AI 驅動文件
您想了解什麼?
OCR (Optical Character Recognition)
OV80i 可以使用預訓練的 OCR 模型,直接從相機影象中讀取列印的文字、序列號、日期程式碼及其他字母數字字元。與分類器和分割器不同,OCR 無需訓練資料,開箱即用。
OCR 適用於以下場景:
- 驗證序列號或批號程式碼是否與預期值匹配
- 確認標籤存在且可讀
- 讀取日期/有效期程式碼以實現可追溯性
- 在裝配過程中檢查零部件上的零件號
OCR 僅在 OV80i 上可用。OV20i 和 OV10i 不支援 OCR。
OCR 工作原理
OV80i 使用兩階段 AI 流水線進行文字識別:
- 文字檢測:在感興趣區域內查詢文字位置,返回每個檢測到的單詞或文字區域的邊界框。
- 文字識別:讀取每個檢測到的邊界框內的字元,並返回帶有置信度分數的文字字串。
整個處理過程在相機的 NVIDIA Jetson Orin NX GPU 上執行,無需雲端連線。
該模型可識別廣泛的字符集,包括:
- 數字 (0-9)
- 拉丁字母 (A-Z, a-z, 帶重音字元)
- 常用標點和符號
- 希臘字母
- 貨幣符號
- 數學運算子
字符集是固定的,無法自定義。該模型支援約 480 個字元,涵蓋了大多數基於拉丁語系的工業列印文字。
先決條件
在設定 OCR 之前,您需要一臺已經滿足以下條件的相機:
- 已物理安裝並保持穩定
- 已連線到網路並可在瀏覽器中訪問
- 已對焦於包含待讀取文字的部件
如果尚未完成上述步驟,請先按照入門指南操作:
第一步:建立新程式
每次檢測都始於一個程式。程式是一個完整的包:包含影象設定、對齊、感興趣區域 (ROI)、AI 模型和輸出規則。
- 在左側邊欄導航至 All Recipes
- 點選右上角的 + New
- 為程式起一個描述性的名稱(例如 "Serial Number Check"、"Label Verification")
- 點選 啟用 將其設為活動程式,然後點選 Edit 開啟程式編輯器
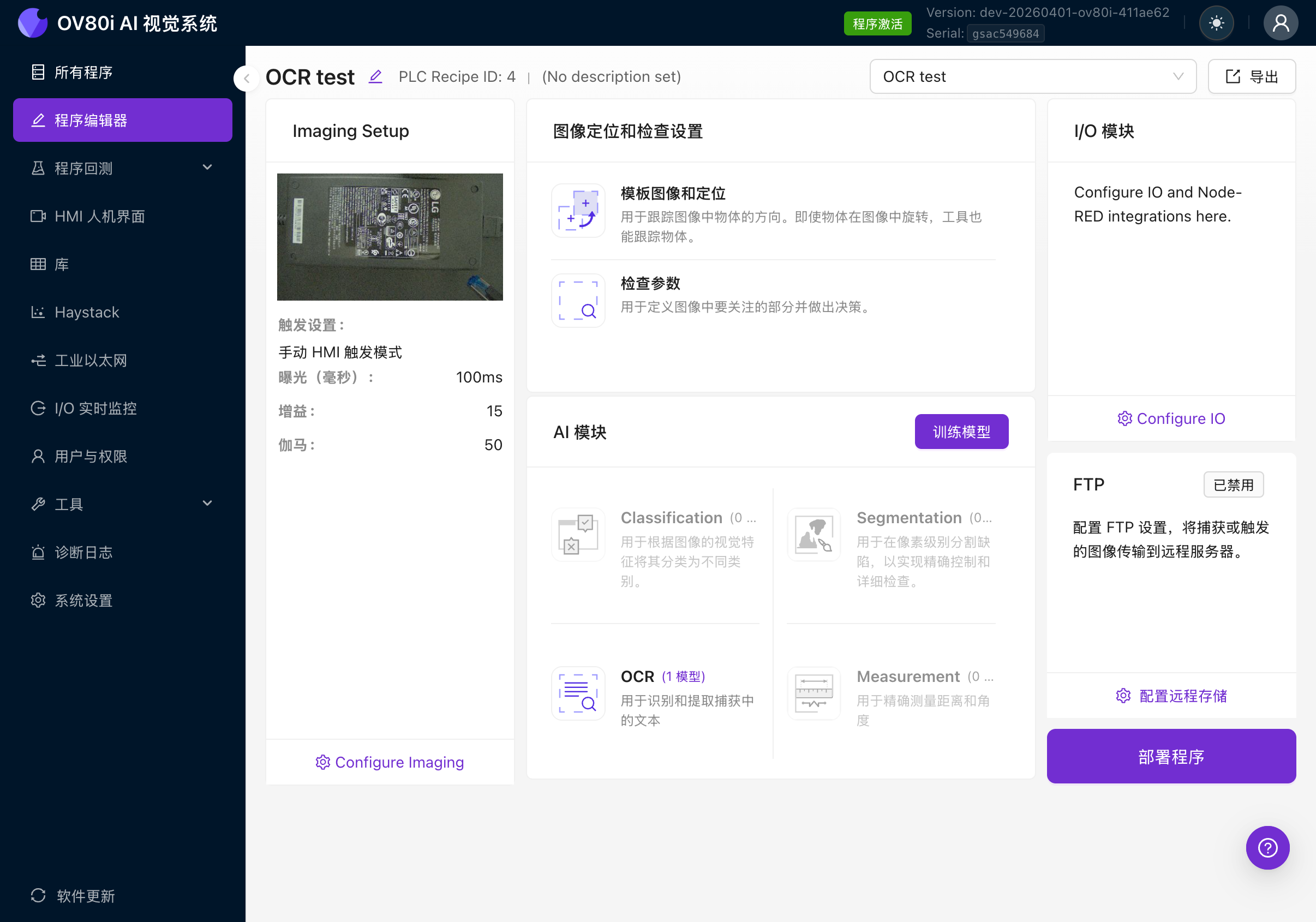
程式編輯器展示完整的檢測流水線。您將從左到右依次操作:
- 影象設定(相機設定)
- Image Alignment & Inspection Setup(模板、ROI)
- AI模組(分類、分割、OCR、測量)
- Set Pass/Fail & IO Logic(輸出規則)
有關建立程式的詳細演練,請參閱 建立首次檢測。
第二步:配置影象設定
良好的影象質量是 OCR 準確性的基礎。文字必須清晰可見,且對比度強烈。
- 點選 Configure Imaging 或導航至 影象設定 選項卡
- 在觀察實時預覽的同時調整以下設定:
| 設定 | OCR 目標 |
|---|---|
| Exposure | 足夠明亮以清晰看到所有文字。過暗會使字元消失在背景中;過亮會使白色標籤過曝。 |
| Gain | 儘量保持低值。高增益會引入噪點,對檢測器來說看起來就像文字偽影。 |
| Gamma | 調整以改善文字與背景之間的對比度。 |
| Focus | 文字必須清晰。如果字元看起來模糊不清,請調整 C-mount 鏡頭的對焦環。 |
OCR 準確性在很大程度上取決於影象質量。文字必須在相機影象中清晰可見,並與背景形成良好的對比。淺色背景上的深色文字或深色背景上的淺色文字均效果良好。請避免:
- 不均勻的光照在字元上產生陰影
- 光面標籤上的眩光
- 曝光不足導致文字難以與背景區分
在實時預覽中放大文字區域。您能清晰閱讀每個字元嗎?如果您都讀不出來,AI 也無法識別。
有關所有成像設定的詳細指南,請參閱 影象設定。
第三步:設定模板對齊
模板對齊告訴相機如何跟蹤零件的位置和方向。這一步至關重要,因為零件並不總是落在傳送帶或夾具上的完全相同位置。
- 導航至 Template Image and Alignment 選項卡
- 將零件放置在相機的視野範圍內
- 點選 Capture Template 拍攝參考影象
- 在始終存在且易於識別的特徵上(例如,角點、徽標、安裝孔)繪製 2-3 個小的模板區域
將模板區域儘可能放置在零件上相距較遠的位置。這能顯著減少對齊過程中的角度抖動。兩個相距較近的區域會導致旋轉穩定性較差;而位於對角線兩端的兩個區域則可提供出色的穩定性。
如果跳過對齊,您的 OCR ROI 將固定在絕對畫素位置上。零件的任何移動都會導致 ROI 錯過文字。生產使用時務必設定對齊。
有關模板對齊的詳細指南,請參閱 對齊。
第四步:建立 OCR 感興趣區域 (ROI)
現在您將精確定義相機應在零件的哪個位置查詢文字。這是 OCR 準確性最重要的一步。
4a. 導航至 Inspection Setup
- 在程式編輯器中點選 Inspection Setup 選項卡
- 您將看到帶有模板影象的 Inspection Editor
4b. 新增 OCR 模型
- 在右側面板中,查詢 Models 部分
- 如果未看到列出的 OCR 模型,請點選底部的 Add 按鈕並選擇 OCR
- OCR 模型將出現在 Models 列表中
每個程式只能有一個 OCR 模組。但是,您可以在該模組中建立多個 ROI,以讀取零件不同區域的文字。
4c. 建立 OCR ROI
- 確保 OCR 模型行在 Models 列表中處於選中(高亮)狀態
- 在 Region of Interest 部分點選 Add ROI
- 一個新的矩形 ROI 將出現在影象上
- 拖動 ROI 將其定位到您想要讀取的文字上
- 透過拖動角點手柄調整其大小
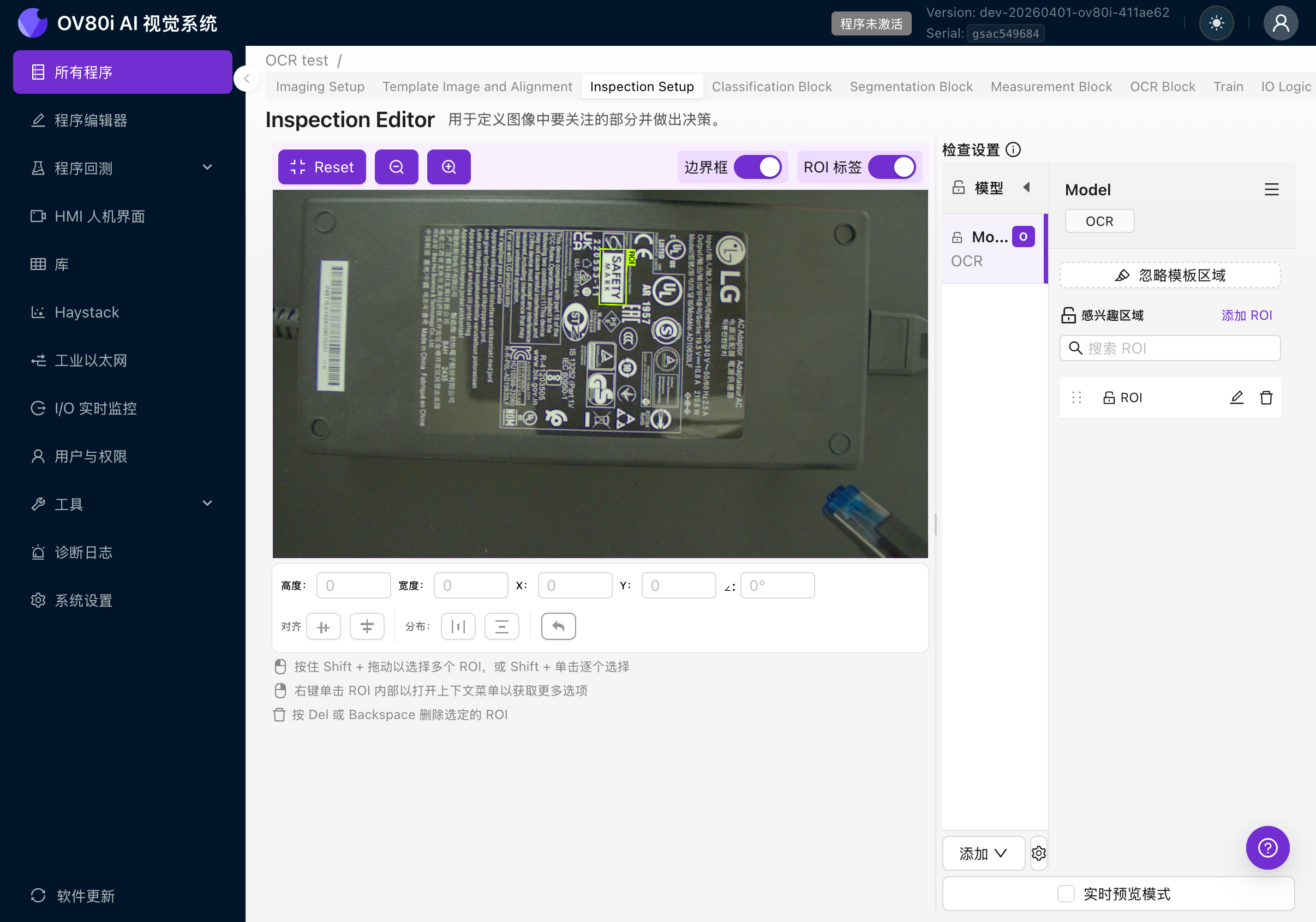
4d. 設定 ROI 方向
這是最重要的一點。您的 ROI 方向必須與您想要讀取的文字方向相匹配。
OCR 引擎使用 ROI 的角度裁剪影象,然後將裁剪結果按文字水平方向進行處理。如果您的 ROI 角度與文字角度不匹配,引擎將嘗試讀取旋轉後的文字併產生無意義的結果。
示例:
- 文字從左到右水平排列:ROI 角度應為 0 度
- 文字順時針旋轉 90 度:ROI 角度應為 90 度
- 文字上下顛倒:ROI 角度應為 180 度
- 文字呈 45 度角:ROI 角度應為 45 度
如何旋轉 ROI:
- 點選 ROI 將其選中
- 使用 ROI 角點處的旋轉手柄,或
- 直接在畫布底部的位置欄位中設定角度值
位置欄顯示:H(高度)、W(寬度)、X 和 Y(位置),以及以度為單位的角度。
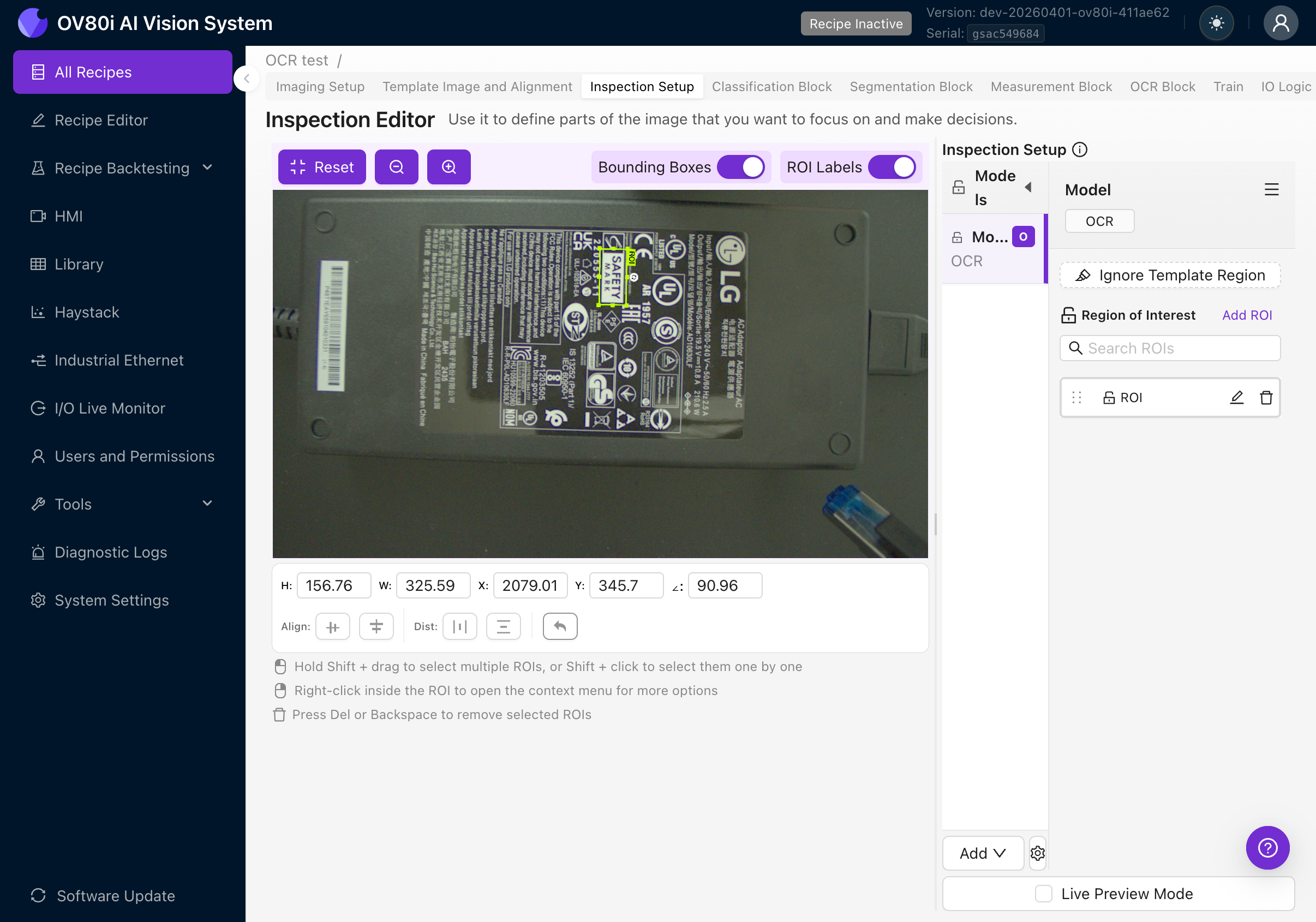
4e. 正確調整 ROI 大小
- 使 ROI 儘可能緊貼文字區域。多餘的背景會引入噪聲,並可能導致誤檢。
- 保留少量邊距(10-20 畫素),以避免字元在邊緣被裁剪。
- 不要包含其他無需識別的文字。如果存在多個文字區域,請為每個區域建立單獨的 ROI。
如果需要讀取零件上多個區域的文字(例如序列號和日期程式碼),請為每個區域建立單獨的 ROI。這樣可以獲得獨立的結果,也使透過/失敗規則更易於配置。
4f. 建立其他 ROI(可選)
為每個需要讀取的文字區域重複步驟 4c-4e。每個 ROI 會在感興趣區域列表中擁有自己的名稱。雙擊名稱可將其重新命名為具有描述性的名稱(例如 "Serial Number"、"Date Code"、"Part Label")。
使用複製貼上可快速複製 ROI。名稱會自動遞增(例如 "ROI"、"ROI (1)"、"ROI (2)")。
第 5 步:配置和測試 OCR 模型
5a. 導航到 OCR 模型
點選程式編輯器選項卡欄中的 OCR Block 選項卡。左側顯示相機畫面,右側顯示設定面板。
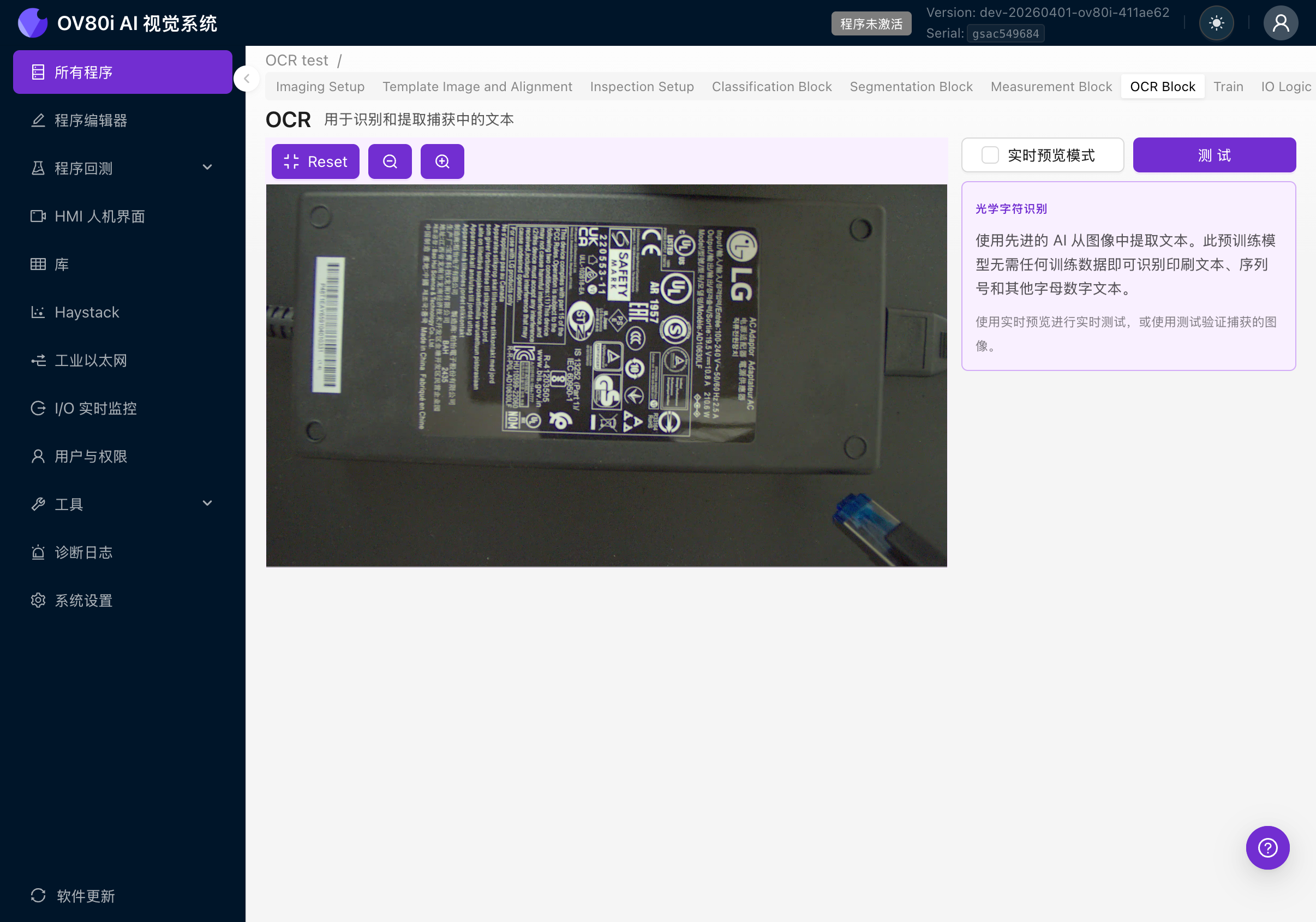
右側面板顯示:
- OPTICAL CHARACTER RECOGNITION 描述
- 說明這是一個預訓練模型,無需訓練資料
- 使用實時預覽或測試進行驗證的說明
5b. 啟用實時預覽
勾選右上角的 Live Preview Mode 覈取方塊。相機將開始實時處理幀。
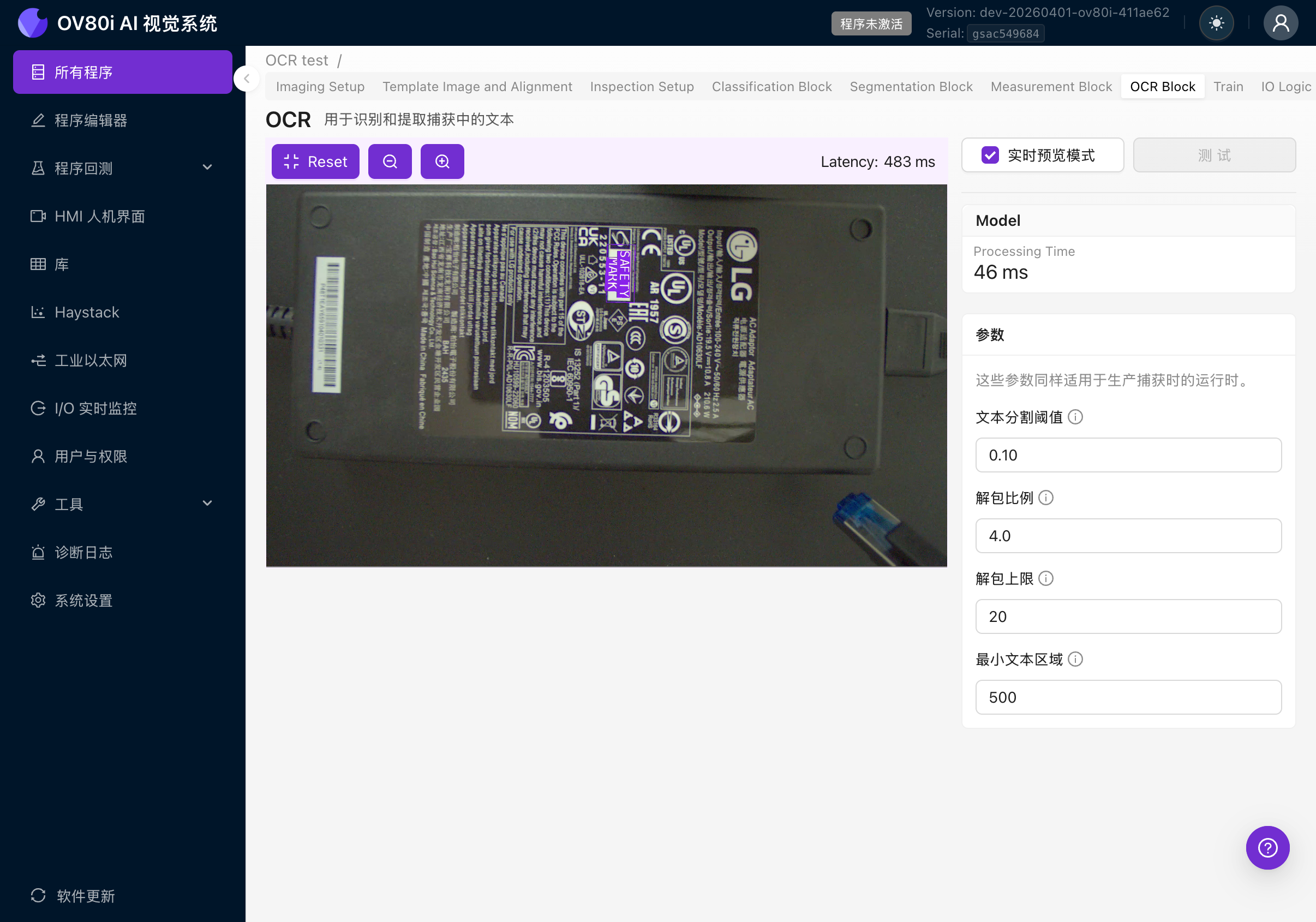
啟用實時預覽後,您將看到:
- Processing Time:OCR 模型每幀所需的處理時間
- Latency:包括影象捕獲和渲染在內的總往返時間
- 紫色邊界框疊加在相機畫面上,標識檢測到的文字區域
- 檢測到的文字作為標籤顯示在每個邊界框上
- 右側的引數面板用於調整檢測設定
5c. 驗證 OCR 是否正確讀取
啟用實時預覽後,將零件放置在相機下方並驗證:
- 是否檢測到所有文字區域? 您應該在 ROI 中的每個單詞/短語周圍看到紫色框。
- 文字是否被正確讀取? 標籤應與零件上的實際文字相匹配。
- 是否存在誤檢? 是否有非文字區域被錯誤地識別為文字?
- 輕微移動零件。 OCR 在不同位置是否仍能正常工作(這可測試對齊)?
如果文字未被檢測到或讀取錯誤,請檢查:
- ROI 方向是否與文字方向一致(參見步驟 4d)
- ROI 是否正確定位在文字上方
- 影象質量是否良好(對焦清晰、對比度高、光照均勻)
- 嘗試調整 OCR 引數(參見下一節)
第 6 步:調整 OCR 引數
啟用實時預覽後,右側面板會顯示四個可調引數。它們控制文字檢測階段(查詢文字所在位置),而不是識別階段(讀取文字內容)。
| 引數 | 預設值 | 作用 |
|---|---|---|
| Text Segmentation Threshold | 0.10 | 檢測器對某區域包含文字的置信度要求。值越高 = 檢測越嚴格,誤報越少但可能漏掉模糊文字。值越低 = 越靈敏,能捕捉模糊文字但可能產生誤檢。範圍:0.0 到 1.0。 |
| Unclip Ratio | 4.0 | 從文字輪廓向外擴充套件檢測邊界框的程度。值越高 = 邊界框越大。如果邊界框裁剪到大字元的邊緣,請增大此值。如果相鄰單詞合併到同一個框中,請減小此值。 |
| Unclip Ceiling | 20 | 擴充套件時的最大畫素數。該值限制擴充套件幅度,使大文字上的高比率擴充套件不會生成過大的框。如果大文字在增大 Unclip Ratio 後仍被裁剪,請提高此值。 |
| Min Text Area | 500 | 檢測到的文字區域的最小面積(以畫素為單位)。小於此值的內容會被作為噪聲丟棄。如果小的偽影被檢測為文字,請增大此值。如果小但有效的文字被過濾掉,請減小此值。 |
從預設值開始。僅在實時預覽中看到具體問題時才進行調整:
| 問題 | 要調整的引數 | 方向 |
|---|---|---|
| 非文字區域被檢測為文字 | Text Segmentation Threshold | 增大 |
| 有效文字被漏檢 | Text Segmentation Threshold | 減小 |
| 邊界框裁剪到字元邊緣 | Unclip Ratio | 增大 |
| 相鄰單詞合併到同一個框中 | Unclip Ratio | 減小 |
| 大文字上的框過大 | Unclip Ceiling | 減小 |
| 增大 Unclip Ratio 後大文字仍被裁剪 | Unclip Ceiling | 增大 |
| 噪聲/偽影被檢測為文字 | Min Text Area | 增大 |
| 小的有效文字被過濾掉 | Min Text Area | 減小 |
引數更改會在實時預覽中立即生效,因此您可以迭代調整。這些引數不僅在預覽期間有效,在生產捕獲期間同樣適用。
第七步:使用捕獲的影象進行測試
透過實時預覽調整引數後,請使用一系列生產樣品驗證 OCR。
7a. 使用測試面板
- 禁用實時預覽模式(取消選中覈取方塊)
- 點選 Test 按鈕
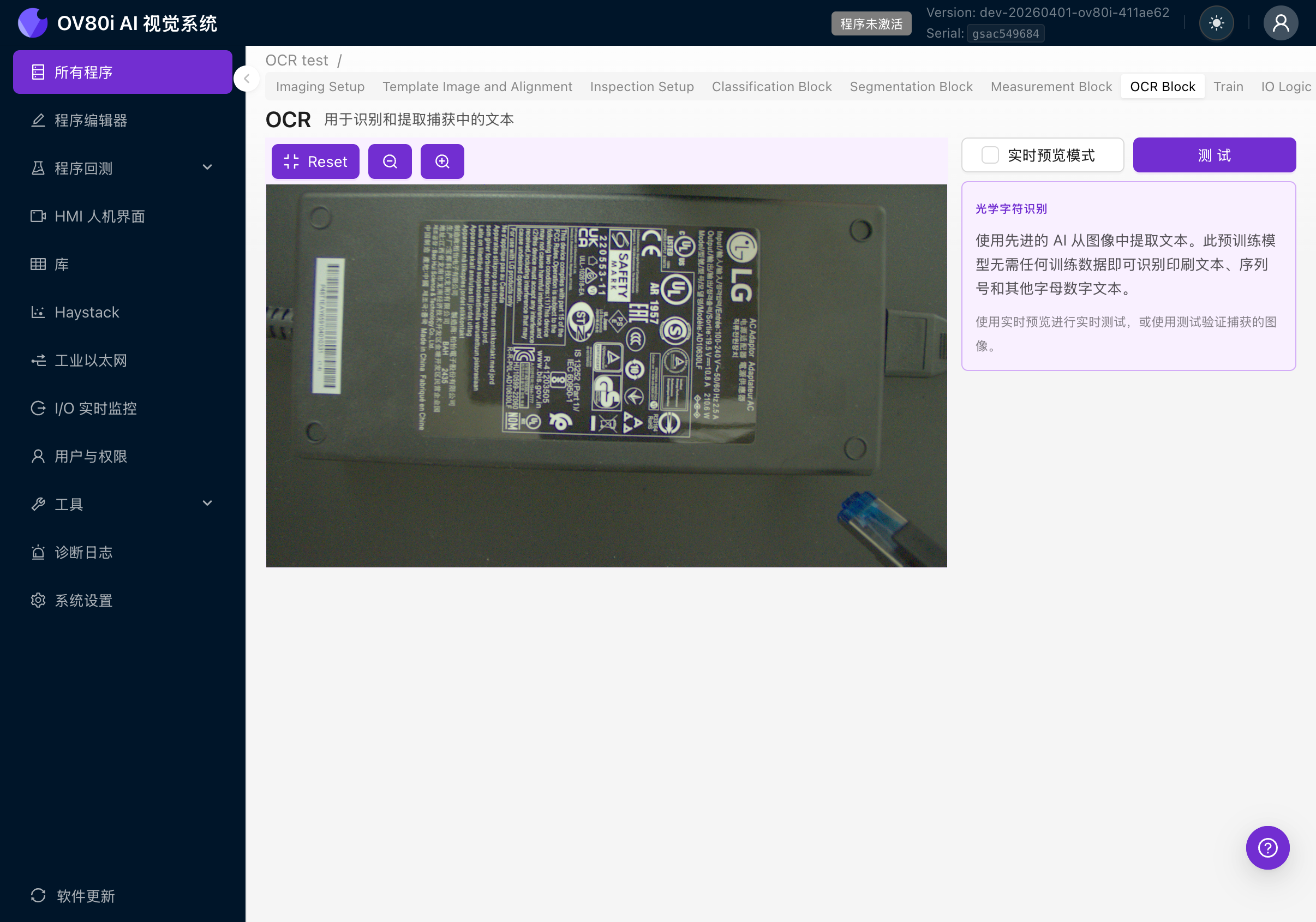
- 點選 Select From Library 從之前捕獲的檢測中選擇影象,或點選 Upload Captures 從計算機上傳影象
- 每個 ROI 的測試結果顯示:
- Detected Text(以等寬/程式碼格式顯示)
- Confidence(顏色編碼標籤:綠色高於 80%,橙色高於 50%,紅色低於 50%)
- Detection Count(找到的文字區域數量)
7b. 需要關注的內容
- 一致性:對於相同的零件,OCR 每次讀取的文字是否相同?
- 準確性:檢測到的字串是否與零件上的實際文字一致?
- 置信度分數:是否一直高於 80%?低置信度通常表示影象質量問題。
- 邊緣案例:使用文字被塗汙、褪色或部分遮擋的零件進行測試。
如果置信度分數持續低於 80%,請重新檢查影象設定(第二步)。OCR 準確性與影象質量直接相關。任何引數調優都無法彌補模糊或光照不佳的影象。
第八步:設定透過/失敗規則(IO 邏輯)
OCR 正確檢測文字後,需要定義什麼構成 pass 或 fail。導航至 IO Logic 選項卡。
基本模式
基本模式提供簡單的基於規則的 UI 用於 OCR 透過/失敗邏輯。無需 Node-RED 知識。
頁面顯示:
- 左側的 Preview / Test 選項卡(用於根據規則視覺化結果)
- 右側的 OCR Rules 部分
- 用於啟用規則的 Save & Deploy 按鈕
- 切換到 Node-RED 的 Advanced Mode 按鈕
建立規則
點選 + Add rule 建立透過/失敗規則。每條規則有三個欄位:
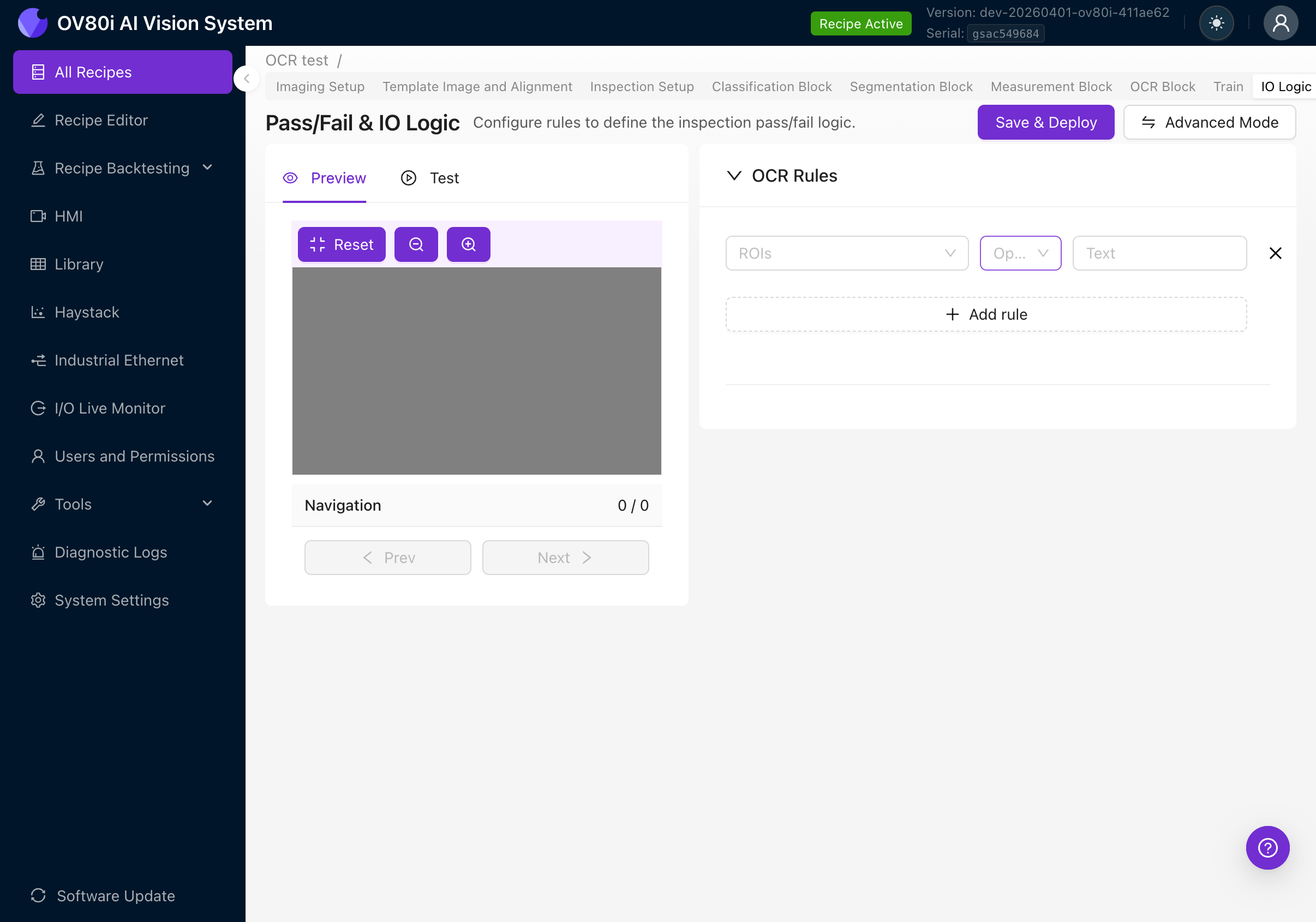
| 欄位 | 描述 |
|---|---|
| ROIs | 要評估的 ROI。點選展開並選擇 "All ROIs" 或指定特定區域。 |
| Operator | 對檢測到的文字執行的比較。 |
| Text | 要比較的預期文字字串。 |
可用運算子
點選 Operator 下拉選單檢視所有四個選項:
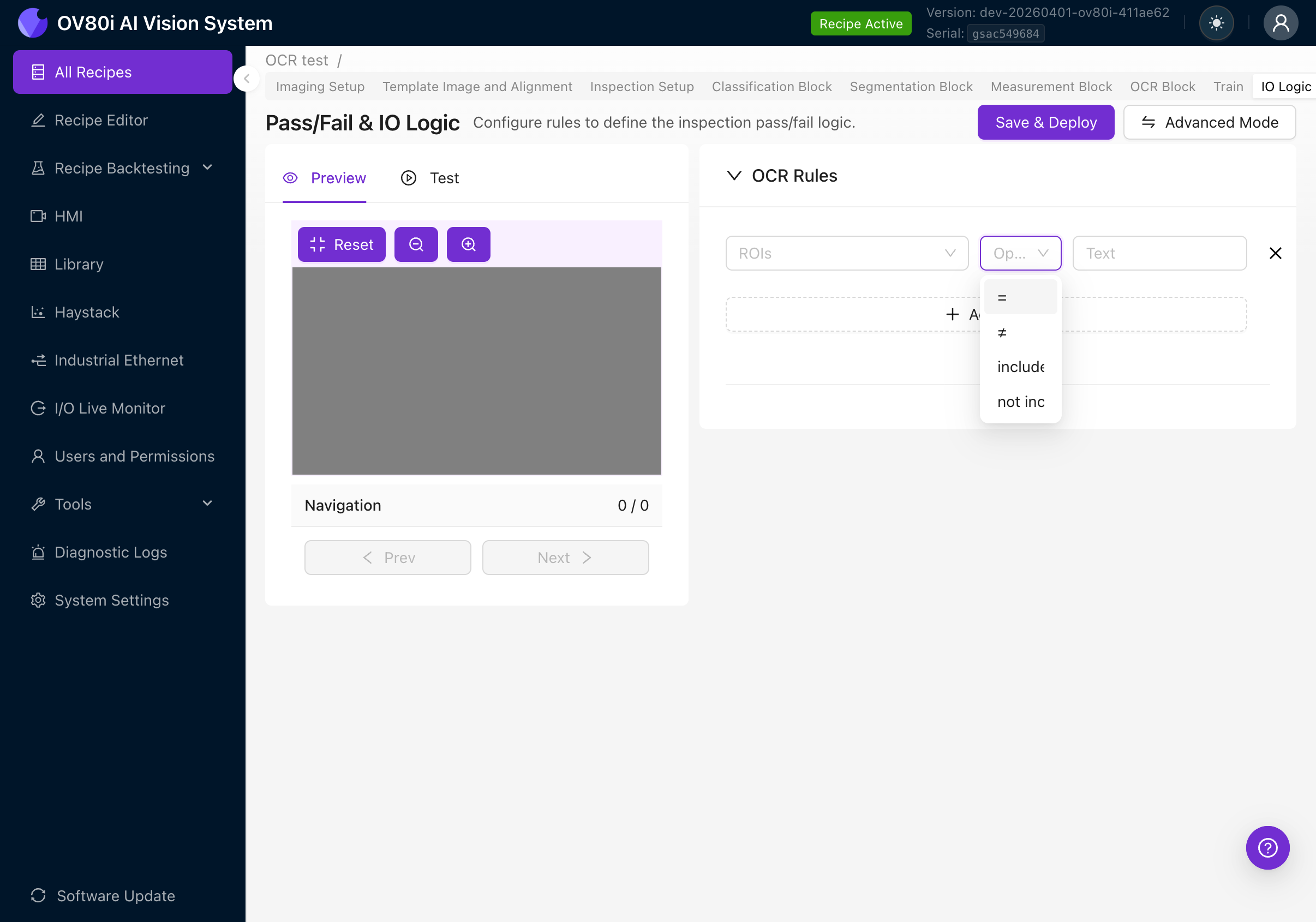
| 運算子 | 行為 | 示例用例 |
|---|---|---|
| = (equals) | 所有檢測到的文字連線後必須與預期文字完全匹配 | 驗證序列號讀取結果恰好為 "SN-2025-0042" |
| != (not equals) | 連線後的文字必須不匹配預期文字 | 拒絕帶有已知錯誤程式碼的零件 |
| includes | 連線後的文字必須包含預期文字作為子字串 | 檢查標籤中某處包含 "SAFETY" 一詞 |
| not includes | 連線後的文字必須不包含預期文字 | 確保已棄用的產品程式碼未出現 |
文字比較方式
當一個 ROI 包含多個檢測到的文字區域時(例如,檢測器將 "LOT" 和 "2025" 識別為單獨的單詞),所有獨立的文字字串將在比較前用空格拼接。
因此,如果檢測器發現三個文字區域分別讀取為 "LOT"、"2025" 和 "A1",拼接後的文字即為 "LOT 2025 A1"。您的規則將與此完整拼接字串進行比較。
這意味著:
- 針對
"LOT 2025 A1"的 equals 規則將透過 - 針對
"2025"的 includes 規則將透過 - 僅針對
"LOT"的 equals 規則將失敗(因為拼接後的文字包含的內容不止 "LOT")
多條規則
您可以透過再次點選 + Add rule 來新增多條規則。所有規則均採用 AND 邏輯:每條規則都必須透過,OCR 檢查才會透過。如果任何一條規則失敗,整個檢測都會失敗。
ROI 選擇
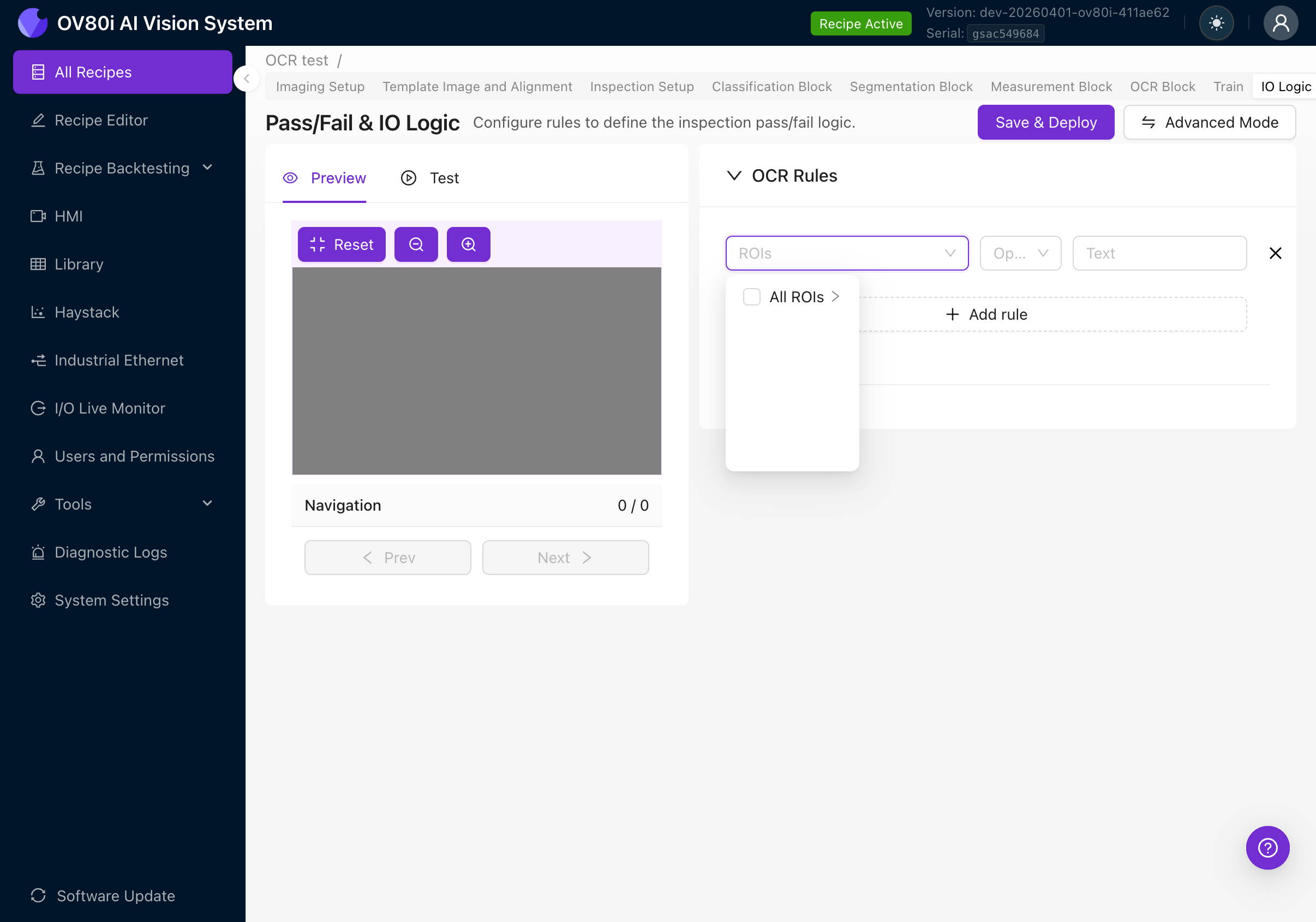
點選 ROIs 下拉選單,選擇該規則應用於哪個(哪些)區域:
- All ROIs:該規則評估所有 OCR 區域合併後的文字
- Specific ROI:展開以按名稱選擇單個 ROI(這就是為什麼在第 4f 步中以描述性方式命名您的 ROI 很重要)
儲存並部署
配置好規則後,點選 Save & Deploy 以啟用它們。規則將立即對後續所有檢測生效。
高階模式 (Node-RED)
對於基礎模式無法處理的更復雜的 pass/fail 邏輯,請切換到高階模式。
點選 Advanced Mode 按鈕,將顯示一個確認對話方塊:
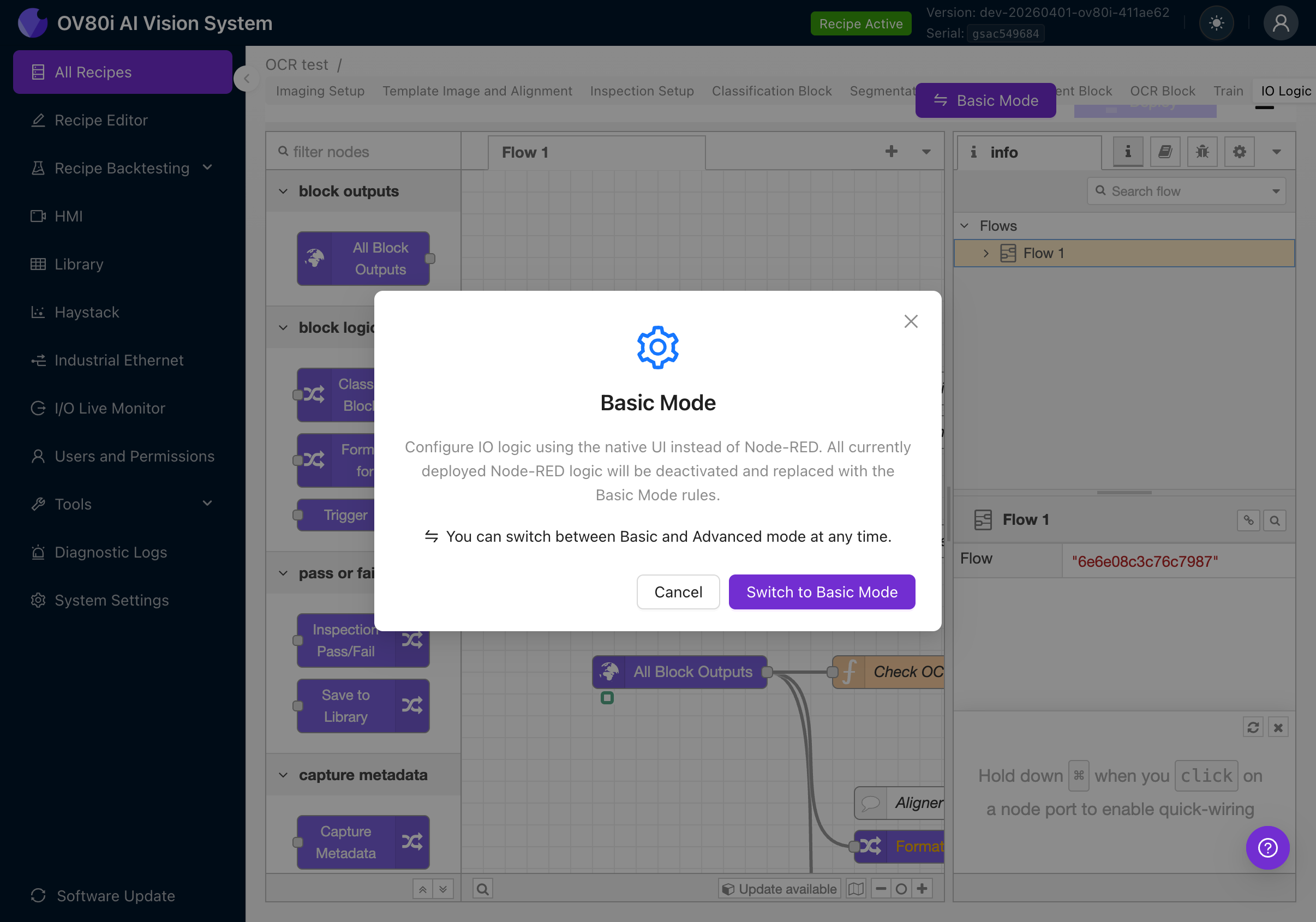
該對話方塊說明:
- 高階模式使用完整的 Node-RED 視覺化程式設計環境
- 任何基礎模式的規則都將被停用
- 您可以隨時切換回基礎模式
點選 Switch to Advanced Mode(如果您已處於高階模式,按鈕將顯示為 Basic Mode)。
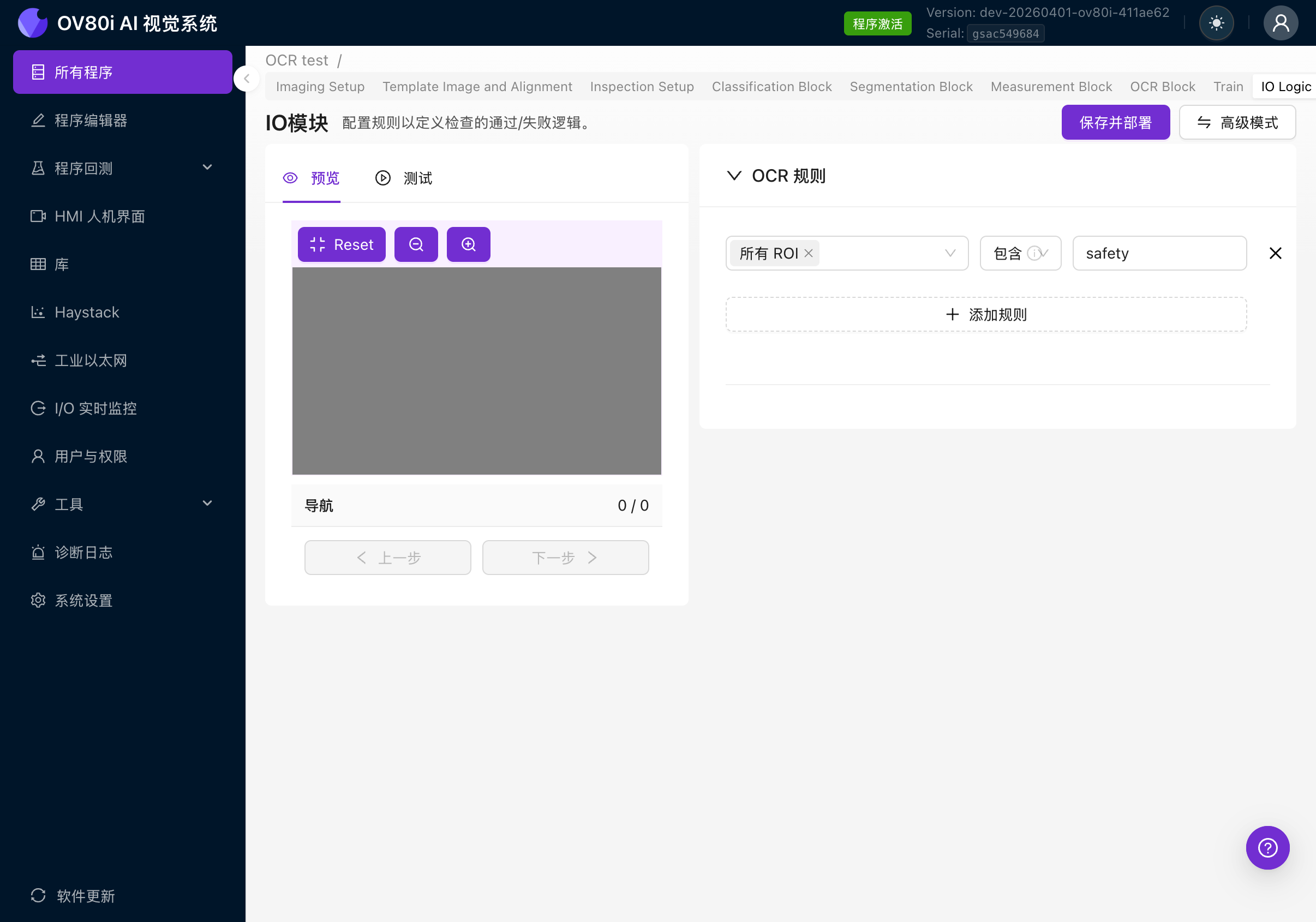
在高階模式下,您將看到一個 Node-RED 流程畫布,其中包含預構建的節點,包括:
- All Block Outputs:接收來自所有 AI 模組的結果(分類、分割、OCR、測量)
- Check OCR(或類似節點):一個包含用於評估 OCR 結果的 JavaScript 的函式節點
- Classification Block Logic / Format Data for PLC / Trigger:用於整合的其他輸出節點
- Inspection Pass/Fail:最終的透過/失敗判定
- Save to Library:儲存結果
Node-RED 中的 OCR 輸出 Payload
在高階模式下,OCR 結果可在 msg.payload.ocr 物件中獲取。這讓您可以透過程式設計方式完整訪問每個檢測結果:
{
"predictions": [
{
"roi_id": 1,
"roi_name": "Serial Number",
"center_x_global": 450,
"center_y_global": 220,
"angle_global": 90,
"search_area_id": 1,
"detections": [
{
"text": "SN-2025-0042",
"confidence": 0.95,
"roi_bbox": {
"x": 10,
"y": 5,
"width": 120,
"height": 30,
"angle": 0
},
"global_bbox": {
"x": 450,
"y": 220,
"width": 120,
"height": 30,
"angle": 90
}
}
]
}
]
}
| 欄位 | 說明 |
|---|---|
| roi_id | 產生此結果的 ROI 的數字 ID |
| roi_name | 您為 ROI 指定的名稱(例如,"Serial Number") |
| center_x_global / center_y_global | ROI 在整幀座標系中的中心位置 |
| angle_global | ROI 在整幀中的旋轉角度 |
| search_area_id | 此 ROI 所屬的檢測型別 / 搜尋區域 |
| detections | 在此 ROI 中找到的單個文字檢測的陣列 |
| detections[].text | 識別出的文字字串 |
| detections[].confidence | 識別置信度,範圍從 0.0 到 1.0(已限定區間) |
| detections[].roi_bbox | 相對於 ROI 裁剪原點的邊界框位置 |
| detections[].global_bbox | 整個相機畫面中的邊界框位置(考慮了 ROI 旋轉和對齊) |
使用 msg.payload.ocr.predictions[0].detections.map(d => d.text).join(" ") 即可獲得與基礎模式比較時所用相同的拼接文字字串。
透過高階模式,您可以:
- 使用 JavaScript 對檢測到的文字應用正規表示式模式
- 按置信度閾值過濾檢測結果
- 將 OCR 結果與分類/分割結果結合用於複雜邏輯
- 為 PLC 輸出格式化 OCR 文字(例如,透過 EtherNet/IP 傳送檢測到的序列號)
- 根據 OCR 內容向 Microsoft Teams 或電子郵件傳送自定義訊息
有關 Node-RED 的詳細指南,請參閱 Node-RED Basics。
您可以隨時使用 IO 邏輯 頁面頂部的切換按鈕在基礎模式和高階模式之間切換。切換到基礎模式時,任何已部署的 Node-RED 邏輯都將被停用,並被基礎模式的規則替換。切換回高階模式時,Node-RED 流程將被恢復。
第 9 步:部署程式
完成 OCR 設定和測試後:
- 返回 程式編輯器(點選左側邊欄中的 程式編輯器)
- 點選右下角紫色的 部署程式 按鈕
- 程式現已啟用並正在執行檢測
檢視結果
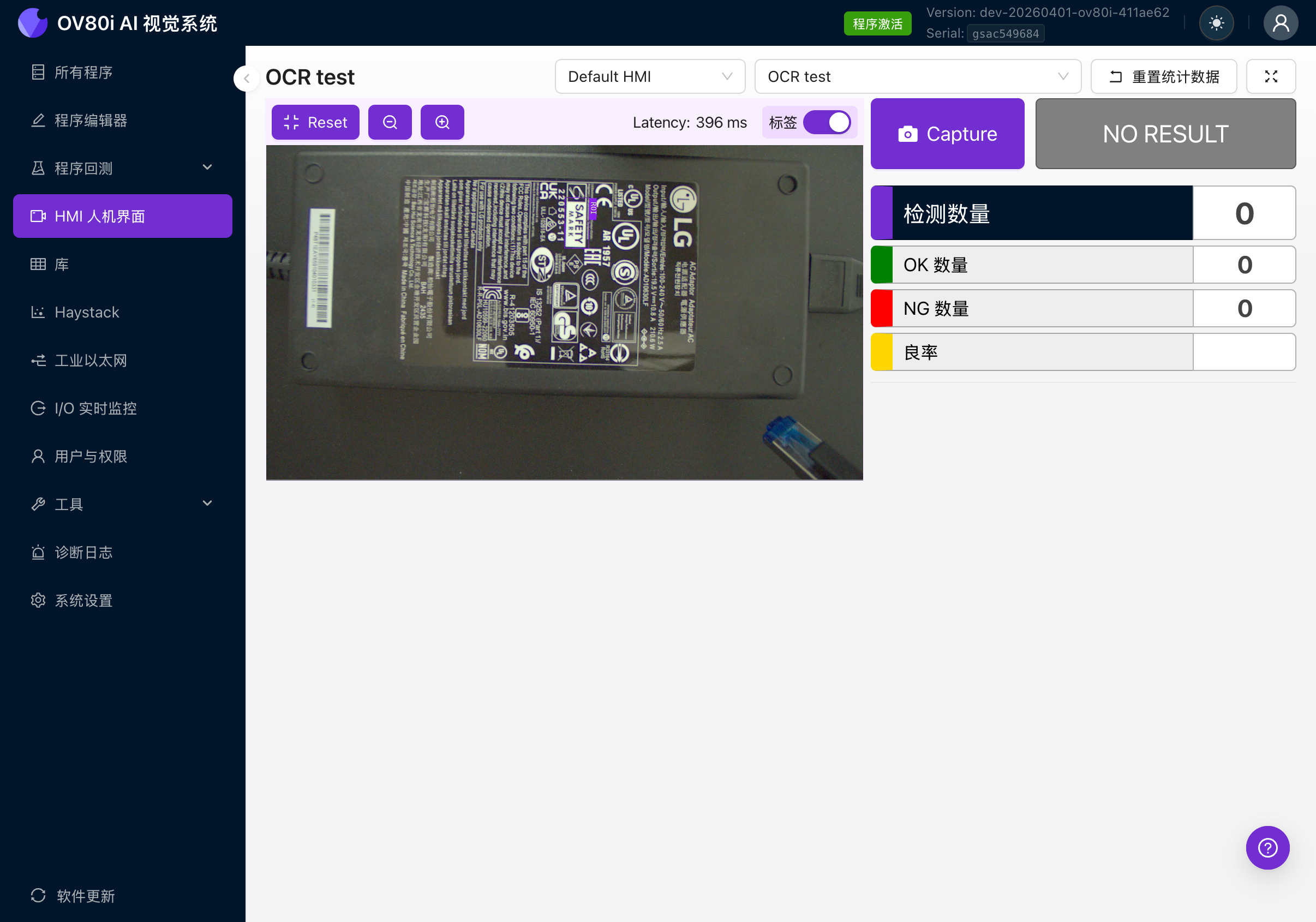
HMI
HMI 頁面顯示實時檢測結果。OCR 啟用後,您將看到:
- 實時相機畫面,檢測到的文字週圍帶有紫色邊界框
- 顯示讀取內容的文字標籤
- 基於 IO 邏輯規則的透過/失敗狀態
- 執行統計資訊:檢測總數、透過數、失敗數、良品率百分比
庫
點選左側邊欄中的 庫 可檢視過往捕獲的儲存結果。每個捕獲條目顯示:
- 帶有 OCR 疊加層的捕獲影象
- 每個 ROI 的檢測文字
- 置信度分數
- 透過/失敗結果
故障排除
未檢測到文字
| 可能原因 | 解決方法 |
|---|---|
| ROI 未定位在文字上 | 在檢測設定中重新定位 ROI |
| ROI 方向與文字不匹配 | 旋轉 ROI 以與文字方向對齊(第 4d 步) |
| 影象中文字過小 | 將相機移近或使用更長焦距的鏡頭 |
| 文字相對於 ROI 過小 | 使 ROI 更緊貼文字區域 |
| Min Text Area 過高 | 降低 Min Text Area 引數 |
| 光照不佳 / 對比度低 | 改善光照以最大化文字與背景之間的對比度 |
| 文字模糊 | 調整 C-mount 鏡頭的對焦並確認相機安裝穩固 |
| 未設定對齊 | 文字檢測需要對齊。設定模板對齊(第 3 步) |
檢測到錯誤文字(誤讀)
| 可能原因 | 解決方法 |
|---|---|
| ROI 方向與文字方向不匹配 | 這是首要原因。旋轉 ROI 以與文字方向對齊(第 4d 步) |
| 影象質量差或存在噪聲 | 增加曝光、降低增益、改善光照 |
| Text Segmentation Threshold 過低 | 提高該值以過濾誤檢測的文字 |
| 重疊的文字區域合併為單個檢測 | 降低 Unclip Ratio 以防止框合併 |
| 一個 ROI 中包含多行文字 | 如果讀取順序重要,請為每行建立單獨的 ROI |
OCR 置信度持續偏低
| 可能原因 | 解決方法 |
|---|---|
| 光照均勻性差 | 確保文字區域光照均勻 |
| 文字上有眩光或反射(尤其是光面標籤) | 調整光照角度以消除鏡面反射。考慮使用漫射光照。 |
| 字型非常小或樣式過於風格化 | 將相機移近或使用更長焦距的鏡頭以增大影象中的文字尺寸 |
| 文字損壞、褪色或部分印刷 | OCR 只能讀取相機看到的內容。如果文字物理上已退化,準確度會降低。 |
| 影象設定中增益過高 | 降低增益。高增益會引入看起來像文字偽影的噪聲。 |
透過/失敗規則未按預期工作
| 可能原因 | 解決方法 |
|---|---|
| 文字拼接方式與預期不同 | 啟用實時預覽並檢查確切檢測到的文字。請記住,多個檢測結果使用空格連線。 |
| 在應使用 "includes" 時使用了 "equals" | 如果您只關心子字串,請使用 "includes" 而非 "equals" |
| 規則未部署 | 在 Basic Mode 中更改規則後,點選 Save & Deploy |
| 規則中選擇了錯誤的 ROI | 檢查規則中的 ROIs 下拉選單,確保其目標為正確的區域 |
限制
- 每個程式最多 1 個 OCR 模型(該模型內可包含多個 ROI)
- 僅針對英文最佳化的模型:預訓練模型針對基於拉丁字母的印刷文字進行了最佳化。不支援手寫體、草書或非拉丁文字(中文、日文、韓文、阿拉伯文)。
- 基本模式下不支援正規表示式或模式匹配:透過/失敗規則使用簡單的字串比較(等於、不等於、包含、不包含)。對於複雜的驗證模式(例如,匹配 "SN-####-####"),請使用高階模式(Node-RED)配合自定義 JavaScript 正規表示式。
- 無使用者可配置的字符集:模型的 480 字元字典是固定的。例如,您無法將識別限制為僅數字。請使用透過/失敗規則來驗證預期格式。
- 不保證文字順序:當在一個 ROI 內檢測到多個文字區域時,它們將按檢測順序(按輪廓)連線,不一定按閱讀順序(從左到右、從上到下)。如果閱讀順序很重要,請為每行文字使用單獨的 ROI。
- 僅預訓練模型:與分類和分割不同,OCR 模型無法針對您的特定字型或文字樣式進行重新訓練或微調。它使用內建的預訓練 OCR 模型。
另請參閱
- 建立首個檢測 - 完整的程式建立演練
- 影象設定 - 詳細的影象設定指南
- 對齊 - 模板對齊深入講解
- 感興趣區域 (ROI) - ROI 尺寸與策略
- 檢測設定與 ROI 型別 - ROI 型別參考
- Node-RED 基礎 - 高階 IO 邏輯程式設計
- 影象設定基礎 - 照明與影象質量理論