AI 驅動文件
您想了解什麼?
第四步:訓練您的 AI 模型
您的感興趣區域(ROI)已設定好。現在是時候教 AI 識別什麼是"好"和什麼是"壞"了。
訓練的三條基本規則
在做任何事之前,請牢記這三條規則。無論您是訓練分類器還是分割器,無論使用 5 張影象還是 500 張影象,這些規則都適用。
規則 1:僅根據影象進行標註
絕不要透過檢視實際零件(或將其置於顯微鏡下)來判斷它是好是壞。如果您在相機影象中看不到缺陷,AI 就無法學習它。
AI 不是魔法。它只能基於相機所見的內容進行工作。如果您因為觸控或用放大鏡放大後發現了某些問題而將零件標記為"有缺陷",但相機影象看起來正常,那麼您就是在教 AI 識別根本不存在的東西。
如果您僅憑影象無法標註,請返回到安裝步驟並修復物理設定:更好的鏡頭、更好的照明、更近的安裝距離或不同的角度。
規則 2:反覆檢查您的標籤
錯誤標註每個人都會發生;經驗豐富的工程師也會犯這種錯誤。但在小資料集中,一個錯誤的標籤可能會毀掉您的結果。
在 5 張訓練影象中,一個錯誤標註會汙染**20%**的訓練資料。這是災難性的。
每次訓練執行之前:點選檢視所有 ROI並驗證每一個標註。這是最容易修復且影響最大的事情。
規則 3:從小處開始,快速迭代
不要標註 50 張影象後才開始訓練。相反,建立一個緊密的迴圈:每個類別標註 10-15 張影象,訓練(大約 30 秒),測試並嘗試破壞它,然後在失敗的地方新增針對性的資料。重複這個迴圈 2-4 次。
這個迴圈是通向優秀模型的最快路徑。
分步訓練工作流程
1. 捕獲初始訓練影象
在程式處於活動狀態且零件流動(或手動放置)的情況下,捕獲影象。您需要每個類別至少10-15 張影象才能開始。
對於簡單的透過/失敗檢測:
- 10-15 張良品影象
- 10-15 張缺陷品影象
2. 定義您的類別
選擇您要訓練的模型型別,然後閱讀相應的說明。下面的切換按鈕在第 2 步和第 3 步之間保持同步,您的選擇會保留在 URL 中,因此重新整理或分享後仍然有效。
- Classifier
- Segmenter
在標註介面中,新增每種檢測型別所需的類別。常見的分類器類別集:
- 透過 / 失敗
- 存在 / 缺失
- 良好 / 劃傷 / 破裂
一開始保持簡單。您隨後隨時可以新增類別。
在標註介面中,為您希望 AI 遮罩的缺陷(或特徵)新增類別。常見的分割器類別集:
- 缺陷 / 背景
- 劃傷 / 裂紋 / 汙漬
- 前景 / 背景
一開始保持類別列表簡短。每個類別都需要自己的畫筆顏色和自己的標註示例,因此一開始新增更多類別會使您的標註工作量成倍增加。
3. 標註影象
- Classifier
- Segmenter
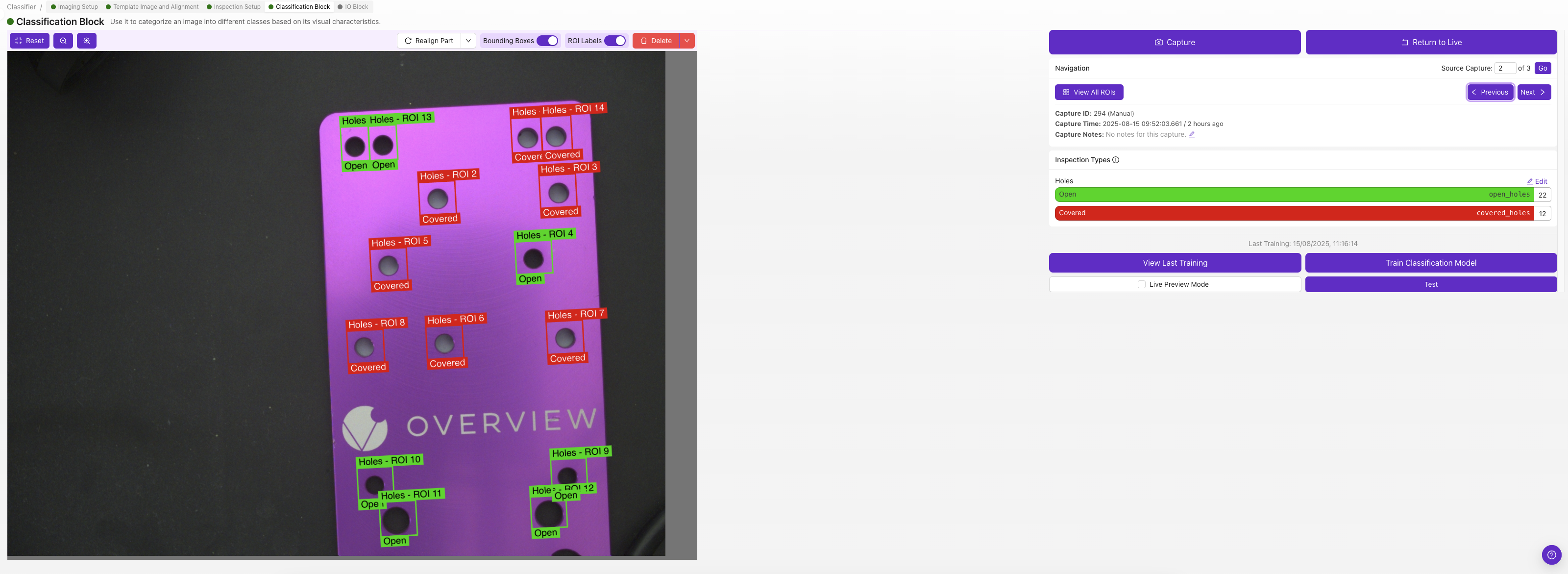
每個 ROI 都有自己的分類類別 — 選擇能夠描述該影象中該 ROI 的類別(例如 "pass" 或 "fail")。
如果您不確定是使用分類還是分割,請從分類開始。它標註速度更快,並且適用於大多數 pass/fail 場景。請參閱 Classifier vs. Segmenter 獲取指導。
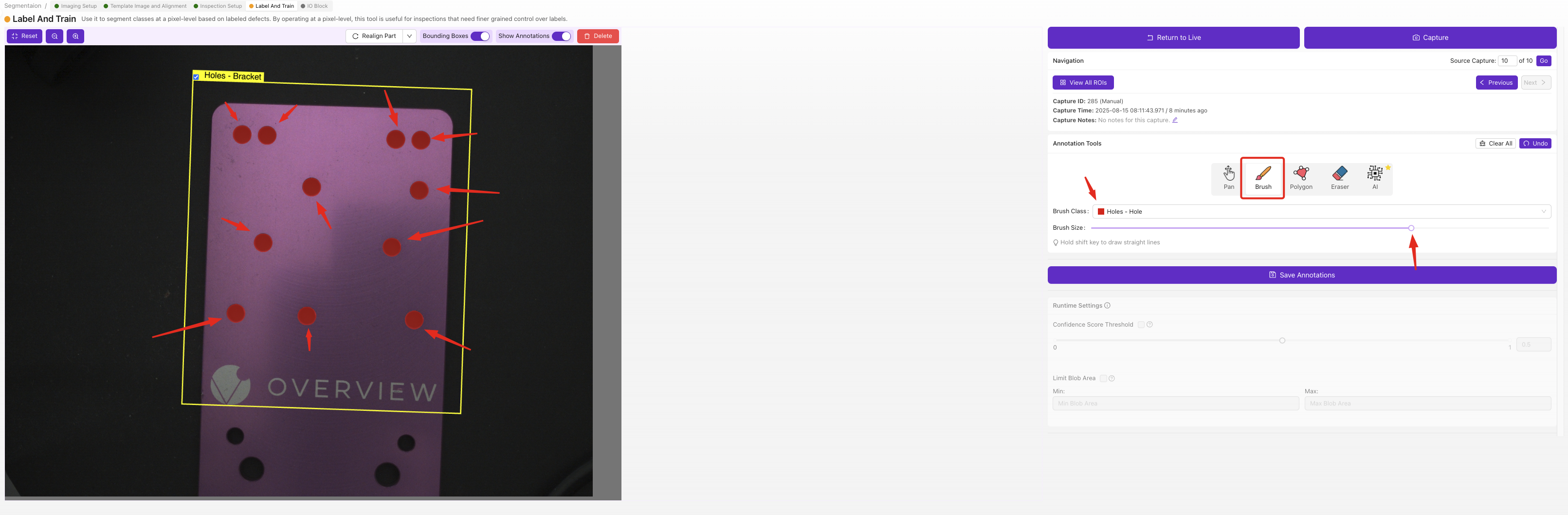
對於每張影象中的每個 ROI,使用畫筆工具逐畫素繪製缺陷區域。繪製的區域就是 AI 學習檢測的內容 — 您未繪製的任何部分都將被視為背景。
分割器標籤需要畫素級的繪製工作,比分類器下拉選擇慢,但可以為您提供具有位置和形狀的精確缺陷圖。從一小組明確定義的缺陷開始,只有在第一個模型工作正常後才新增更多類別。
4. 訓練模型
- Classifier
- Segmenter
點選 訓練。分類器提供兩種訓練模式:
- Fast mode — 大約 30 秒到 1 分鐘。最適合在設定過程中快速迭代、檢查標籤合理性,以及處理簡單/區分度高的部件。準確度低於生產模式,但可以讓您快速看到訊號。
- Production mode — 耗時較長,但生成的模型準確度明顯更高。在部署到產線之前,請始終使用 Production 模式。對於複雜的部件、難以區分的缺陷,或任何您要在生產中信賴的內容,Production 模式才是正確的選擇。
良好的節奏:在清理標籤和新增資料時使用 Fast 模式進行迭代,結果看起來不錯時執行 Production 模式 — 然後在部署之前再執行一次。
點選 訓練。分割只有一種訓練模式 — Production — 因為畫素級掩碼需要更徹底的訓練過程才能可靠。訓練時間隨影象數量和您已標註的 ROI 數量而增加,因此較小的初始集(每類 10-15 張影象)幾分鐘即可完成訓練;更大的資料集需要更長時間。
這裡沒有 "fast" 合理性檢查選項,因此在訓練前請確保您的標籤是乾淨的(使用 View All ROIs 來檢查每個掩碼)。
分割器只學習它們所見過的缺陷的大小和紋理。如果您的訓練集中只有小型汙染物,然後生產中出現了同一缺陷類別的大塊,模型將只勾勒出大缺陷中與小樣本相似的部分 — 而其餘大部分則未被覆蓋。生成的掩碼看起來呈斑塊狀,或僅標記真實缺陷的邊緣和角落。
修復方法: 在訓練樣本中包含產線上預期出現的缺陷尺寸的全部範圍。在小樣本旁邊加上幾張大型汙染物的捕獲通常就足夠了。同樣的原則也適用於紋理和顏色的變化 — 訓練時要涵蓋您將會看到的多樣性。
沒有大缺陷樣本? 使用 Defect Creator Studio 生成同一缺陷在不同尺寸、位置和方向下的合成訓練影象 — 無需等待真實的大型汙染物從產線上經過。
5. 使用實時預覽進行測試
點選 實時預覽模式 並執行零件。觀察結果:
- 它對簡單案例的判斷是否正確?
- 它在哪些地方表現欠佳?
- 哪些是臨界案例?
嘗試讓它失敗。 找出它判斷失敗的案例。這些失敗案例是您改進的路線圖。
- Classifier
- Segmenter

測試面板顯示每個 ROI 的預測 類別 和 置信度分數。執行幾次捕獲,並查詢低置信度判定(通常低於 70%)——這些是您的臨界案例,也是最值得接下來進行標註的零件。
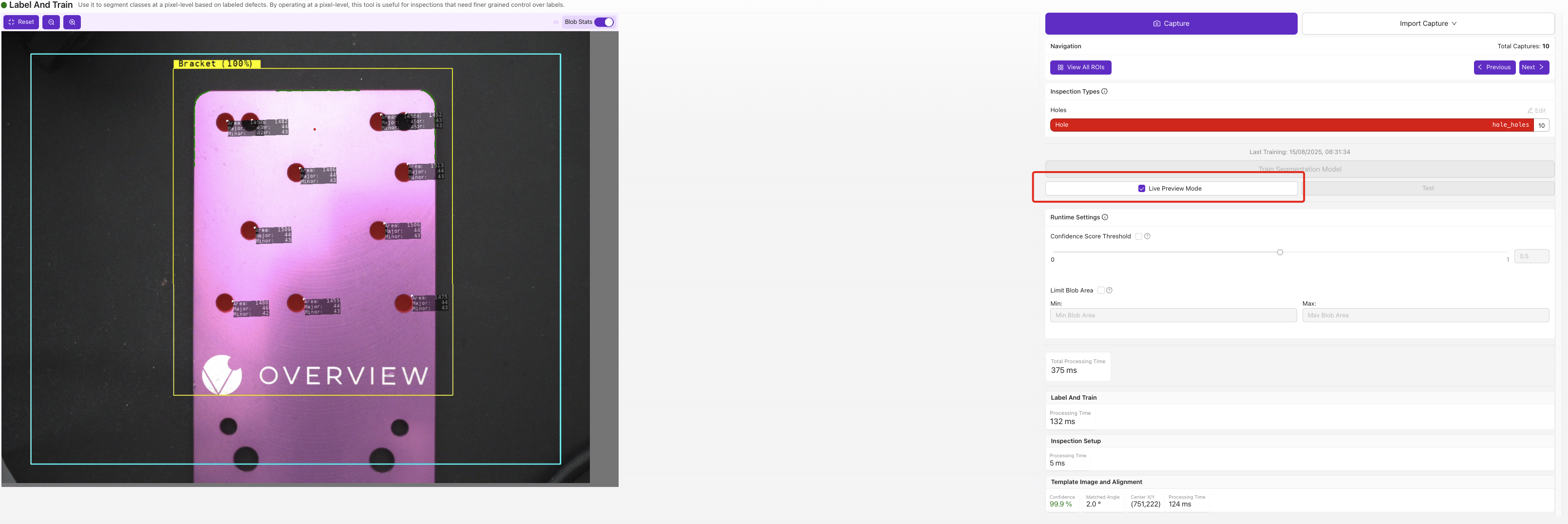
實時預覽將預測的缺陷掩膜直接疊加在影象上。注意那些過小、過大或出現在實際沒有缺陷位置的掩膜——這些是您在下一輪標註資料中需要針對的失敗模式。
6. 新增針對性資料
不要隨意新增新影象。新增專門針對您發現的失敗模式的影象:
- 如果它將劃痕與反光混淆,則新增更多這兩類的示例
- 如果它遺漏小缺陷,則新增更多小缺陷的影象
- 如果它對角落裡的零件判斷失敗,則新增更多角落示例
7. 重新訓練並重新測試
重複步驟 4-6 兩到四次。每次迭代都應提高準確性。如需更深入的演練——包括如何在不丟失先前訓練的情況下向現有模型新增新影象——請參閱 新增資料與重新訓練。
資料增強:教 AI 處理變化
資料增強會在訓練過程中隨機修改您的訓練影象——調整亮度、新增旋轉、微調對比度等。每張影象都會以略有不同的資料增強方式被送入 AI 數百次,但標籤保持不變。這就是讓模型在無需捕獲每種可能變化示例的情況下,仍能適應真實世界條件的方法。
預設應開啟的項
少量的 亮度 變化幾乎總是值得開啟的——即使是最嚴格控制的工廠也會有頂燈閃爍、班次間陰影變化以及 LED 隨時間出現的輕微漂移。亮度資料增強基本上可以零成本地讓模型應對所有這些情況。
旋轉:實用,但要注意您的 ROI 形狀
如果您的零件確實可能以不同角度到達(傳送帶上鬆散的螺絲、手工放置的零件、任何未固定在夾具中的物品),旋轉資料增強非常有用。但它與 ROI 形狀相互影響:
- 方形 ROI: 旋轉資料增強可以正常工作——旋轉後的影象仍能裝入 ROI 框內。
- 分類器上的非方形 ROI: 旋轉可能會裁剪影象。當一個高而窄的 ROI 被旋轉 45° 時,旋轉後內容的角會落在框外,模型會基於不完整的影象進行訓練。如果您的零件可能旋轉,要麼將 ROI 設為方形,要麼依靠 對齊器 在上游處理旋轉,這樣此處就不需要旋轉資料增強。
- 分割器: 同樣存在裁剪問題,但分割對此不太敏感,因為它是從畫素掩膜而非整個 ROI 形狀中學習的。
何時不應使用特定的資料增強
通用規則:不要對你正在檢測的屬性進行增強。 如果你想要檢測方向,旋轉增強會讓模型認為顛倒的零件也是"良好"的。
- 檢測顏色一致性? 不要使用飽和度增強。
- 檢測模糊/對焦? 不要使用運動模糊增強。
- 檢測方向? 不要使用旋轉增強(並且可能也不應使用對齊器)。
資料多樣性很重要
你的訓練資料應代表AI在生產中將看到的全部範圍:
- 一天中的不同時段(如果光照有變化)
- 不同批次的零件(表面處理可能略有不同)
- 零件在畫面中處於不同位置
- 容易和困難的案例都要包含
重點關注最困難的案例。 如果你的訓練資料包含了最難分類的10個零件,那麼剩下90%的簡單零件對AI來說將輕而易舉。
高學習能力
OV相機的AI設計為可隨著資料增加而不斷提升。與許多在20張影象後就達到瓶頸的AI系統不同,該模型在50張、100張甚至500張以上影象下仍能持續改進。大多數檢測在5-10張影象下就能執行良好,但如果你面對的是複雜的多缺陷問題,請不要猶豫繼續新增資料。
使用合成資料加速:Defect Studio
如果你需要為一種很少見到的缺陷進行訓練怎麼辦?比如你必須故意拆掉的缺失螺絲、必須人為製造的劃痕、每千件零件才出現一次的裂紋?等待數月才能收集到足夠的樣本並不現實。
OV Auto-Defect Creator Studio 位於 tools.overview.ai,正是為解決此問題而生。它能夠生成照片級真實感的合成缺陷影象,比等待真實缺陷出現在生產線上快多達10,000倍。
工作原理:5個簡單步驟
- 上傳 一張零件的良品影象
- 標記 缺陷應出現的區域
- 描述 缺陷(使用簡單英語,例如"表面有一道深劃痕"或"焊點缺失")
- 生成 缺陷的多種變化(AI生成照片級真實感的結果)
- 匯出 合成影象,直接加入到訓練集中
為什麼合成資料有效
生成的影象不僅僅是"貼上去"的偽影。它們是照片級真實感的變化,匹配你的實際光照、相機角度和零件表面。AI理解在你特定成像條件下缺陷外觀的物理特性。
使用場景:
- 罕見缺陷: 針對從未(或很少)見過的失效模式進行訓練
- 新產品上市: 在第一件不良品下線之前就構建好檢測方案
- 邊界案例: 生成臨界樣本以改進AI的決策邊界
- 資料增強: 用合成多樣性補充小型資料集
實際演示
最佳方法:先用最初的3-5張真實影象進行訓練,識別AI表現不佳的地方,然後使用 Defect Studio 針對那些特定的失效模式生成有針對性的合成樣本。真實資料建立基線;合成資料填補空白。
訓練檢查清單
在繼續之前,請確認:
- 已捕獲初始影象,每個類別至少 10-15 張
- 所有標籤均已複核(View All ROIs)
- 已透過實時預覽完成訓練和測試
- 已識別失敗模式並新增針對性資料
- 已完成 2-4 輪標籤 → 訓練 → 測試的迭代
- 結果符合預期
模型訓練完成且效果良好?請進入 第 5 步:設定輸出。