KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
OCR (Optical Character Recognition)
Die OV80i kann gedruckten Text, Seriennummern, Datumscodes und andere alphanumerische Zeichen direkt aus Kamerabildern mithilfe eines vortrainierten OCR-Modells lesen. Im Gegensatz zu Classifiern und Segmentern benötigt OCR keine Trainingsdaten. Es funktioniert sofort einsatzbereit.
OCR ist nützlich, wenn Sie:
- Seriennummern oder Chargencodes auf Übereinstimmung mit erwarteten Werten prüfen möchten
- Bestätigen möchten, dass Etiketten vorhanden und lesbar sind
- Datums-/Verfallscodes zur Rückverfolgbarkeit lesen möchten
- Teilenummern auf Komponenten während der Montage überprüfen möchten
OCR ist ausschließlich auf der OV80i verfügbar. Die OV20i und OV10i unterstützen kein OCR.
Funktionsweise von OCR
Die OV80i verwendet eine zweistufige KI-Pipeline zur Texterkennung:
- Text Detection: Findet die Position von Text innerhalb der ROI. Gibt Bounding Boxes um jedes erkannte Wort oder jede Textregion zurück.
- Text Recognition: Liest die Zeichen innerhalb jeder erkannten Bounding Box und gibt die Textzeichenfolge zusammen mit einem Konfidenzwert zurück.
Dieser gesamte Prozess läuft auf der NVIDIA Jetson Orin NX GPU der Kamera. Es ist keine Cloud-Verbindung erforderlich.
Das Modell erkennt einen umfangreichen Zeichensatz, darunter:
- Ziffern (0-9)
- Lateinische Buchstaben (A-Z, a-z, Buchstaben mit Akzenten)
- Gängige Satz- und Sonderzeichen
- Griechische Buchstaben
- Währungssymbole
- Mathematische Operatoren
Der Zeichensatz ist festgelegt und kann nicht angepasst werden. Das Modell unterstützt etwa 480 Zeichen und deckt damit die meisten gedruckten Industrietexte in lateinbasierten Sprachen ab.
Voraussetzungen
Bevor Sie OCR einrichten, benötigen Sie eine Kamera, die:
- Physisch montiert und stabil ist
- Mit Ihrem Netzwerk verbunden und im Browser erreichbar ist
- Auf das Teil mit dem zu lesenden Text fokussiert ist
Falls Sie dies noch nicht erledigt haben, folgen Sie zuerst den Einstiegsleitfäden:
Schritt 1: Neue Recipe erstellen
Jede Inspektion beginnt mit einer Recipe. Eine Recipe ist ein vollständiges Paket: Bildeinstellungen, Ausrichtung, Regions of Interest (ROIs), KI-Modelle und Ausgaberegeln.
- Navigieren Sie in der linken Seitenleiste zu All Recipes
- Klicken Sie oben rechts auf + New
- Geben Sie Ihrer Recipe einen aussagekräftigen Namen (z. B. "Serial Number Check", "Label Verification")
- Klicken Sie auf Activate, um sie als aktive Recipe festzulegen, und dann auf Edit, um den Recipe Editor zu öffnen
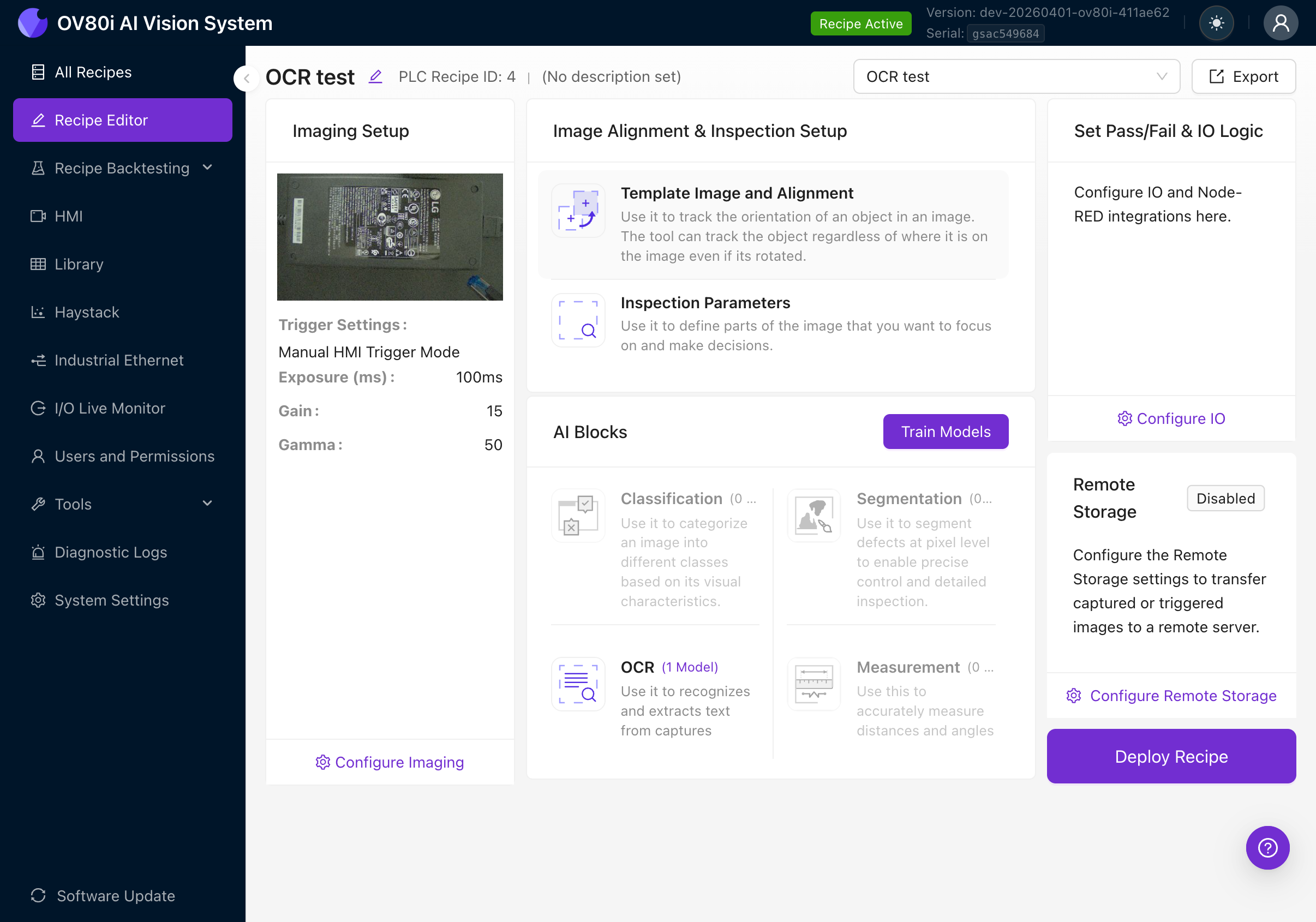
Der Recipe Editor zeigt die vollständige Inspektionspipeline. Sie arbeiten sich von links nach rechts durch:
- Imaging Setup (Kameraeinstellungen)
- Image Alignment & Inspection Setup (Template, ROIs)
- AI Blocks (Classification, Segmentation, OCR, Measurement)
- Set Pass/Fail & IO Logic (Ausgaberegeln)
Eine detaillierte Anleitung zur Erstellung einer Recipe finden Sie unter Create First Inspection.
Schritt 2: Bildeinstellungen konfigurieren
Eine gute Bildqualität ist die Grundlage für genaue OCR-Ergebnisse. Der Text muss klar sichtbar sein und einen starken Kontrast aufweisen.
- Klicken Sie auf Configure Imaging oder navigieren Sie zum Tab Imaging Setup
- Passen Sie die folgenden Einstellungen an, während Sie die Live-Vorschau beobachten:
| Einstellung | Ziel für OCR |
|---|---|
| Exposure | Hell genug, um den gesamten Text deutlich zu erkennen. Zu dunkel, und Zeichen verschwinden im Hintergrund. Zu hell, und weiße Etiketten überbelichten. |
| Gain | So niedrig wie möglich halten. Ein hoher Gain erzeugt Rauschen, das für den Detector wie Textartefakte aussieht. |
| Gamma | Anpassen, um den Kontrast zwischen Text und Hintergrund zu verbessern. |
| Focus | Der Text muss scharf sein. Wenn Zeichen unscharf oder verschwommen aussehen, passen Sie den Fokusring des C-Mount-Objektivs an. |
Die OCR-Genauigkeit hängt stark von der Bildqualität ab. Der Text muss im Kamerabild klar sichtbar und mit gutem Kontrast zum Hintergrund erkennbar sein. Sowohl dunkler Text auf hellem Hintergrund als auch heller Text auf dunklem Hintergrund funktionieren gut. Vermeiden Sie:
- Ungleichmäßige Beleuchtung, die Schatten über Zeichen wirft
- Blendungen auf glänzenden Etiketten
- Unterbelichtung, die es erschwert, Text vom Hintergrund zu unterscheiden
Zoomen Sie in der Live-Vorschau in den Textbereich hinein. Können Sie jedes Zeichen klar lesen? Wenn Sie es nicht lesen können, kann die KI es auch nicht.
Eine detaillierte Anleitung zu allen Bildeinstellungen finden Sie unter Image Settings.
Schritt 3: Vorlagenausrichtung einrichten
Die Vorlagenausrichtung teilt der Kamera mit, wie sie die Position und Ausrichtung Ihres Teils verfolgen soll. Dies ist unerlässlich, da Teile nicht immer genau an derselben Stelle auf dem Förderband oder der Vorrichtung landen.
- Navigieren Sie zum Tab Template Image and Alignment
- Platzieren Sie Ihr Teil im Sichtfeld der Kamera
- Klicken Sie auf Capture Template, um ein Referenzbild aufzunehmen
- Zeichnen Sie 2–3 kleine Vorlagenbereiche auf Merkmalen ein, die immer vorhanden und leicht zu identifizieren sind (z. B. Ecken, Logos, Befestigungslöcher)
Platzieren Sie die Vorlagenbereiche so weit wie möglich voneinander entfernt auf dem Teil. Dies reduziert das Winkelrauschen bei der Ausrichtung drastisch. Zwei nahe beieinanderliegende Bereiche ergeben eine schlechte Rotationsstabilität; zwei Bereiche an gegenüberliegenden Ecken ergeben eine ausgezeichnete Stabilität.
Wenn Sie die Ausrichtung überspringen, sind Ihre OCR-ROIs an absolute Pixelpositionen gebunden. Jede Bewegung des Teils führt dazu, dass der ROI den Text verfehlt. Richten Sie die Ausrichtung für den Produktionseinsatz immer ein.
Eine ausführliche Anleitung zur Vorlagenausrichtung finden Sie unter Alignment.
Schritt 4: OCR Regions of Interest (ROIs) erstellen
Jetzt legen Sie genau fest, wo auf dem Teil die Kamera nach Text suchen soll. Dies ist der wichtigste Schritt für die OCR-Genauigkeit.
4a. Zum Inspection Setup navigieren
- Klicken Sie auf den Tab Inspection Setup im Recipe Editor
- Der Inspection Editor mit Ihrem Vorlagenbild wird angezeigt
4b. OCR-Modell hinzufügen
- Suchen Sie im rechten Bereich nach dem Abschnitt Models
- Wenn kein OCR-Modell aufgeführt ist, klicken Sie unten auf die Schaltfläche Add und wählen Sie OCR
- Das OCR-Modell erscheint in der Models-Liste
Sie können pro Rezept nur einen OCR-Block haben. Sie können jedoch mehrere ROIs innerhalb dieses Blocks erstellen, um Text aus verschiedenen Bereichen des Teils zu lesen.
4c. Einen OCR-ROI erstellen
- Stellen Sie sicher, dass die Zeile des OCR-Modells in der Models-Liste ausgewählt (hervorgehoben) ist
- Klicken Sie auf Add ROI im Abschnitt Region of Interest
- Ein neuer rechteckiger ROI erscheint auf dem Bild
- Ziehen Sie den ROI, um ihn über dem Text zu positionieren, den Sie lesen möchten
- Passen Sie die Größe durch Ziehen an den Eckpunkten an
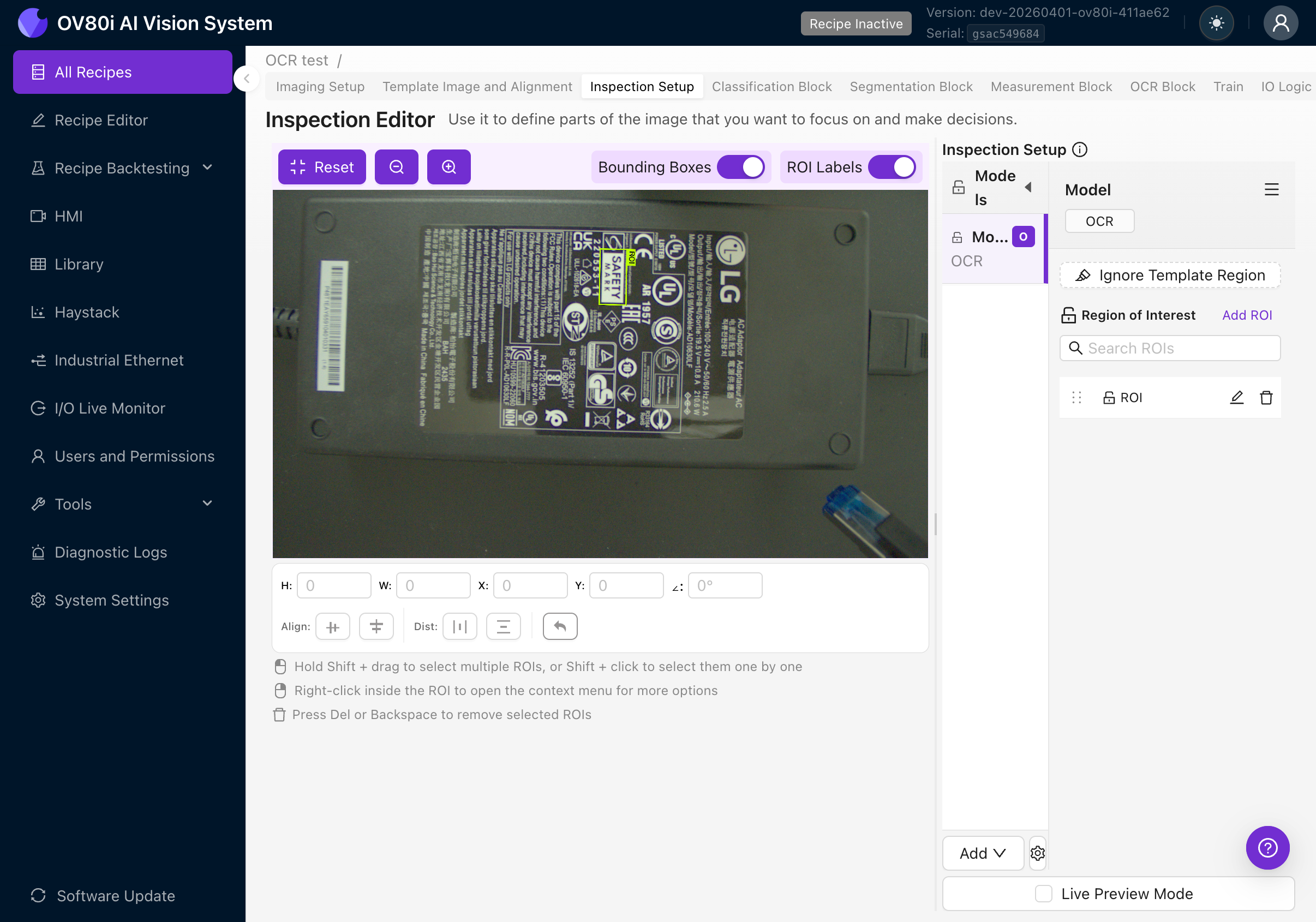
4d. ROI-Ausrichtung einstellen
Dies ist der wichtigste Punkt, den Sie richtig einstellen müssen. Die Ausrichtung Ihres ROI muss mit der Ausrichtung des Textes übereinstimmen, den Sie lesen möchten.
Die OCR-Engine schneidet das Bild anhand des Winkels des ROI zu und verarbeitet den Ausschnitt dann so, als wäre der Text horizontal. Wenn der Winkel Ihres ROI nicht mit dem Textwinkel übereinstimmt, versucht die Engine, gedrehten Text zu lesen, und liefert unbrauchbare Ergebnisse.
Beispiele:
- Text wird horizontal von links nach rechts gelesen: ROI-Winkel sollte 0 Grad sein
- Text ist um 90 Grad im Uhrzeigersinn gedreht: ROI-Winkel sollte 90 Grad sein
- Text steht auf dem Kopf: ROI-Winkel sollte 180 Grad sein
- Text ist um 45 Grad geneigt: ROI-Winkel sollte 45 Grad sein
So drehen Sie einen ROI:
- Wählen Sie den ROI durch Anklicken aus
- Verwenden Sie den Rotationsgriff an der Ecke des ROI, ODER
- Legen Sie den Winkelwert direkt in den Positionsfeldern am unteren Rand des Canvas fest
Die Positionsleiste zeigt: H (Höhe), W (Breite), X und Y (Position) sowie den Winkel in Grad.
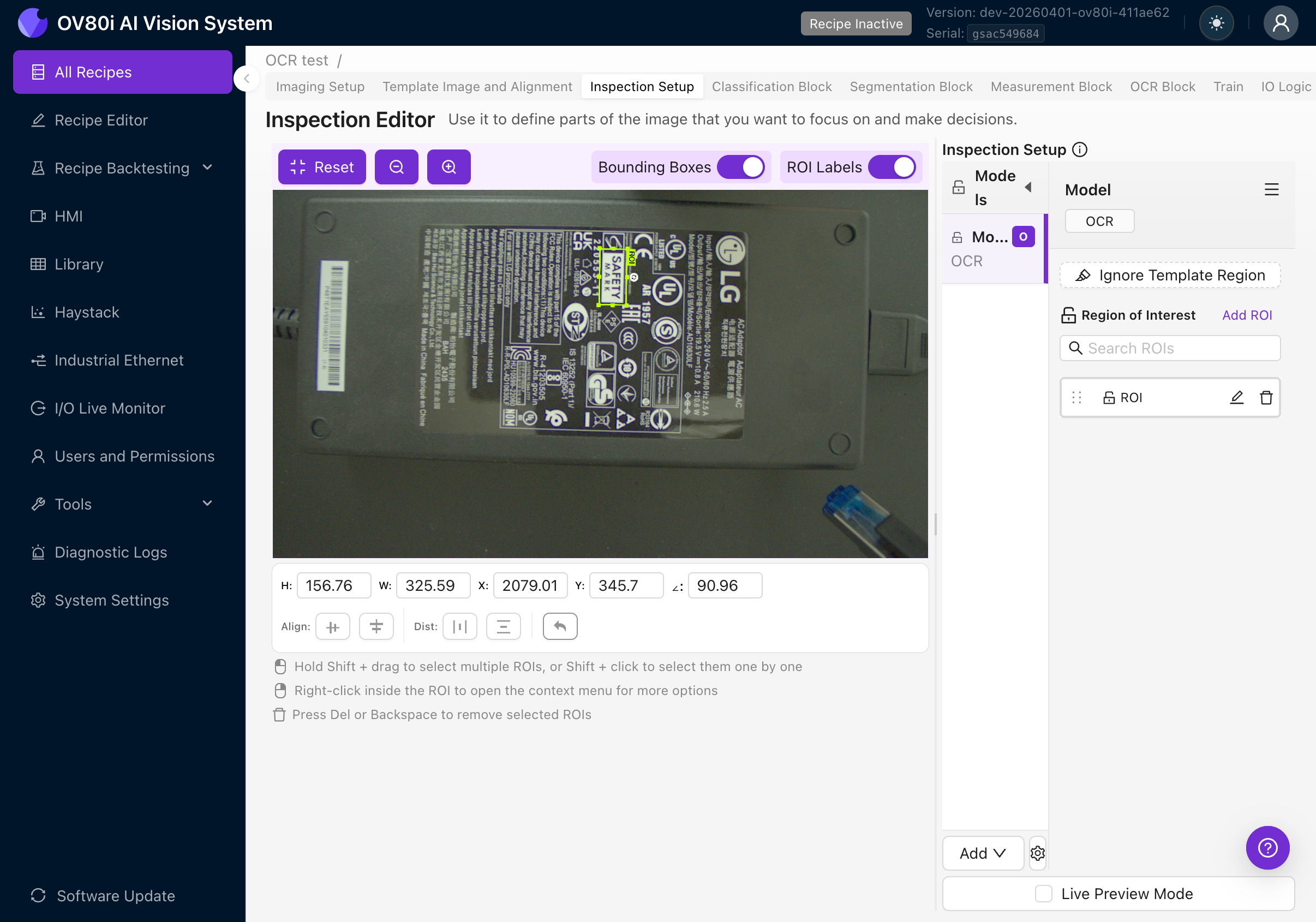
4e. ROI korrekt dimensionieren
- Legen Sie den ROI so eng wie möglich um den Textbereich. Zusätzlicher Hintergrund führt zu Rauschen und kann Fehldetektionen verursachen.
- Fügen Sie einen kleinen Rand (10–20 Pixel) um den Text hinzu, damit Zeichen an den Rändern nicht abgeschnitten werden.
- Schließen Sie keinen anderen Text ein, den Sie nicht lesen möchten. Bei mehreren Textbereichen erstellen Sie für jeden einen separaten ROI.
Wenn Sie Text aus mehreren Bereichen des Bauteils lesen müssen (z. B. eine Seriennummer UND einen Datumscode), erstellen Sie für jeden einen separaten ROI. So erhalten Sie unabhängige Ergebnisse und können Pass/Fail-Regeln einfacher konfigurieren.
4f. Zusätzliche ROIs erstellen (Optional)
Wiederholen Sie die Schritte 4c–4e für jeden Textbereich, den Sie lesen müssen. Jeder ROI erhält seinen eigenen Namen in der Region of Interest-Liste. Benennen Sie diese aussagekräftig um (z. B. „Serial Number", „Date Code", „Part Label"), indem Sie auf den Namen doppelklicken.
Verwenden Sie Kopieren und Einfügen, um ROIs zu duplizieren. Die Namen werden automatisch hochgezählt (z. B. „ROI", „ROI (1)", „ROI (2)").
Schritt 5: OCR-Block konfigurieren und testen
5a. Zum OCR-Block navigieren
Klicken Sie auf den Tab OCR Block in der Tab-Leiste des Recipe Editors. Sie sehen den Kamera-Feed auf der linken Seite und ein Einstellungs-Panel auf der rechten Seite.
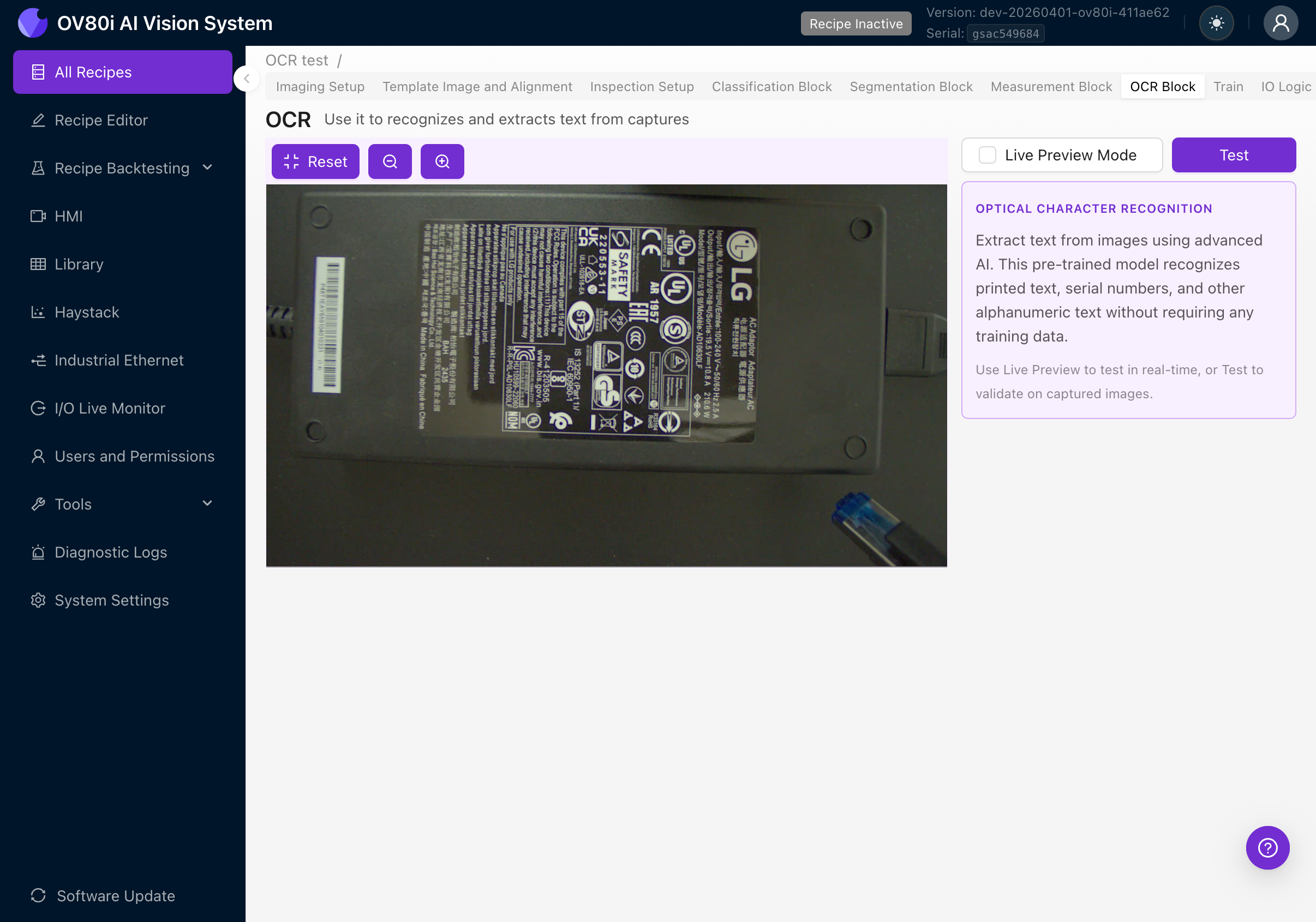
Das rechte Panel zeigt:
- Beschreibung von OPTICAL CHARACTER RECOGNITION
- Erläuterung, dass es sich um ein vortrainiertes Modell handelt, das keine Trainingsdaten benötigt
- Anweisungen zur Validierung mit Live Preview oder Test
5b. Live Preview aktivieren
Aktivieren Sie das Kontrollkästchen Live Preview Mode oben rechts. Die Kamera beginnt, Frames in Echtzeit zu verarbeiten.
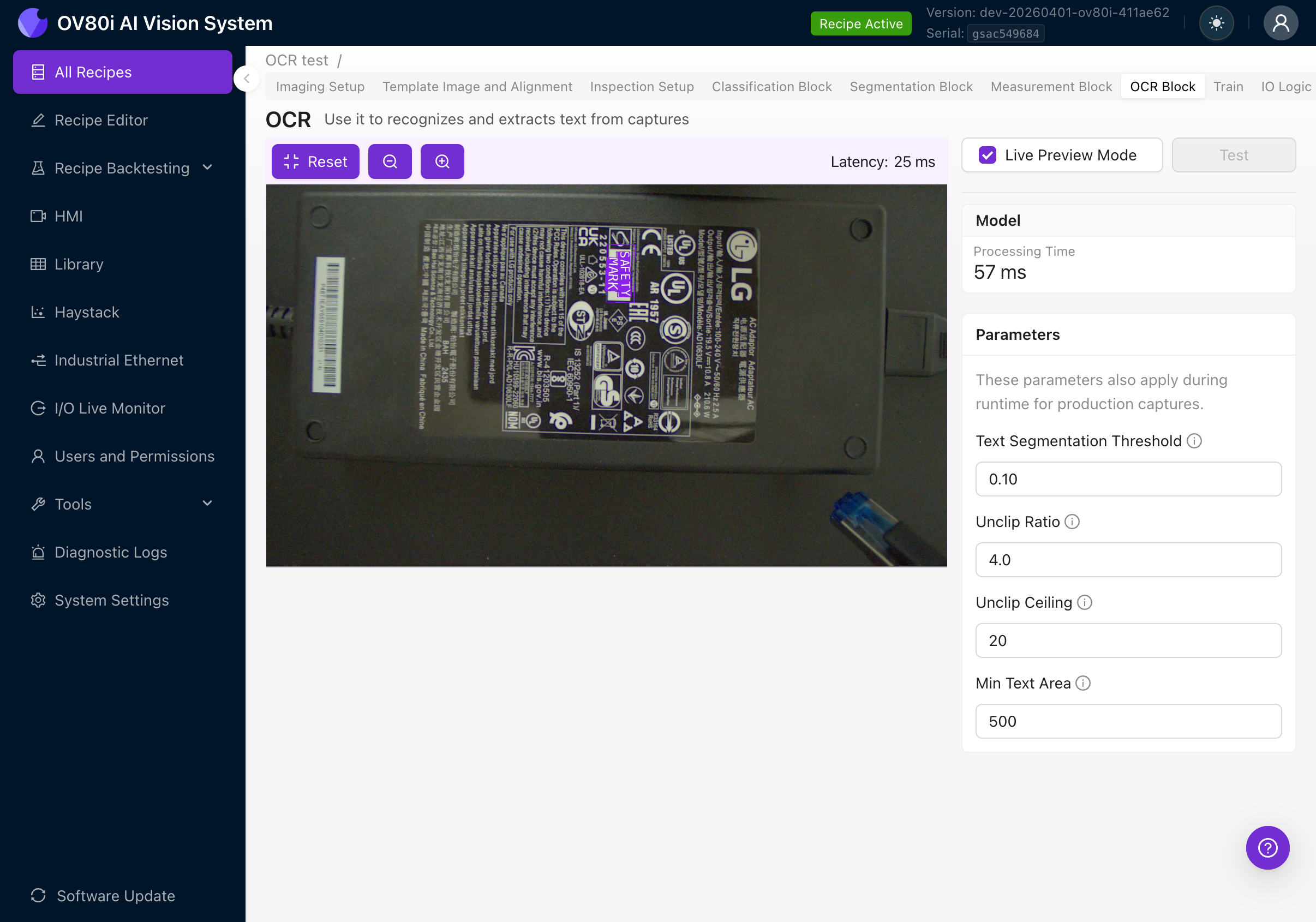
Bei aktivem Live Preview sehen Sie:
- Processing Time: Wie lange das OCR-Modell pro Frame benötigt
- Latency: Gesamte Round-Trip-Zeit einschließlich Bilderfassung und Rendering
- Violette Bounding Boxes um erkannte Textregionen, die auf dem Kamera-Feed eingeblendet werden
- Erkannter Text als Labels auf jeder Bounding Box angezeigt
- Parameter-Panel auf der rechten Seite zur Feinabstimmung der Detektionseinstellungen
5c. Prüfen, ob OCR korrekt liest
Legen Sie bei aktiviertem Live Preview Ihr Bauteil unter die Kamera und prüfen Sie:
- Werden alle Textregionen erkannt? Sie sollten violette Boxen um jedes Wort/jede Phrase im ROI sehen.
- Wird der Text korrekt gelesen? Die Labels sollten mit dem tatsächlichen Text auf dem Bauteil übereinstimmen.
- Gibt es Fehldetektionen? Werden Nicht-Text-Bereiche fälschlicherweise als Text erkannt?
- Bewegen Sie das Bauteil leicht. Funktioniert OCR weiterhin an verschiedenen Positionen (dies testet die Ausrichtung)?
Falls Text nicht erkannt oder falsch gelesen wird, prüfen Sie:
- Die ROI-Ausrichtung stimmt mit der Textausrichtung überein (siehe Schritt 4d)
- Der ROI ist korrekt über dem Text positioniert
- Die Bildqualität ist gut (scharfer Fokus, guter Kontrast, gleichmäßige Beleuchtung)
- Versuchen Sie, die OCR-Parameter anzupassen (siehe nächster Abschnitt)
Schritt 6: OCR-Parameter feinabstimmen
Wenn Live Preview aktiviert ist, zeigt das rechte Panel vier einstellbare Parameter an. Diese steuern die Textdetektionsphase (wo sich Text befindet), nicht die Erkennungsphase (was er aussagt).
| Parameter | Standard | Funktion |
|---|---|---|
| Text Segmentation Threshold | 0.10 | Wie sicher der Detektor sein muss, dass eine Region Text enthält. Höhere Werte = strengere Detektion, weniger False Positives, aber möglicherweise werden schwache Texte übersehen. Niedrigere Werte = empfindlicher, erfasst schwachen Text, kann aber Fehldetektionen aufweisen. Bereich: 0.0 bis 1.0. |
| Unclip Ratio | 4.0 | Wie weit erkannte Bounding Boxes von der Textkontur nach außen erweitert werden. Höhere Werte = größere Boxen. Erhöhen, wenn Boxen die Ränder großer Zeichen abschneiden. Verringern, wenn benachbarte Wörter zu einer Box zusammengeführt werden. |
| Unclip Ceiling | 20 | Maximale Pixelerweiterung beim Unclipping. Dies begrenzt das Wachstum, damit große Ratio-Erweiterungen bei großem Text keine übermäßig großen Boxen erzeugen. Erhöhen, wenn großer Text auch nach Erhöhung der Unclip Ratio noch abgeschnitten wird. |
| Min Text Area | 500 | Mindestfläche (in Pixel) für eine erkannte Textregion. Alles Kleinere wird als Rauschen verworfen. Erhöhen, wenn kleine Artefakte als Text erkannt werden. Verringern, wenn kleiner, aber gültiger Text herausgefiltert wird. |
Beginnen Sie mit den Standardwerten. Passen Sie nur an, wenn Sie spezifische Probleme im Live Preview sehen:
| Problem | Anzupassender Parameter | Richtung |
|---|---|---|
| Nicht-Text-Bereiche werden als Text erkannt | Text Segmentation Threshold | Erhöhen |
| Gültiger Text wird nicht erkannt | Text Segmentation Threshold | Verringern |
| Bounding Boxes schneiden Zeichenränder ab | Unclip Ratio | Erhöhen |
| Benachbarte Wörter werden zu einer Box zusammengeführt | Unclip Ratio | Verringern |
| Boxen werden bei großem Text zu groß | Unclip Ceiling | Verringern |
| Großer Text wird nach Erhöhung der Unclip Ratio weiterhin abgeschnitten | Unclip Ceiling | Erhöhen |
| Rauschen/Artefakte werden als Text erkannt | Min Text Area | Erhöhen |
| Kleiner gültiger Text wird herausgefiltert | Min Text Area | Verringern |
Parameteränderungen werden im Live Preview sofort wirksam, sodass Sie iterativ anpassen können. Diese Parameter gelten auch bei Produktionsaufnahmen, nicht nur während der Vorschau.
Schritt 7: Test mit erfassten Bildern
Nachdem Sie die Parameter mit der Live-Vorschau abgestimmt haben, validieren Sie OCR anhand einer Reihe von Produktionsmustern.
7a. Verwendung des Test-Panels
- Deaktivieren Sie den Live-Vorschau-Modus (Kontrollkästchen deaktivieren)
- Klicken Sie auf die Schaltfläche Test
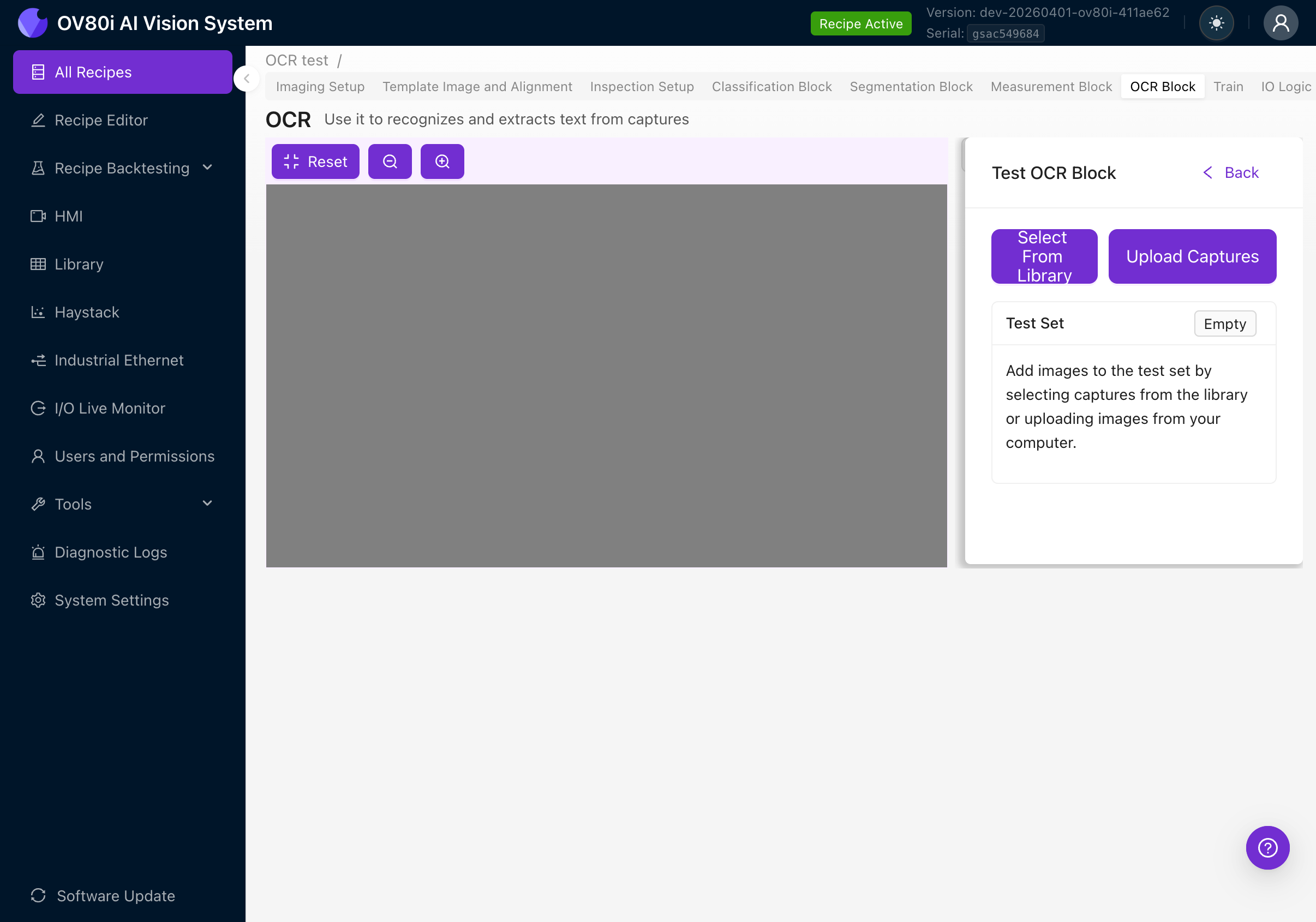
- Klicken Sie auf Select From Library, um Bilder aus zuvor erfassten Inspektionen auszuwählen, oder klicken Sie auf Upload Captures, um Bilder von Ihrem Computer hochzuladen
- Die Testergebnisse zeigen für jede ROI:
- Detected Text (in Monospace-/Code-Formatierung angezeigt)
- Confidence (farbcodiertes Tag: grün über 80 %, orange über 50 %, rot unter 50 %)
- Detection Count (wie viele Textregionen gefunden wurden)
7b. Worauf Sie achten sollten
- Konsistenz: Liest OCR bei demselben Teil jedes Mal denselben Text?
- Genauigkeit: Stimmen die erkannten Zeichenketten mit dem tatsächlichen Text auf dem Teil überein?
- Confidence-Werte: Liegen sie durchgängig über 80 %? Niedrige Confidence weist häufig auf Probleme mit der Bildqualität hin.
- Grenzfälle: Testen Sie mit Teilen, die verschmierten, verblassten oder teilweise verdeckten Text aufweisen.
Wenn die Confidence-Werte durchgängig unter 80 % liegen, überprüfen Sie Ihre Bildeinstellungen erneut (Schritt 2). Die OCR-Genauigkeit ist direkt an die Bildqualität gebunden. Keine noch so gute Parameterabstimmung kann ein unscharfes oder schlecht beleuchtetes Bild ausgleichen.
Schritt 8: Pass/Fail-Regeln einrichten (IO Logic)
Nachdem OCR den Text korrekt erkennt, müssen Sie definieren, was ein Pass oder Fail ausmacht. Navigieren Sie zum Tab IO Logic.
Basic Mode
Basic Mode bietet eine einfache regelbasierte UI für die OCR-Pass/Fail-Logik. Kenntnisse in Node-RED sind nicht erforderlich.
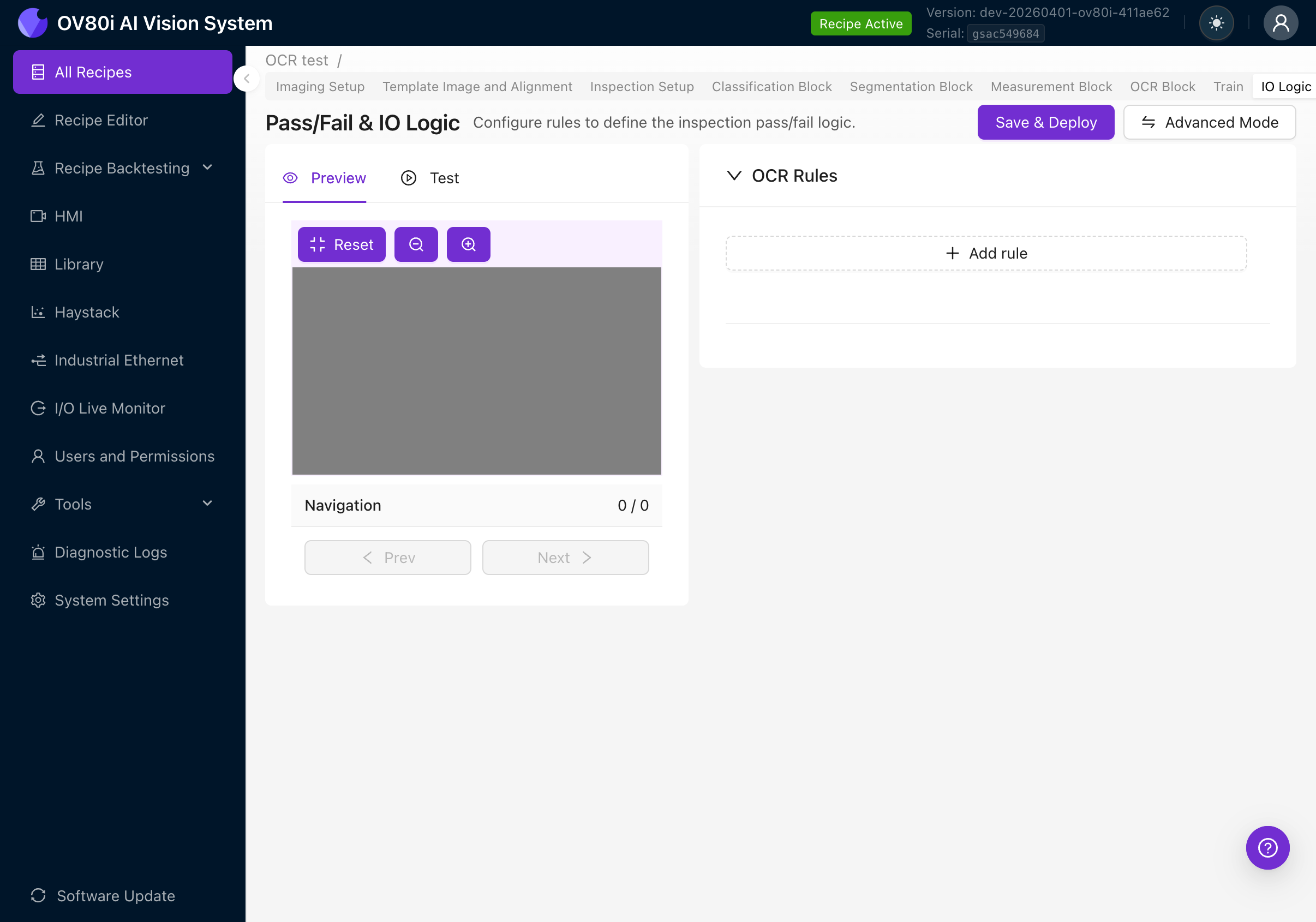
Die Seite zeigt:
- Preview / Test-Tabs auf der linken Seite (zur Visualisierung der Ergebnisse gegenüber Ihren Regeln)
- Bereich OCR Rules auf der rechten Seite
- Schaltfläche Save & Deploy zum Aktivieren der Regeln
- Schaltfläche Advanced Mode, um zu Node-RED zu wechseln
Erstellen einer Regel
Klicken Sie auf + Add rule, um eine Pass/Fail-Regel zu erstellen. Jede Regel hat drei Felder:
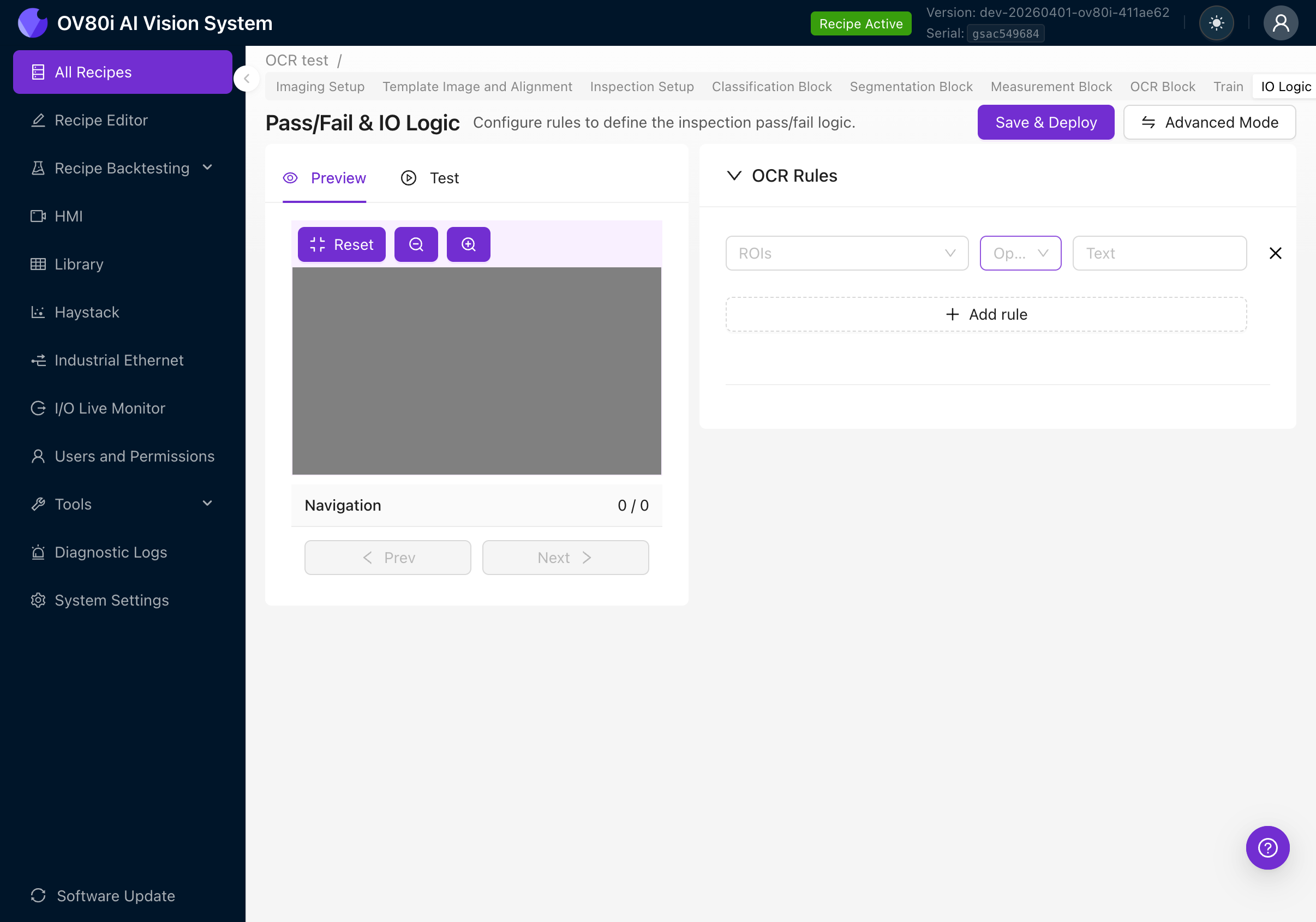
| Feld | Beschreibung |
|---|---|
| ROIs | Welche ROI(s) ausgewertet werden sollen. Klicken Sie zum Erweitern und wählen Sie "All ROIs" oder bestimmte Regionen aus. |
| Operator | Der Vergleich, der am erkannten Text durchgeführt werden soll. |
| Text | Die erwartete Textzeichenfolge, mit der verglichen werden soll. |
Verfügbare Operatoren
Klicken Sie auf das Operator-Dropdown, um alle vier Optionen anzuzeigen:
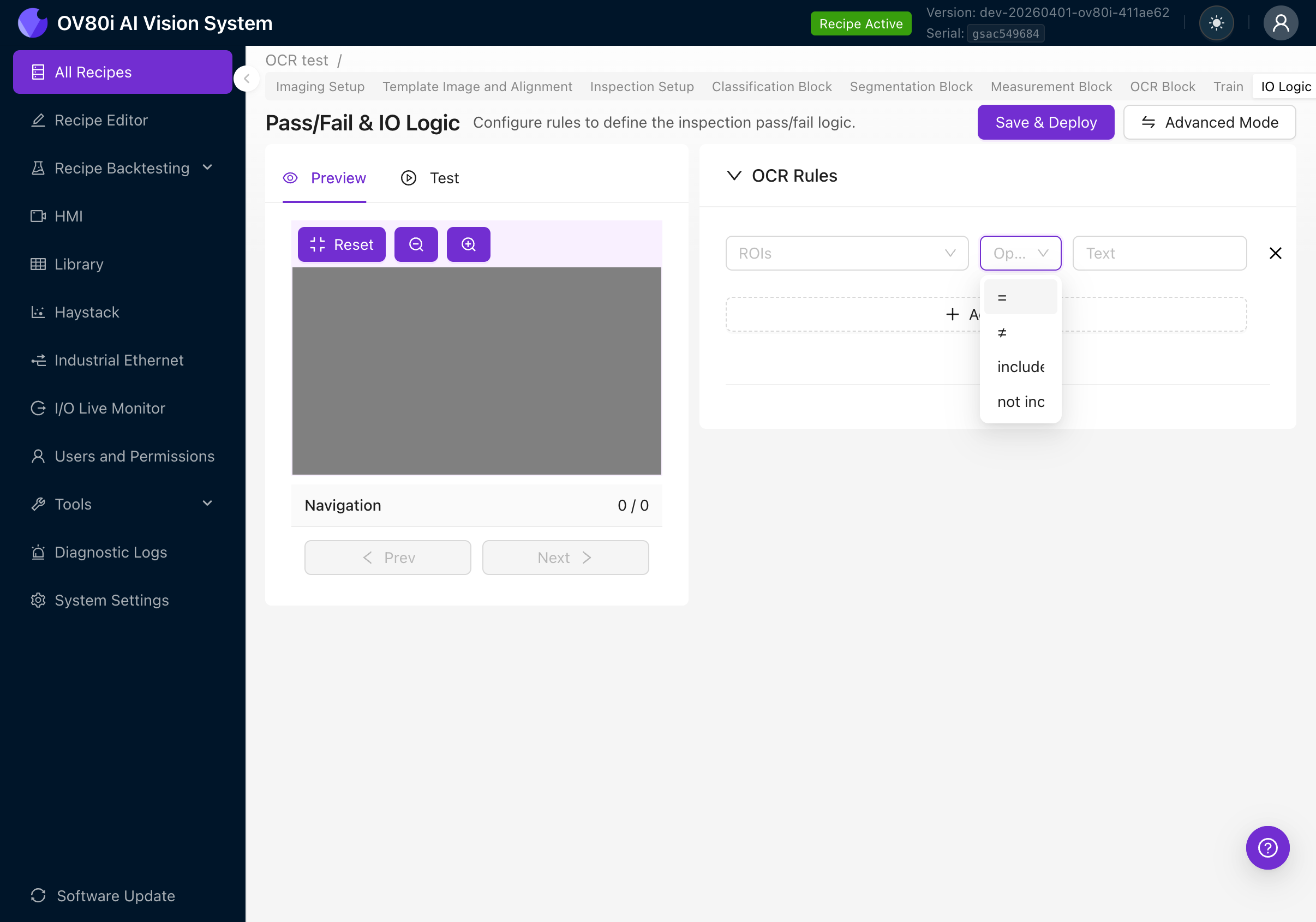
| Operator | Verhalten | Beispielanwendungsfall |
|---|---|---|
| = (equals) | Der gesamte erkannte, zusammengefügte Text muss exakt dem erwarteten Text entsprechen | Überprüfen, dass eine Seriennummer genau als "SN-2025-0042" gelesen wird |
| != (not equals) | Der zusammengefügte Text darf NICHT dem erwarteten Text entsprechen | Teile mit einem bekannten Fehlercode zurückweisen |
| includes | Der zusammengefügte Text muss den erwarteten Text als Teilzeichenfolge enthalten | Prüfen, dass ein Etikett irgendwo das Wort "SAFETY" enthält |
| not includes | Der zusammengefügte Text darf den erwarteten Text NICHT enthalten | Sicherstellen, dass ein veralteter Produktcode nicht erscheint |
Wie Text verglichen wird
Wenn eine ROI mehrere erkannte Textregionen enthält (z. B. erkennt der Detektor "LOT" und "2025" als separate Wörter), werden alle einzelnen Textstrings vor dem Vergleich mit Leerzeichen zusammengefügt.
Wenn der Detektor also drei Textregionen mit "LOT", "2025" und "A1" erkennt, wird der zusammengefügte Text zu "LOT 2025 A1". Ihre Regel vergleicht mit diesem vollständigen, zusammengefügten String.
Das bedeutet:
- Eine equals-Regel für
"LOT 2025 A1"würde bestehen - Eine includes-Regel für
"2025"würde bestehen - Eine equals-Regel für nur
"LOT"würde fehlschlagen (da der zusammengefügte Text mehr als nur "LOT" enthält)
Mehrere Regeln
Sie können weitere Regeln hinzufügen, indem Sie erneut auf + Add rule klicken. Alle Regeln verwenden UND-Logik: Jede Regel muss bestehen, damit die OCR-Prüfung besteht. Wenn eine einzelne Regel fehlschlägt, schlägt die gesamte Inspektion fehl.
ROI-Auswahl
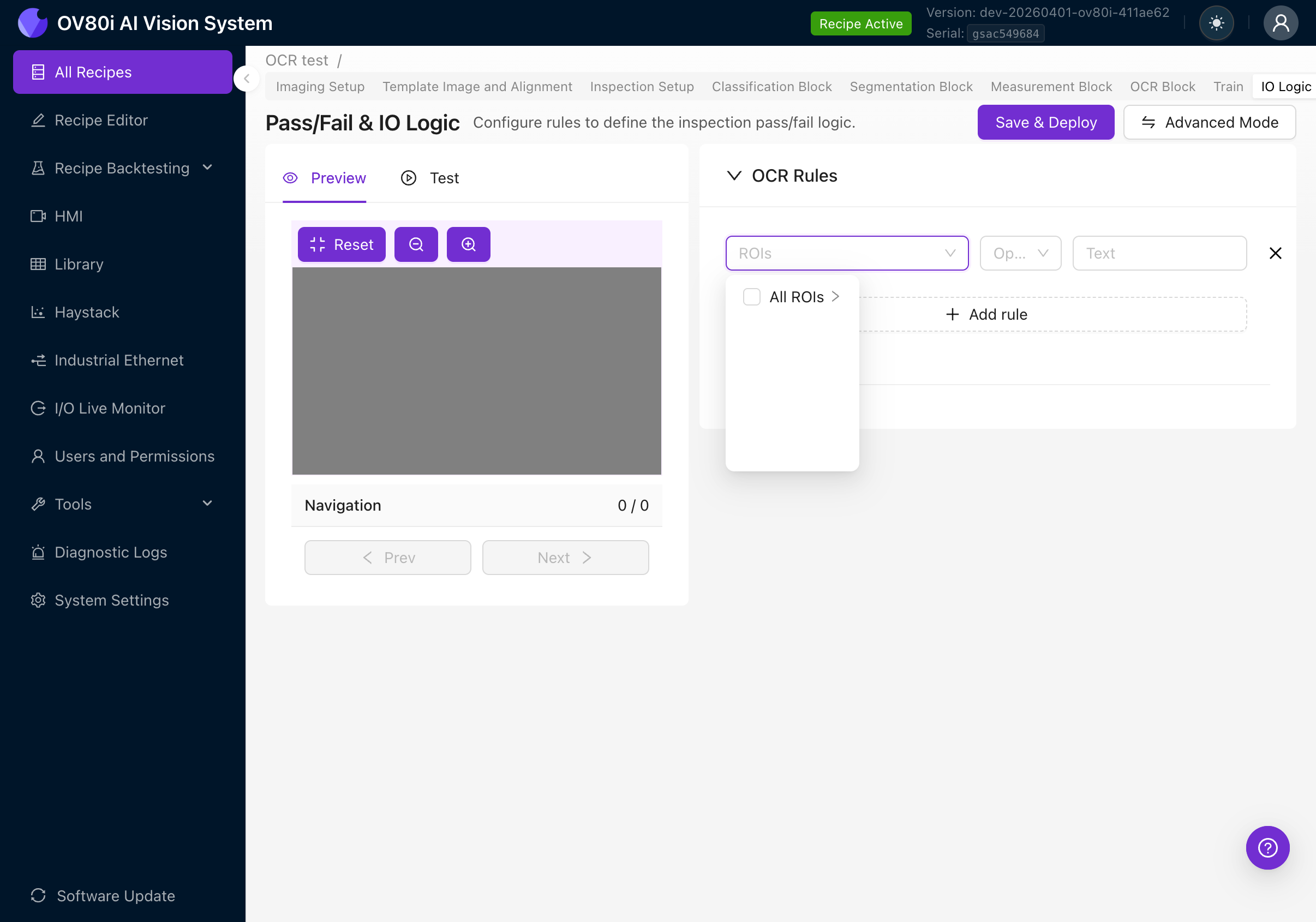
Klicken Sie auf das ROIs-Dropdown, um auszuwählen, auf welche Region(en) die Regel angewendet wird:
- All ROIs: Die Regel wertet Text aus allen OCR-Regionen zusammen aus
- Specific ROI: Erweitern, um einzelne ROIs nach Namen auszuwählen (deshalb ist eine aussagekräftige Benennung Ihrer ROIs in Schritt 4f wichtig)
Speichern und Bereitstellen
Nachdem Sie Ihre Regeln konfiguriert haben, klicken Sie auf Save & Deploy, um sie zu aktivieren. Die Regeln werden sofort für alle zukünftigen Inspektionen wirksam.
Advanced Mode (Node-RED)
Für komplexere Pass/Fail-Logik, die der Basic Mode nicht abbilden kann, wechseln Sie in den Advanced Mode.
Klicken Sie auf die Schaltfläche Advanced Mode, um einen Bestätigungsdialog anzuzeigen:
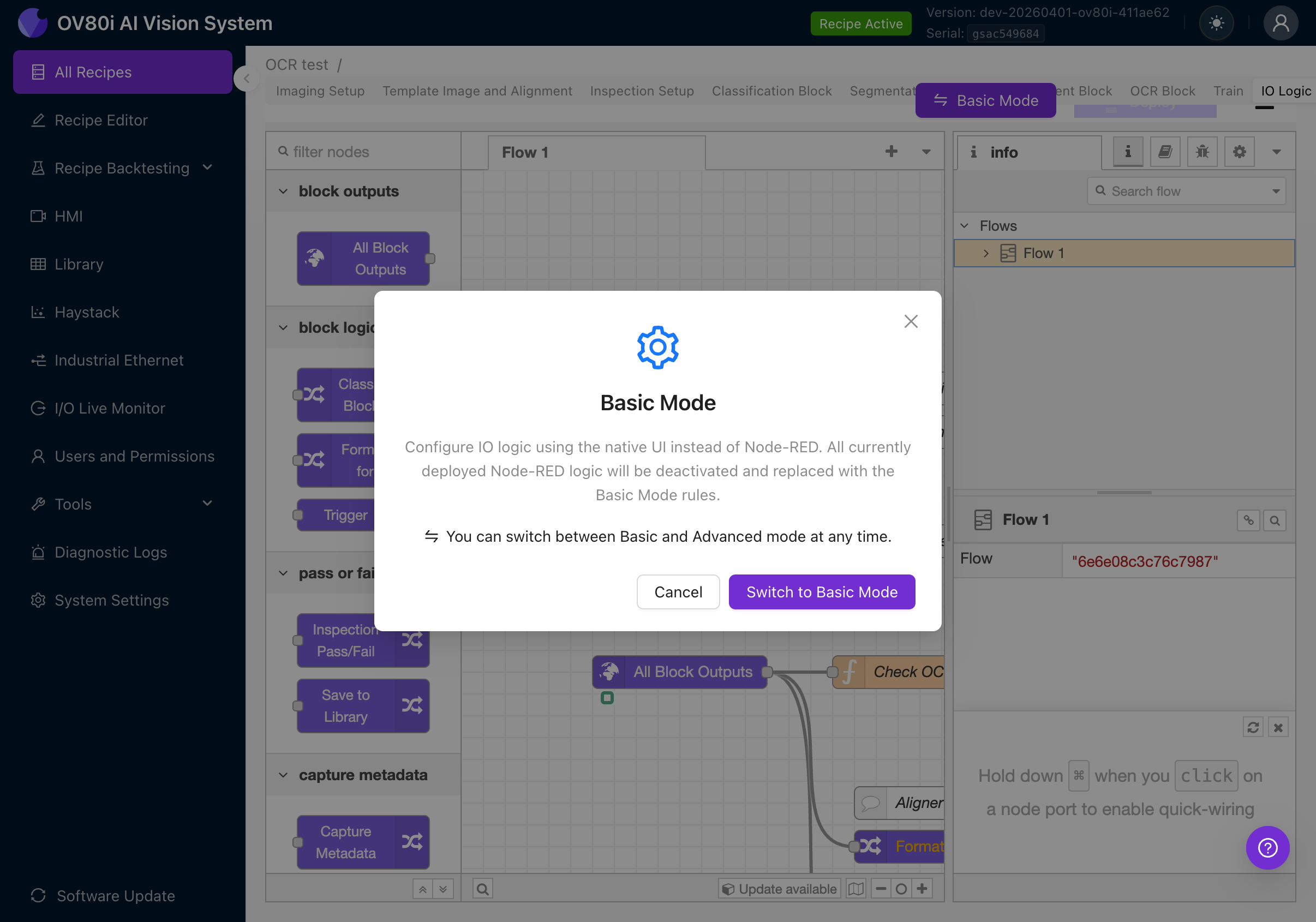
Der Dialog erklärt:
- Advanced Mode verwendet die vollständige visuelle Programmierumgebung von Node-RED
- Alle Basic Mode-Regeln werden deaktiviert
- Sie können jederzeit in den Basic Mode zurückwechseln
Klicken Sie auf Switch to Advanced Mode (oder, falls Sie bereits im Advanced Mode sind, lautet die Schaltfläche Basic Mode).
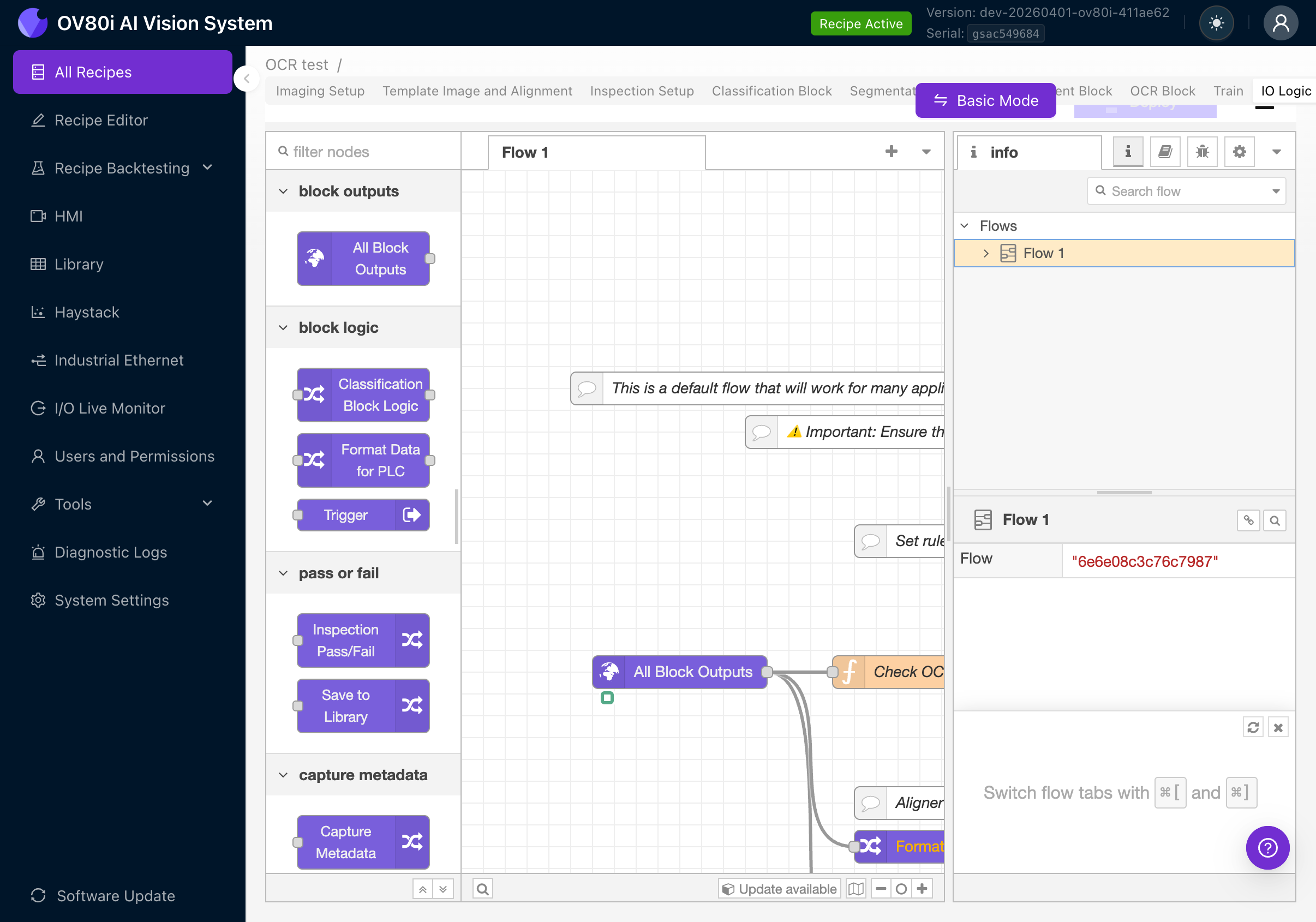
Im Advanced Mode sehen Sie eine Node-RED-Flow-Canvas mit vorgefertigten Nodes, darunter:
- All Block Outputs: Empfängt Ergebnisse von allen AI-Blöcken (Classification, Segmentation, OCR, Measurement)
- Check OCR (oder ähnlich): Ein Function-Node mit JavaScript, das OCR-Ergebnisse auswertet
- Classification Block Logic / Format Data for PLC / Trigger: Weitere Output-Nodes für die Integration
- Inspection Pass/Fail: Endgültige Pass/Fail-Bestimmung
- Save to Library: Speichert Ergebnisse
OCR-Ausgabe-Payload in Node-RED
Im Advanced Mode sind OCR-Ergebnisse im Objekt msg.payload.ocr verfügbar. Dies gibt Ihnen vollständigen programmatischen Zugriff auf jede Erkennung:
{
"predictions": [
{
"roi_id": 1,
"roi_name": "Serial Number",
"center_x_global": 450,
"center_y_global": 220,
"angle_global": 90,
"search_area_id": 1,
"detections": [
{
"text": "SN-2025-0042",
"confidence": 0.95,
"roi_bbox": {
"x": 10,
"y": 5,
"width": 120,
"height": 30,
"angle": 0
},
"global_bbox": {
"x": 450,
"y": 220,
"width": 120,
"height": 30,
"angle": 90
}
}
]
}
]
}
| Feld | Beschreibung |
|---|---|
| roi_id | Numerische ID der ROI, die dieses Ergebnis erzeugt hat |
| roi_name | Der Name, den Sie der ROI gegeben haben (z. B. "Serial Number") |
| center_x_global / center_y_global | Mittelpunktposition der ROI in Vollbildkoordinaten |
| angle_global | Rotationswinkel der ROI im Vollbild |
| search_area_id | Der Inspektionstyp / Suchbereich, zu dem diese ROI gehört |
| detections | Array einzelner Texterkennungen, die innerhalb dieser ROI gefunden wurden |
| detections[].text | Der erkannte Textstring |
| detections[].confidence | Erkennungskonfidenz von 0.0 bis 1.0 (begrenzt) |
| detections[].roi_bbox | Bounding-Box-Position relativ zum ROI-Zuschnittsursprung |
| detections[].global_bbox | Bounding-Box-Position im vollständigen Kamerabild (berücksichtigt ROI-Rotation und Ausrichtung) |
Verwenden Sie msg.payload.ocr.predictions[0].detections.map(d => d.text).join(" "), um denselben zusammengefügten Textstring zu erhalten, den der Basic Mode zum Vergleich verwendet.
Mit dem Advanced Mode können Sie:
- Regex-Muster mit JavaScript auf erkannten Text anwenden
- Erkennungen nach Konfidenzschwellwert filtern
- OCR-Ergebnisse mit Classification-/Segmentation-Ergebnissen für komplexe Logik kombinieren
- OCR-Text für die PLC-Ausgabe formatieren (z. B. die erkannte Seriennummer über EtherNet/IP senden)
- Benutzerdefinierte Nachrichten an Microsoft Teams oder per E-Mail basierend auf dem OCR-Inhalt senden
Eine ausführliche Anleitung zu Node-RED finden Sie unter Node-RED-Grundlagen.
Sie können jederzeit zwischen Basic und Advanced Mode wechseln, indem Sie die Umschaltfläche oben auf der IO Logic-Seite verwenden. Beim Wechsel in den Basic Mode wird die bereitgestellte Node-RED-Logik deaktiviert und durch Basic Mode-Regeln ersetzt. Beim Zurückwechseln wird der Node-RED-Flow wiederhergestellt.
Schritt 9: Rezept bereitstellen
Sobald Ihre OCR-Einrichtung abgeschlossen und getestet ist:
- Navigieren Sie zurück zum Recipe Editor (klicken Sie in der linken Seitenleiste auf Recipe Editor)
- Klicken Sie unten rechts auf die violette Schaltfläche Deploy Recipe
- Das Rezept ist nun aktiv und führt Inspektionen durch
Ergebnisse anzeigen
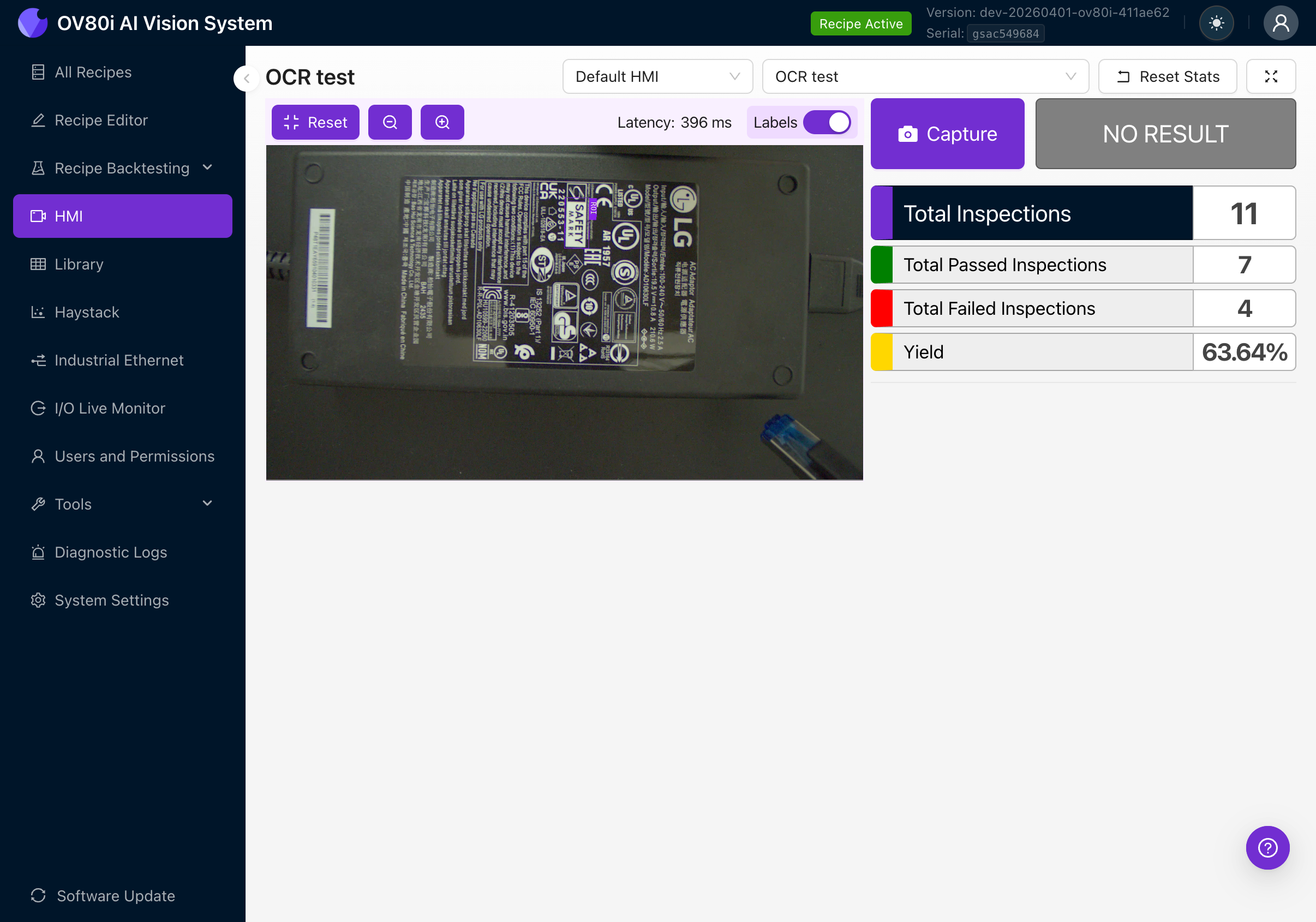
HMI
Die HMI-Seite zeigt Live-Inspektionsergebnisse an. Bei aktivem OCR sehen Sie:
- Den Live-Kamerafeed mit violetten Begrenzungsrahmen um den erkannten Text
- Textbeschriftungen, die anzeigen, was gelesen wurde
- Pass/Fail-Status basierend auf Ihren IO Logic-Regeln
- Laufende Statistiken: Gesamtinspektionen, bestanden, fehlgeschlagen, Ausbeuteprozentsatz
Library
Navigieren Sie in der linken Seitenleiste zu Library, um gespeicherte Ergebnisse vergangener Aufnahmen zu überprüfen. Jeder Aufnahmeeintrag zeigt:
- Das aufgenommene Bild mit OCR-Overlay
- Erkannten Text pro ROI
- Konfidenzwerte
- Pass/Fail-Ergebnis
Fehlerbehebung
Kein Text erkannt
| Mögliche Ursache | Lösung |
|---|---|
| ROI nicht über Text positioniert | Positionieren Sie die ROI im Inspection Setup neu |
| ROI-Ausrichtung stimmt nicht mit Text überein | Drehen Sie die ROI, um sie an der Textrichtung auszurichten (Schritt 4d) |
| Text im Bild zu klein | Bringen Sie die Kamera näher heran oder verwenden Sie ein Objektiv mit längerer Brennweite |
| Text im Verhältnis zur ROI zu klein | Ziehen Sie die ROI enger um den Textbereich |
| Min Text Area zu hoch | Verringern Sie den Parameter Min Text Area |
| Schlechte Beleuchtung / geringer Kontrast | Verbessern Sie die Beleuchtung, um den Kontrast zwischen Text und Hintergrund zu maximieren |
| Text ist unscharf | Passen Sie den Fokus am C-Mount-Objektiv an und prüfen Sie, ob die Kamerahalterung stabil ist |
| Alignment nicht eingerichtet | Die Texterkennung erfordert Alignment. Richten Sie das Template-Alignment ein (Schritt 3) |
Falscher Text erkannt (Lesefehler)
| Mögliche Ursache | Lösung |
|---|---|
| ROI-Ausrichtung stimmt nicht mit Textausrichtung überein | Dies ist die häufigste Ursache. Drehen Sie die ROI, um sie an der Textrichtung auszurichten (Schritt 4d) |
| Geringe Bildqualität oder Rauschen | Belichtung erhöhen, Gain reduzieren, Beleuchtung verbessern |
| Text Segmentation Threshold zu niedrig | Erhöhen Sie den Wert, um Falscherkennungen zu filtern |
| Überlappende Textbereiche werden zu einer Erkennung zusammengeführt | Verringern Sie den Unclip Ratio, um das Zusammenführen von Rahmen zu verhindern |
| Mehrere Textzeilen in einer ROI | Erstellen Sie separate ROIs für jede Zeile, wenn die Lesereihenfolge wichtig ist |
OCR-Konfidenz ist durchgängig niedrig
| Mögliche Ursache | Lösung |
|---|---|
| Ungleichmäßige Beleuchtung | Sorgen Sie für eine gleichmäßige Ausleuchtung des Textbereichs |
| Blendung oder Reflexionen auf Text (besonders bei glänzenden Etiketten) | Passen Sie den Beleuchtungswinkel an, um Spiegelreflexionen zu vermeiden. Erwägen Sie diffuse Beleuchtung. |
| Sehr kleine oder stark stilisierte Schrift | Bringen Sie die Kamera näher heran oder verwenden Sie ein Objektiv mit längerer Brennweite, um die Textgröße im Bild zu vergrößern |
| Beschädigter, verblasster oder teilweise gedruckter Text | OCR kann nur lesen, was die Kamera sieht. Bei physisch degradiertem Text ist die Genauigkeit geringer. |
| Hoher Gain in den Bildeinstellungen | Reduzieren Sie den Gain. Hoher Gain erzeugt Rauschen, das wie Textartefakte aussieht. |
Pass/Fail-Regeln funktionieren nicht wie erwartet
| Mögliche Ursache | Lösung |
|---|---|
| Text wird anders zusammengefügt als erwartet | Aktivieren Sie Live Preview und prüfen Sie genau, welcher Text erkannt wird. Beachten Sie: Mehrere Erkennungen werden mit Leerzeichen verbunden. |
| Verwendung von "equals", wenn "includes" passender wäre | Wenn nur ein Teilstring relevant ist, verwenden Sie "includes" statt "equals" |
| Regeln nicht bereitgestellt | Klicken Sie nach dem Ändern von Regeln im Basic Mode auf Save & Deploy |
| Falsche ROI in der Regel ausgewählt | Prüfen Sie das ROIs-Dropdown in Ihrer Regel, um sicherzustellen, dass der richtige Bereich adressiert wird |
Einschränkungen
- Maximal 1 OCR-Block pro Rezept (innerhalb dieses Blocks können mehrere ROIs vorhanden sein)
- Nur für Englisch optimiertes Modell: Das vortrainierte Modell ist für gedruckten Text auf lateinischer Basis optimiert. Handschrift, Kursivschrift oder nicht-lateinische Schriften (Chinesisch, Japanisch, Koreanisch, Arabisch) werden nicht unterstützt.
- Kein Regex oder Pattern Matching im Basic Mode: Pass/Fail-Regeln verwenden einfache String-Vergleiche (equals, not equals, includes, not includes). Für komplexe Validierungsmuster (z. B. Abgleich mit "SN-####-####") verwenden Sie den Advanced Mode (Node-RED) mit benutzerdefiniertem JavaScript-Regex.
- Kein benutzerkonfigurierbarer Zeichensatz: Das 480-Zeichen-Wörterbuch des Modells ist fest vorgegeben. Sie können die Erkennung beispielsweise nicht auf reine Ziffern beschränken. Verwenden Sie Pass/Fail-Regeln, um das erwartete Format zu validieren.
- Keine garantierte Textreihenfolge: Wenn innerhalb eines ROI mehrere Textbereiche erkannt werden, werden diese in Erkennungsreihenfolge (nach Kontur) zusammengefügt, nicht zwingend in Leserichtung (von links nach rechts, von oben nach unten). Wenn die Lesereihenfolge wichtig ist, verwenden Sie separate ROIs für jede Textzeile.
- Nur vortrainiertes Modell: Im Gegensatz zu Klassifikation und Segmentierung kann das OCR-Modell nicht auf Ihre spezifischen Schriftarten oder Textstile neutrainiert oder feinabgestimmt werden. Es verwendet das integrierte vortrainierte OCR-Modell.
Siehe auch
- Erste Inspektion erstellen – Vollständige Anleitung zur Rezepterstellung
- Bildeinstellungen – Detaillierter Leitfaden zur Bildkonfiguration
- Ausrichtung – Vertiefung zur Vorlagenausrichtung
- Regions of Interest (ROIs) – ROI-Dimensionierung und -Strategie
- Inspektionseinrichtung und ROI-Typen – ROI-Typ-Referenz
- Node-RED Grundlagen – Programmierung erweiterter IO-Logik
- Grundlagen der Bildkonfiguration – Theorie zu Beleuchtung und Bildqualität