接。 |
| 在应使用 "includes" 时使用了 "equals" | 如果您只关心子字符串,请使用 "includes" 而非 "equals" |
| 规则未部署 | 在 Basic Mode 中更改规则后,点击 Save & Deploy |
| 规则中选择了错误的 ROI | 检查规则中的 ROIs 下拉菜单,确保其目标为正确的区域 |
限制
- 每个程序最多 1 个 OCR 模型(该模型内可包含多个 ROI)
- 仅针对英文优化的模型:预训练模型针对基于拉丁字母的印刷文本进行了优化。不支持手写体、草书或非拉丁文字(中文、日文、韩文、阿拉伯文)。
- 基本模式下不支持正则表达式或模式匹配:通过/失败规则使用简单的字符串比较(等于、不等于、包含、不包含)。对于复杂的验证模式(例如,匹配 "SN-####-####"),请使用高级模式(Node-RED)配合自定义 JavaScript 正则表达式。
- 无用户可配置的字符集:模型的 480 字符字典是固定的。例如,您无法将识别限制为仅数字。请使用通过/失败规则来验证预期格式。
- 不保证文本顺序:当在一个 ROI 内检测到多个文本区域时,它们将按检测顺序(按轮廓)连接,不一定按阅读顺序(从左到右、从上到下)。如果阅读顺序很重要,请为每行文本使用单独的 ROI。
- 仅预训练模型:与分类和分割不同,OCR 模型无法针对您的特定字体或文本样式进行重新训练或微调。它使用内置的预训练 OCR 模型。
另请参阅
- 创建首个检测 - 完整的程序创建演练
- 图像设置 - 详细的图像设置指南
- 对齐 - 模板对齐深入讲解
- 感兴趣区域 (ROI) - ROI 尺寸与策略
- 检测设置与 ROI 类型 - ROI 类型参考
- Node-RED 基础 - 高级 IO 逻辑编程
- 图像设置基础 - 照明与图像质量理论