KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
Schritt 4: KI-Modell trainieren
Ihre Regions of Interest (ROIs) sind definiert. Jetzt ist es an der Zeit, der KI beizubringen, wie "gut" und "schlecht" aussehen.
Die drei wichtigsten Regeln des Trainings
Bevor Sie irgendetwas anderes tun, verinnerlichen Sie diese drei Regeln. Sie gelten unabhängig davon, ob Sie einen Classifier oder einen Segmenter trainieren, mit 5 oder 500 Bildern.
Regel 1: Labeln Sie ausschließlich anhand des Bildes
Niemals das physische Teil betrachten (oder es unter ein Mikroskop legen), um zu entscheiden, ob es gut oder schlecht ist. Wenn Sie den Defekt im Kamerabild nicht sehen können, kann die KI ihn auch nicht lernen.
Die KI ist keine Magie. Sie kann nur mit dem arbeiten, was die Kamera sieht. Wenn Sie ein Teil als "defekt" labeln, weil Sie beim Berühren oder Vergrößern unter einer Lupe etwas bemerkt haben, das Kamerabild aber in Ordnung aussieht, bringen Sie der KI bei, etwas zu sehen, das nicht da ist.
Wenn Sie es nicht allein anhand des Bildes labeln können, kehren Sie zum Schritt Install zurück und korrigieren Sie den physischen Aufbau: besseres Objektiv, bessere Beleuchtung, nähere Montage, anderer Winkel.
Regel 2: Überprüfen Sie Ihre Labels doppelt und dreifach
Fehl-Labels passieren jedem; auch erfahrenen Ingenieuren. Aber ein einziges falsches Label in einem kleinen Datensatz kann Ihre Ergebnisse zerstören.
Bei 5 Trainingsbildern beschädigt ein Fehl-Label 20 % Ihrer Trainingsdaten. Das ist katastrophal.
Vor jedem Trainingslauf: Klicken Sie auf View All ROIs und überprüfen Sie jede einzelne Annotation. Dies ist die einfachste und wirkungsvollste Maßnahme.
Regel 3: Klein anfangen, schnell iterieren
Labeln Sie nicht 50 Bilder und starten dann das Training. Erstellen Sie stattdessen einen engen Zyklus: Labeln Sie 10–15 Bilder pro Klasse, trainieren Sie (ca. 30 Sekunden), testen Sie und versuchen Sie, das Modell zu "knacken", und fügen Sie dann gezielt Daten dort hinzu, wo es versagt. Wiederholen Sie diesen Zyklus 2–4 Mal.
Dieser Zyklus ist Ihr schnellster Weg zu einem guten Modell.
Schritt-für-Schritt-Trainings-Workflow
1. Erste Trainingsbilder aufnehmen
Mit aktivem Rezept und laufenden (oder manuell platzierten) Teilen nehmen Sie Bilder auf. Sie benötigen mindestens 10–15 Bilder pro Klasse, um zu beginnen.
Für eine einfache Pass/Fail-Inspektion:
- 10–15 Bilder von guten Teilen
- 10–15 Bilder von defekten Teilen
2. Klassen definieren
Wählen Sie den Modelltyp aus, den Sie trainieren, und lesen Sie dann die entsprechenden Anweisungen. Der Umschalter unten bleibt zwischen Schritt 2 und Schritt 3 synchronisiert, und Ihre Auswahl wird in der URL gespeichert, sodass sie nach einer Aktualisierung oder beim Teilen erhalten bleibt.
- Classifier
- Segmenter
Fügen Sie in der Labeling-Oberfläche die Klassen hinzu, die jeder Inspektionstyp benötigt. Übliche Classifier-Klassensätze:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
Halten Sie es anfangs einfach. Sie können später jederzeit weitere Klassen hinzufügen.
Fügen Sie in der Labeling-Oberfläche Klassen für die Defekte (oder Merkmale) hinzu, die die KI maskieren soll. Übliche Segmenter-Klassensätze:
- Defect / Background
- Scratch / Crack / Stain
- Foreground / Background
Halten Sie die Klassenliste anfangs kurz. Jede Klasse benötigt ihre eigene Pinselfarbe und ihre eigenen gelabelten Beispiele, sodass das Hinzufügen weiterer Klassen von Anfang an Ihren Labeling-Aufwand vervielfacht.
3. Bilder labeln
- Classifier
- Segmenter
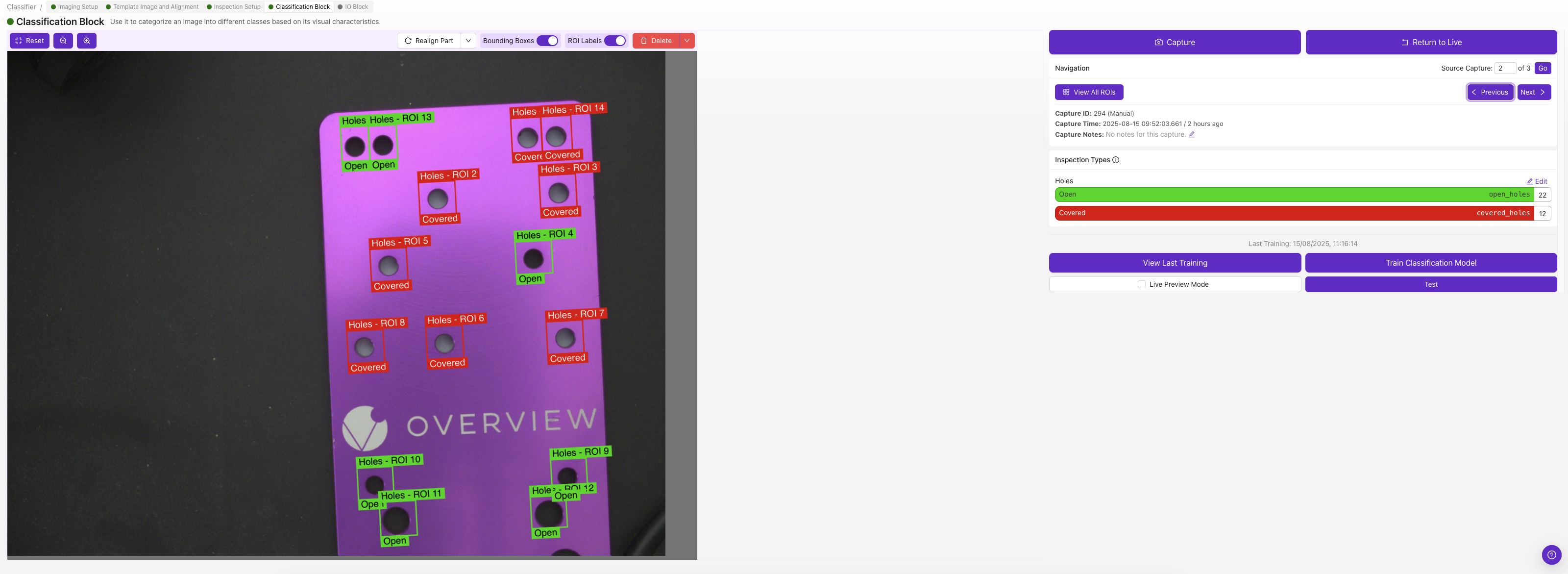
Jede ROI erhält ihre eigene Klassifizierungsklasse — wählen Sie die Klasse, die diese ROI in diesem Bild beschreibt (z. B. „pass" oder „fail").
Wenn Sie unsicher sind, ob Sie Classification oder Segmentation verwenden sollen, beginnen Sie mit Classification. Das Labeling ist deutlich schneller und für die meisten Pass/Fail-Szenarien gut geeignet. Siehe Classifier vs. Segmenter für weitere Hinweise.
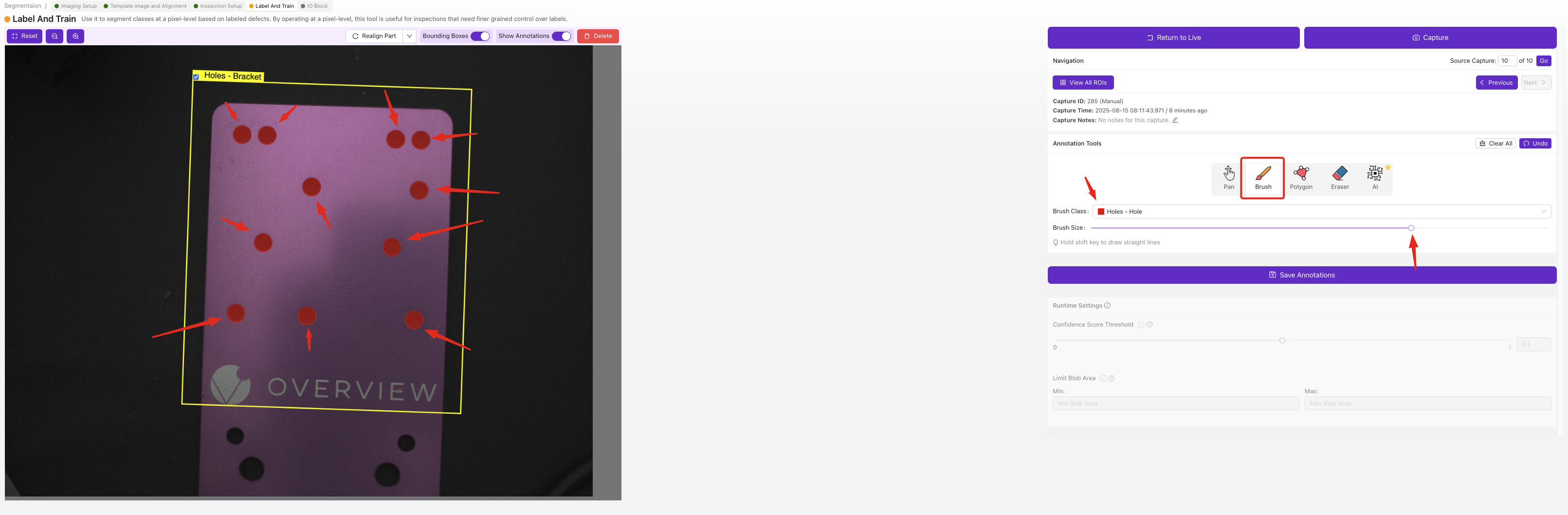
Verwenden Sie für jede ROI in jedem Bild das Pinselwerkzeug, um die defekten Bereiche Pixel für Pixel einzufärben. Die eingefärbten Regionen sind das, was die AI zu erkennen lernt — alles, was Sie nicht einfärben, wird als Hintergrund behandelt.
Segmenter-Labels erfordern pixelgenaue Pinselarbeit, was langsamer ist als Classifier-Dropdown-Auswahlen, liefert Ihnen aber präzise Defektkarten mit Position und Form. Beginnen Sie mit einer kleinen Menge klar definierter Defekte und fügen Sie erst weitere Klassen hinzu, wenn Ihr erstes Modell funktioniert.
4. Modell trainieren
- Classifier
- Segmenter
Klicken Sie auf Train. Der Classifier bietet zwei Trainingsmodi:
- Fast mode — etwa 30 Sekunden bis eine Minute. Am besten für schnelle Iteration während der Einrichtung, zur Plausibilitätsprüfung Ihrer Labels und für einfache/gut trennbare Teile. Die Genauigkeit ist geringer als im Production mode, aber Sie sehen schnell das Signal.
- Production mode — dauert länger, erzeugt aber ein deutlich genaueres Modell. Verwenden Sie vor dem Deployment auf die Linie immer den Production mode. Für schwierige Teile, schwer zu unterscheidende Defekte oder alles, worauf Sie sich in der Produktion verlassen wollen, ist der Production mode die richtige Wahl.
Ein bewährter Rhythmus: Iterieren Sie im Fast mode, während Sie Labels bereinigen und Daten hinzufügen, und führen Sie Production aus, sobald das Ergebnis gut aussieht — und nochmals vor dem Deployment.
Klicken Sie auf Train. Segmentation hat nur einen Trainingsmodus — Production — denn pixelgenaue Masken benötigen den gründlicheren Trainingsdurchlauf, um zuverlässig zu sein. Die Trainingsdauer skaliert mit der Anzahl der Bilder und der Anzahl der gelabelten ROIs — ein kleines Anfangsset (10–15 Bilder pro Klasse) trainiert in wenigen Minuten; größere Datensätze dauern länger.
Es gibt hier keine „schnelle" Plausibilitätsprüfungsoption, daher stellen Sie sicher, dass Ihre Labels sauber sind, bevor Sie trainieren (verwenden Sie View All ROIs, um jede Maske zu überprüfen).
Segmenter lernen nur die Größe und Textur der Defekte, die ihnen gezeigt wurden. Wenn Ihr Trainingsset nur kleine Verunreinigungen enthält und dann in der Produktion ein großes Stück derselben Defektklasse ankommt, umrandet das Modell nur die Bereiche des großen Defekts, die den kleinen Beispielen ähneln — der Großteil bleibt unerfasst. Die Maske wirkt fleckig oder markiert nur Kanten und Ecken des tatsächlichen Defekts.
Lösung: Nehmen Sie Trainingsbeispiele auf, die den gesamten Bereich der Defektgrößen abdecken, den Sie an der Linie erwarten. Eine Handvoll Aufnahmen großer Verunreinigungen neben Ihren kleinen reicht in der Regel aus. Dasselbe Prinzip gilt für Textur- und Farbvariationen — trainieren Sie auf der Vielfalt, die Sie sehen werden.
Keine Proben großer Defekte vorhanden? Verwenden Sie das Defect Creator Studio, um synthetische Trainingsbilder desselben Defekts in unterschiedlichen Größen, Positionen und Orientierungen zu generieren — Sie müssen nicht warten, bis eine echte große Verunreinigung an der Linie eintrifft.
5. Test mit Live-Vorschau
Klicken Sie auf Live Preview Mode und führen Sie Teile durch das System. Beobachten Sie die Ergebnisse:
- Werden einfache Fälle korrekt erkannt?
- Wo treten Schwierigkeiten auf?
- Welche Grenzfälle gibt es?
Versuchen Sie, das Modell an seine Grenzen zu bringen. Finden Sie die Fälle, in denen es versagt. Diese Fehler sind Ihr Fahrplan für Verbesserungen.
- Classifier
- Segmenter

Das Test-Panel zeigt die vorhergesagte Klasse und den Konfidenzwert für jede ROI an. Führen Sie einige Aufnahmen durch und achten Sie auf Bewertungen mit niedriger Konfidenz (häufig unter 70 %) — das sind Ihre Grenzfälle und die Teile, die als Nächstes am ehesten gelabelt werden sollten.
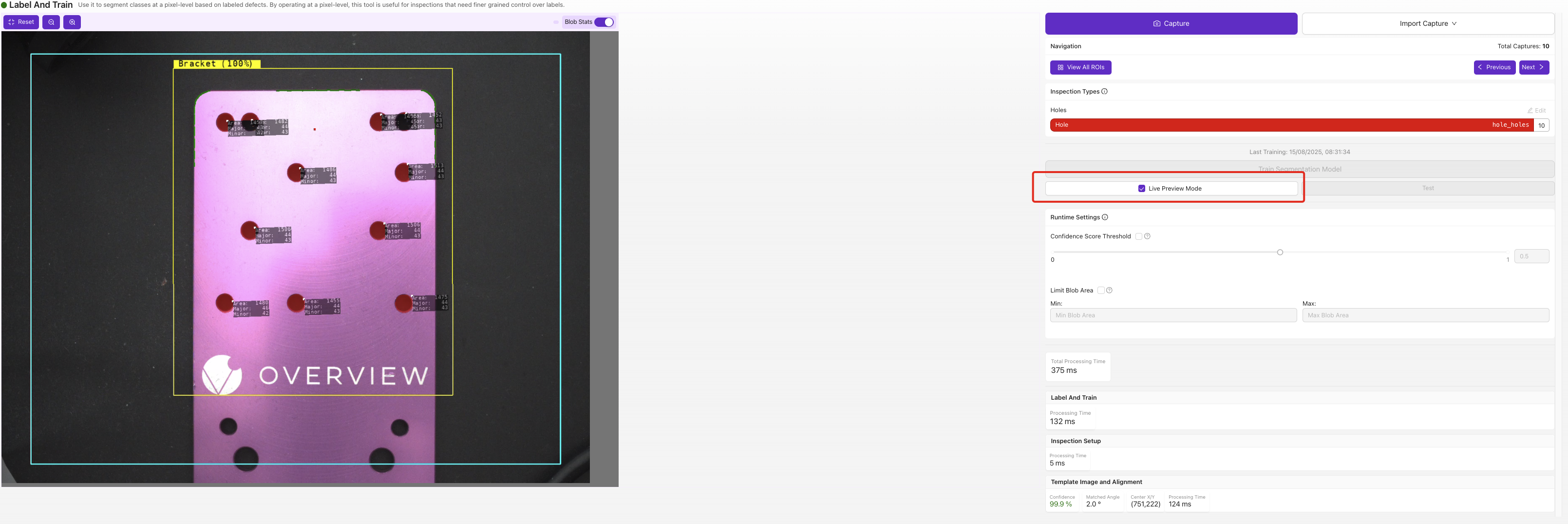
Die Live-Vorschau blendet die vorhergesagte Defektmaske direkt über das Bild ein. Achten Sie auf Masken, die zu klein oder zu groß sind oder dort erscheinen, wo kein tatsächlicher Defekt vorliegt — das sind die Fehlerfälle, auf die Sie mit der nächsten Runde gelabelter Daten abzielen sollten.
6. Gezielte Daten hinzufügen
Fügen Sie nicht wahllos neue Bilder hinzu. Ergänzen Sie gezielt Bilder, die die gefundenen Fehlerfälle adressieren:
- Wenn Kratzer mit Reflexionen verwechselt werden, fügen Sie mehr Beispiele für beides hinzu
- Wenn kleine Defekte übersehen werden, fügen Sie mehr Bilder kleiner Defekte hinzu
- Wenn Teile in den Ecken nicht erkannt werden, fügen Sie mehr Beispiele aus den Ecken hinzu
7. Erneut trainieren und testen
Wiederholen Sie die Schritte 4–6 zwei- bis viermal. Mit jeder Iteration sollte sich die Genauigkeit verbessern. Eine ausführlichere Anleitung — einschließlich, wie Sie neue Bilder zu einem bestehenden Modell hinzufügen, ohne Ihr bisheriges Training zu verlieren — finden Sie unter Daten hinzufügen & Nachtrainieren.
Augmentations: Der KI beibringen, mit Variationen umzugehen
Augmentations modifizieren Ihre Trainingsbilder während des Trainingsprozesses zufällig — sie passen Helligkeit an, fügen Rotation hinzu, verändern den Kontrast usw. Jedes Bild wird der KI hunderte Male mit leicht unterschiedlichen Augmentations zugeführt, das Label bleibt jedoch gleich. So machen Sie ein Modell robust gegenüber realen Bedingungen, ohne ein Beispiel jeder möglichen Variation aufnehmen zu müssen.
Was standardmäßig aktiviert werden sollte
Eine geringe Helligkeitsvariation lohnt sich fast immer — selbst die kontrollierteste Fabrik hat Deckenbeleuchtung, die flackert, Schatten, die sich im Laufe der Schicht verschieben, und geringfügige LED-Drift über die Zeit. Helligkeits-Augmentation macht das Modell praktisch ohne Aufwand widerstandsfähig gegen all dies.
Rotation: nützlich, aber auf die ROI-Form achten
Rotations-Augmentation ist hervorragend geeignet, wenn Ihre Teile tatsächlich in verschiedenen Winkeln ankommen können (lose Schrauben auf einem Förderband, von Hand platzierte Teile, alles, was nicht in einer Vorrichtung fixiert ist). Sie interagiert jedoch mit der ROI-Form:
- Quadratische ROI: Rotations-Augmentation funktioniert sauber — das gedrehte Bild passt weiterhin in das ROI-Feld.
- Nicht-quadratische ROI bei einem Classifier: Die Rotation kann das Bild abschneiden. Wenn eine hohe, schmale ROI um 45° gedreht wird, fallen die Ecken des gedrehten Inhalts außerhalb des Feldes, und das Modell trainiert auf einem unvollständigen Bild. Wenn Ihr Teil rotieren kann, machen Sie die ROI entweder quadratisch oder verlassen Sie sich auf den Aligner, um die Rotation vorgelagert zu handhaben, sodass Sie hier keine Rotations-Augmentation benötigen.
- Segmenter: Das gleiche Problem mit dem Abschneiden besteht, aber die Segmentierung ist weniger empfindlich, da sie aus Pixelmasken und nicht aus der gesamten ROI-Form lernt.
Wann eine bestimmte Augmentierung NICHT verwendet werden sollte
Die allgemeine Regel: Augmentieren Sie nicht die Eigenschaft, die Sie prüfen. Wenn Sie die Ausrichtung erkennen möchten, lehrt eine Rotations-Augmentierung das Modell, dass auf dem Kopf stehende Teile immer noch „gut" sind.
- Prüfung auf Farbkonsistenz? Keine Sättigungs-Augmentierung verwenden.
- Prüfung auf Unschärfe/Fokus? Keine Bewegungsunschärfe-Augmentierung verwenden.
- Prüfung auf Ausrichtung? Keine Rotations-Augmentierung verwenden (und wahrscheinlich auch nicht den Aligner).
Datenvielfalt ist entscheidend
Ihre Trainingsdaten sollten das gesamte Spektrum dessen abbilden, was die KI in der Produktion sehen wird:
- Verschiedene Tageszeiten (bei wechselnder Beleuchtung)
- Verschiedene Teile-Chargen (Oberflächenbeschaffenheit kann leicht variieren)
- Teile in unterschiedlichen Positionen im Bildausschnitt
- Sowohl einfache als auch schwierige Fälle
Konzentrieren Sie sich auf die schwierigsten Fälle. Wenn Ihre Trainingsdaten die 10 am schwersten zu klassifizierenden Teile enthalten, sind die 90 % der einfachen Teile für die KI trivial.
Hohe Lernkapazität
Die KI der OV-Kamera ist darauf ausgelegt, sich mit mehr Daten kontinuierlich zu verbessern. Im Gegensatz zu vielen KI-Systemen, die nach 20 Bildern stagnieren, verbessert sich dieses Modell auch mit 50, 100 oder sogar über 500 Bildern weiter. Die meisten Prüfungen funktionieren bereits mit 5–10 Bildern hervorragend, aber bei komplexen Problemen mit mehreren Defekten sollten Sie nicht zögern, weitere Daten hinzuzufügen.
Beschleunigen mit synthetischen Daten: Defect Studio
Was tun, wenn Sie für einen Defekt trainieren müssen, den Sie selten sehen? Eine fehlende Schraube, die Sie absichtlich entfernen müssten, einen Kratzer, den Sie erst erzeugen müssten, einen Riss, der einmal pro tausend Teile auftritt? Monatelang darauf zu warten, genügend Beispiele zu sammeln, ist nicht praktikabel.
Das OV Auto-Defect Creator Studio unter tools.overview.ai löst dieses Problem. Es generiert fotorealistische synthetische Defektbilder – bis zu 10.000-mal schneller als das Warten auf reale Defekte in der Produktionslinie.
So funktioniert es: 5 einfache Schritte
- Laden Sie ein gutes Bild Ihres Teils hoch
- Markieren Sie den Bereich, in dem der Defekt erscheinen soll
- Beschreiben Sie den Defekt in einfachem Englisch (z. B. „deep scratch across the surface" oder „missing solder joint")
- Generieren Sie die Defektvarianten (die KI erstellt fotorealistische Ergebnisse)
- Exportieren Sie die synthetischen Bilder direkt in Ihr Trainingsset
Warum synthetische Daten funktionieren
Die generierten Bilder sind keine bloß „aufgeklebten" Artefakte. Es handelt sich um fotorealistische Variationen, die zu Ihrer tatsächlichen Beleuchtung, Ihrem Kamerawinkel und Ihrer Teileoberfläche passen. Die KI versteht die Physik dahinter, wie Defekte unter Ihren spezifischen Bildgebungsbedingungen aussehen.
Anwendungsfälle:
- Seltene Defekte: Trainieren Sie für Fehlerarten, die Sie noch nie (oder selten) gesehen haben
- Neue Produkteinführungen: Erstellen Sie eine Prüfung, bevor das erste defekte Teil vom Band läuft
- Grenzfälle: Generieren Sie grenzwertige Beispiele, um die Entscheidungsgrenze der KI zu verbessern
- Daten-Augmentierung: Ergänzen Sie kleine Datensätze mit synthetischer Vielfalt
Sehen Sie es in Aktion
Der beste Ansatz: Trainieren Sie zunächst mit Ihren ersten 3–5 echten Bildern, identifizieren Sie, wo die KI Schwierigkeiten hat, und verwenden Sie dann Defect Studio, um gezielt synthetische Beispiele für diese spezifischen Fehlerarten zu generieren. Echte Daten vermitteln die Grundlage; synthetische Daten füllen die Lücken.
Trainings-Checkliste
Bevor Sie fortfahren, bestätigen Sie:
- Erste Bilder aufgenommen, mindestens 10-15 pro Klasse
- Alle Labels doppelt überprüft (View All ROIs)
- Mit Live Preview trainiert und getestet
- Fehlermodi identifiziert und gezielte Daten hinzugefügt
- 2-4 Iterationen von Labeln → Trainieren → Testen abgeschlossen
- Ergebnisse entsprechen den Erwartungen
Modell trainiert und sieht gut aus? Weiter zu Schritt 5: Einrichten der Ausgaben.