KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
Erstellung des ersten Recipes
Dieser Deep Dive erklärt, was ein Recipe ist, beschreibt die Unterschiede zwischen Classification und Segmentation und bietet eine Schritt-für-Schritt-Anleitung zur Erstellung eines Recipes. Außerdem enthält er eine detaillierte Erläuterung der Image Setup-Konfiguration, der Template Image-Aufnahme und Alignment-Einrichtung, der ROI-Optimierung, der Datenerfassung und des AI-Trainings sowie der Konfiguration der Bildaugmentierung.
Sehen Sie dieses Thema in Aktion: How to create a segmentation recipe in minutes
Lernziele
Am Ende dieses Deep Dives werden Sie Folgendes verstehen:
- was ein Recipe ist
- den Unterschied zwischen Classification und Segmentation – und wann welche zu verwenden ist
- wie ein Recipe erstellt wird
- wie das Imaging Setup konfiguriert wird
- wie ein Template Image aufgenommen und der Aligner konfiguriert wird
- was ROIs (Regions of Interest) sind und wie sie optimiert werden
- Datenerfassung für AI-Training
- Recipe-Tests und Validierung
Was ist ein Recipe?
- Ein konfigurierter Satz von Anweisungen, der der Kamera mitteilt, wie ein bestimmtes Teil oder Produkt zu inspizieren ist.
- Definiert Kameraeinstellungen, einschließlich Belichtung, Fokus und Beleuchtungsparametern für eine konsistente Bildaufnahme.
- Enthält Verarbeitungslogik wie ROI-Definitionen, Aligner, Classification- oder Segmentation-Klassen.
- Speichert Input/Output-Konfigurationen zur Integration mit Automatisierungssystemen für Pass/Fail- oder erweiterte Signale.
- Kann gespeichert und wiederverwendet werden, um konsistente Inspektionen über Schichten, Linien oder Standorte hinweg sicherzustellen.
Classification vs. Segmentation
Definitionen
- Classification: Identifizierung des Objekttyps im ROI
- Segmentation: Lokalisierung und Analyse von Regionen im Bild/ROI
Beispiele
| Image Classification | Image Segmentation | Image Classification | Image Segmentation |
|---|---|---|---|
| Was ist ein Schaf? | Welche Pixel gehören zu welchem Objekt? | Ist diese Pizza akzeptabel oder fehlerhaft? | Wo befindet sich jede Pepperoni? |
 |  |  |  |
Wichtigster Vergleich
| Classification | Segmentation | |
|---|---|---|
| Geschwindigkeit | Die Geschwindigkeit hängt vom Image Setup und der Komplexität ab. Im Allgemeinen effizient und schnell bei einfachen Setups | Kann bei Optimierung genauso schnell oder sogar schneller als Classification sein, insbesondere mit optimierten Modellen |
| Genauigkeit | Gut geeignet für allgemeine Pass/Fail- oder Teiletyp-Identifizierung | Höhere Genauigkeit für präzise Defekt-Lokalisierung |
| Komplexität | Einfach einzurichten und zu pflegen; weniger Parameter | Komplex – Erfordert mehr Daten, Labeling und Tuning |
| Datenanforderung | Niedrig – Benötigt weniger gelabelte Bilder | Moderat – Erfordert viele Bilder mit detaillierten pixelgenauen Annotationen |
| Anwendungsfälle | Teilanwesenheit, Ausrichtung, grundlegende Qualitätsprüfungen, Teil eingesetzt/nicht eingesetzt usw. | Oberflächendefekte, Feinmerkmalsinspektion, Multi-Defekt-Erkennung, Zählung, Messung usw. |
Erstellen und Exportieren eines Rezepts
Verwenden Sie die Schaltfläche Export Recipe neben einem Rezept, um ein einzelnes Rezept zu exportieren.
![]()
Verwenden Sie die Schaltfläche Export oben auf dem Bildschirm, um mehrere Rezepte gleichzeitig zu exportieren.

Verwenden Sie die Schaltfläche Import oben auf dem Bildschirm, um Rezepte zu importieren.

Hinweis: Jedes Rezept unterstützt jeweils nur einen Inspektionstyp – entweder Segmentation oder Classification. Wählen Sie den korrekten Typ aus, bevor Sie mit der Einrichtung beginnen.
Image Setup
Image Rotation

- Was es ist: Dreht das Bild (0° oder 180°).
- Wann verwenden: Wenn die Kamera in einem Winkel montiert ist, das Bild in der Oberfläche jedoch anders dargestellt werden soll.
Wenn Sie das Bild um 90° drehen müssen, drehen Sie die Kamera.
Gain

- Was es ist: Hellt das Bild digital künstlich auf (vergleichbar mit ISO bei einer Kamera).
- Effekt:
- Höherer Gain → helleres Bild, jedoch mit zusätzlichem Rauschen (körniges Erscheinungsbild).
- Niedrigerer Gain → saubereres Bild, erfordert jedoch gute Beleuchtung.
| High Gain | Low Gain |
|---|---|
 |  |
| Heller und mehr Rauschen | Dunkler und weniger Rauschen |
Erhöhen Sie den Gain nur, wenn eine Anpassung von Belichtung oder Beleuchtung nicht möglich ist.
Template Image and Alignment
Skip Aligner

- Was es ist: Deaktiviert den Ausrichtungsschritt während der Inspektion.
- Wann verwenden: Wenn sich das Teil immer in derselben Position und Ausrichtung im Bild befindet.
Template Regions

- Was es ist: Definiert den oder die Bereiche des Template-Bildes, die für die Ausrichtung verwendet werden.
- Rectangle: Zeichnet eine rechteckige ROI.
- Circle: Zeichnet eine kreisförmige ROI.
- Ignore Template Region: Schließt bestimmte Bereiche von der Ausrichtung aus, um störende Muster oder irrelevante Merkmale zu vermeiden.
- Optimale Verwendung: Hilft dem System, sich nur auf die markantesten Teilmerkmale zu konzentrieren, um eine genaue Ausrichtung zu erzielen.
Rotation Range
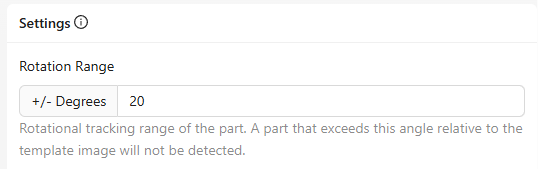
- Was es ist: Legt fest, wie viel Rotation (in Grad) das System beim Abgleich des Teils mit dem Template toleriert.
- Beispiel: Eine Einstellung von ±20° erlaubt es, dass das Teil leicht rotiert ist und dennoch erkannt wird.
- Wann anpassen: Erhöhen, wenn Teile während der Produktion zur Rotation neigen; verringern bei sehr konsistenten Ausrichtungen.
Sensitivity

- Was es ist: Steuert, wie fein das System nach einer Übereinstimmung zwischen dem Live-Bild und dem Template sucht.
- Effekt:
- Hohe Sensitivity → erkennt feinere Details, nützlich für komplexe Teile.
- Niedrigere Sensitivity → reduziert Fehlübereinstimmungen, kann aber feine Merkmale übersehen.
Confidence Threshold

- Was es ist: Legt den minimalen Konfidenzwert fest, der erforderlich ist, damit das System eine Erkennung akzeptiert.
- Auswirkung:
- Höherer Schwellenwert → weniger Fehlalarme, aber Grenzfälle könnten übersehen werden.
- Niedrigerer Schwellenwert → mehr Erkennungen, aber mit erhöhtem Risiko von Fehlalarmen.
Beginnen Sie mit einem mittleren Wert und passen Sie ihn basierend auf den Testergebnissen an.
Scale Invariant

- Was es ist: Ermöglicht dem System die Erkennung von Teilen, die geringfügig größer oder kleiner als das Original-Template-Bild sind.
- Wann aktivieren: Wenn die Teilegröße aufgrund von Positionierung, Abstandsänderungen oder Fertigungstoleranzen leicht variieren kann.
Live Preview Legende

1. Eine konfigurierbare Bounding Box, die den spezifischen Bereich des Sichtfelds (FOV) der Kamera definiert, der während der Auslösung überwacht werden soll.
- Zweck: Stellt sicher, dass sich die Kamera nur auf den relevanten Bereich konzentriert und unnötige Hintergrundbereiche ignoriert.
- Empfohlene Anwendung:
- Bei bewegten Objekten, um zu gewährleisten, dass das Teil vollständig im Erkennungsbereich bleibt.
- Zur Optimierung der Verarbeitungsgeschwindigkeit durch Reduzierung der zu analysierenden Bilddaten.
2. Ein visueller roter Punkt, der den Mittelpunkt aller definierten ROIs (Regions of Interest) im Bild anzeigt.
- Zweck: Hilft Ihnen, den Suchbereich relativ zum Teil oder Kamerabild auszurichten und zu positionieren.
3. Die grüne Linie zeigt an, dass die Kante des Objekts erkannt wurde.
Wenn sich die Linie rot färbt, versuchen Sie, die ROI-Größe zu erhöhen, die ROI anzupassen oder die Sensitivität zu erhöhen.

ROI (Region of Interest) Definition und Optimierung
Inspection Types

- Was es ist: Definiert den Typ der durchgeführten Inspektion und gruppiert ähnliche ROIs (Regions of Interest).
- Beispiel: „Holes" zur Prüfung des Vorhandenseins, der Größe oder der Qualität von Löchern in einem Teil.
- Hauptmerkmale:
- Add Inspection Type: Erstellen Sie neue Kategorien für verschiedene Inspektionsanforderungen.
- # of ROIs: Zeigt an, wie viele ROIs diesem Inspektionstyp aktuell zugeordnet sind.
Transformation
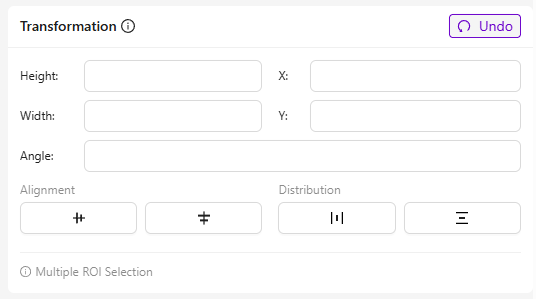
- Was es ist: Passt die Position und Geometrie ausgewählter ROIs für eine präzise Ausrichtung und Platzierung an.
- Felder und ihr Zweck:
- Height/Width: Ändert die Größe der ROI.
- X / Y: Verschiebt die Position der ROI entlang der horizontalen (X) und vertikalen (Y) Achse.
- Angle: Dreht die ROI um ihren Mittelpunkt.
- Empfohlene Anwendung: Beschleunigt die Einrichtung bei sich wiederholenden Mustern, wie z. B. mehreren identischen Löchern.
Inspection Regions
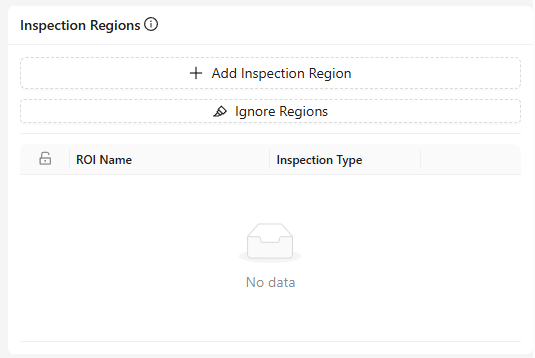
- Was es ist: Eine Liste aller im Template-Bild definierten ROIs.
- Funktionen:
- Add Inspection Region: Manuelles Erstellen einer neuen ROI.
- Ignore Regions: Ausschließen bestimmter Bereiche von der Verarbeitung.
- Edit: Speichern, Löschen oder Abbrechen.
- Lock Icon: Zeigt gesperrte ROIs an, die ohne Entsperren nicht verschoben werden können.
Live Preview Mode
![]()
- Was es ist: Zeigt Echtzeit-Feedback nach dem Anpassen oder Hinzufügen von ROIs.
- Anwendungsfall: Ideal für die Feinabstimmung von ROI-Positionen und -Größen während der Einrichtung.
Test Button
![]()
- Was es ist: Backtesting auf Basis alter Bilder durchführen, um Änderungen zu überprüfen.
- Anwendungsfall: Vergleich aktueller Ergebnisse mit vorherigen Einstellungen hinsichtlich Genauigkeit und Konsistenz.
Datenerfassung und KI-Training
Definieren Sie verschiedene Inspektionsklassen und beschriften Sie jede ROI entsprechend ihrem vorgesehenen Inspektionstyp (siehe Beispiel unten).
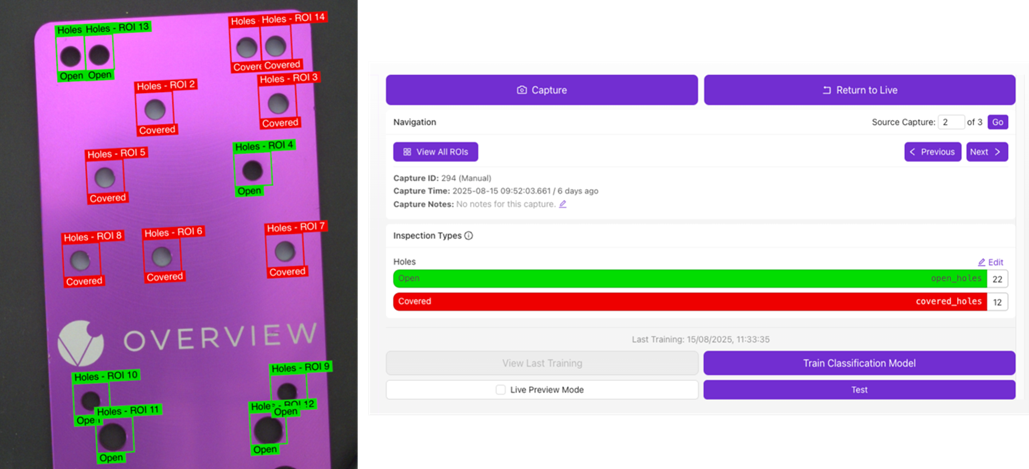
Verwenden Sie die Annotation Tools, um das Bild zu beschriften/annotieren. Wählen Sie über das Dropdown-Menü Brush Class die zu annotierende Klasse aus. Das aktuelle Limit liegt bei bis zu 10 Klassen pro Rezept für die Segmentierung.
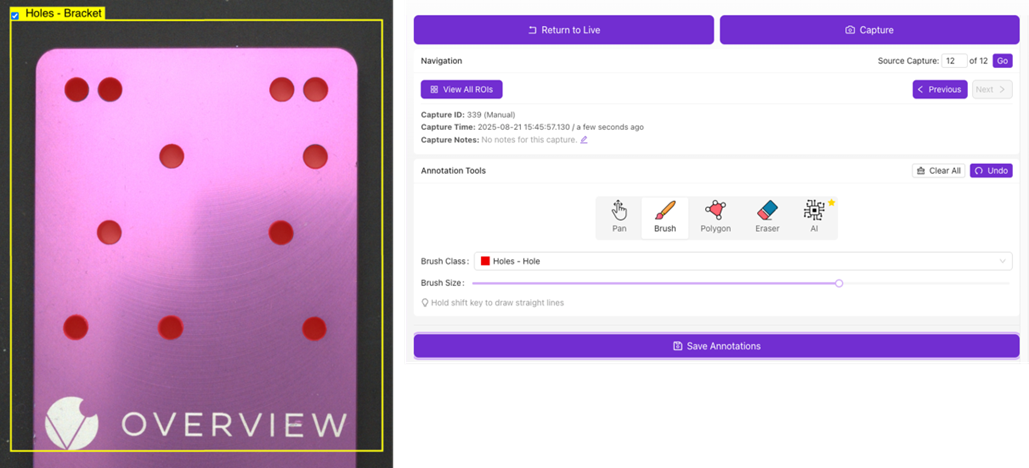
Bedeutung guter Daten

-
Garbage In, Garbage Out: KI-Modelle können nur so gut sein wie die Daten, mit denen sie versorgt werden. Daten von schlechter Qualität oder inkonsistente Daten führen zu ungenauen Ergebnissen.
-
Vielfalt zählt: Erfassen Sie Daten, die alle realen Variationen abbilden: verschiedene Schichten, Lichtverhältnisse, Teilepositionen und Oberflächenzustände.
-
Qualität vor Quantität: Ein kleinerer, sauberer und gut beschrifteter Datensatz erzielt oft bessere Ergebnisse als ein großer, aber verrauschter oder inkonsistenter Datensatz.
Grundlagen der Annotation:
- Classification: Markieren ganzer Bilder oder ROIs als eine bestimmte Klasse (z. B. „Good", „Damaged").
- Segmentation: Übermalen, Umranden oder Hervorheben spezifischer interessanter Bereiche mit pixelgenauer Präzision (z. B. Position eines Kratzers auf einer Oberfläche).
- Konsistenz: Verwenden Sie einheitliche Regeln und Definitionen für die Beschriftung, um Verwechslungen beim Training zu vermeiden.

Häufige Fallstricke
- Unzureichende Daten: Zu wenige Stichproben führen zu Underfitting und damit zu schlechter Performance im realen Einsatz.
- Unausgewogene Klassen: Eine Überrepräsentation einer Klasse (z. B. viele „gute" Teile, aber wenige fehlerhafte) verzerrt das Modell.
- Schlechte Beschriftung: Falsche, inkonsistente oder überhastete Beschriftung führt zu erheblichen Genauigkeitsverlusten.
- Ignorieren von Umgebungsänderungen: Wird der Datensatz bei Änderungen von Beleuchtung, Teileausrichtung oder Oberflächenzuständen nicht aktualisiert, kommt es zu einer Drift in der Genauigkeit.
- Fehlende Datenvalidierung: Werden Qualitätsprüfungen vor dem Training übersprungen, führt dies häufig zu Zeitverlust und Nacharbeit.
Datenaugmentation
Bildaugmentierungen modifizieren Ihre Trainingsbilder künstlich, um die Robustheit des Modells zu verbessern. Sie simulieren reale Variationen wie Helligkeitsänderungen, Rotationen oder Rauschen, damit das Modell unter verschiedenen Bedingungen zuverlässig funktioniert.
Farbaugmentierungen
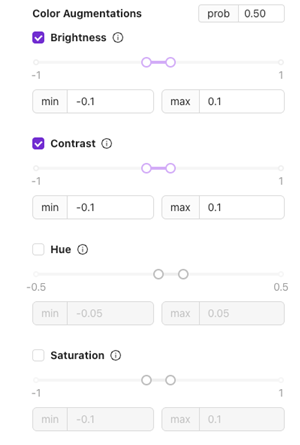
Brightness
- Was es ist: Passt an, wie hell oder dunkel das Bild erscheint.
- Anwendungsfall: Zur Bewältigung geringfügiger Beleuchtungsänderungen während der Produktion.
Verwenden Sie ±0,1 für stabile Setups; erhöhen Sie den Wert, wenn die Beleuchtung stärker variiert.
Contrast
- Was es ist: Ändert den Unterschied zwischen hellen und dunklen Bereichen.
- Anwendungsfall: Nützlich für Teile mit Textur oder unterschiedlichen Oberflächen, um dem Modell zu helfen, sich an visuelle Unterschiede anzupassen.
Hue
- Was es ist: Verschiebt die Farbtöne leicht.
- Anwendungsfall: Geeignet für Setups, bei denen sich die Lichtfarbe (z. B. LED-Farbtemperatur) im Laufe der Zeit ändern kann.
Saturation
- Was es ist: Passt die Intensität der Farben an.
- Anwendungsfall: Hilft, Beleuchtungsvariationen zu bewältigen, die Bilder matter oder kräftiger erscheinen lassen.
Geometrische Augmentierungen
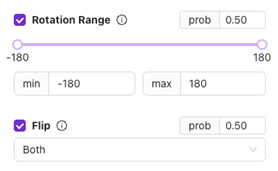
Rotation Range
- Was es ist: Rotiert das Bild zufällig innerhalb des festgelegten Bereichs (z. B. ±20°).
- Anwendungsfall: Für Teile, die in leicht gedrehten Positionen erscheinen können.
Vermeiden Sie übermäßige Rotation für Teile, die normalerweise in ihrer Ausrichtung fixiert sind.
Flip
- Was es ist: Spiegelt das Bild horizontal, vertikal oder beides.
- Anwendungsfall: Hilfreich für symmetrische Teile oder wenn sich die Ausrichtung bei der Handhabung ändern kann.
Beleuchtungs- und Farbsimulation
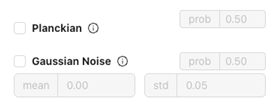
Planckian
- Was es ist: Simuliert Variationen der Farbtemperatur (z. B. warmes oder kaltes Licht).
- Anwendungsfall: Bewältigt verschiedene Schichten oder Arbeitszellen mit unterschiedlichen Lichtquellen.
Gaussian Noise
- Was es ist: Fügt dem Bild subtiles Rauschen hinzu.
- Anwendungsfall: Verbessert die Robustheit, wenn Ihre Produktionsumgebung geringes Bildrauschen oder Kamerasensor-Artefakte aufweist.
Bewegungssimulation
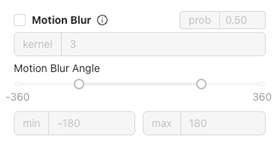
Motion Blur
- Was es ist: Simuliert leichte Unschärfe, als ob sich das Teil während der Aufnahme bewegt hätte.
- Anwendungsfall: Entscheidend für Hochgeschwindigkeitslinien, bei denen Bewegungsunschärfe auftreten kann.
Wahrscheinlichkeit (prob)
![]()
- Was es ist: Legt die Wahrscheinlichkeit fest, mit der jede Augmentierung während des Trainings angewendet wird.
- Beispiel: 0,50 = 50 % Wahrscheinlichkeit, dass diese Änderung auf ein bestimmtes Trainingsbild angewendet wird.
Beginnen Sie für die meisten Augmentierungen mit 0,5 und passen Sie den Wert basierend auf der realen Variabilität an.
Trainingsparameter (Segmentierung)
Trainingsparameter (auch Hyperparameter genannt) sind die Einstellungen, die steuern, wie ein Machine-Learning-Modell aus Daten lernt.
Learning Rate

- Definition: Steuert, wie schnell das Modell seine internen Gewichte während des Trainings aktualisiert.
- Wert (0,003): Je höher die Learning Rate, desto schneller lernt das Modell, aber ein zu hoher Wert kann zu Instabilität oder geringer Genauigkeit führen.
- Schieberegler-Bereich: Von 10^-4 (sehr langsam) bis 10^-1 (sehr schnell).
Üblicherweise ist ein Wert zwischen 0,001–0,01 ein guter Ausgangspunkt für Segmentierungsaufgaben.
ROI (Region of Interest) Größe

- Definition: Legt die Größe (Breite × Höhe) des Bildbereichs fest, der während des Trainings verwendet wird.
- Nicht aktiviert: Standardmäßig ermittelt das Modell die ROI automatisch anhand Ihrer Daten.
- Bei Aktivierung: Sie können Breite und Höhe manuell festlegen, wenn Sie einheitliche Eingabeabmessungen benötigen (z. B. alle Bilder auf 256×256 Pixel zugeschnitten).
Verwenden Sie eine feste Größe (z. B. 256×256), wenn Ihr Datensatz Bilder unterschiedlicher Größen enthält und Sie eine konsistente Eingabe für bessere Stabilität, Reproduzierbarkeit oder zur Anpassung an eine bekannte Modellarchitektur wünschen.
Lassen Sie das System automatisch wählen, wenn Ihre Daten bereits eine einheitliche Auflösung haben oder wenn das System auf Basis der Eigenschaften Ihres Datensatzes die optimale ROI bestimmen soll.
Anzahl der Iterationen (Epochs)

- Definition: Eine Epoche = ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz.
- Wert (100): Das Modell wird 100 vollständige Durchläufe trainieren.
Eine Erhöhung dieses Werts verbessert in der Regel die Genauigkeit bis zu einem gewissen Punkt, dauert aber länger.
Faustregel: Überwachen Sie den Trainings- und Validierungsverlust während des Trainings. Wenn der Validierungsverlust nicht mehr abnimmt, während der Trainingsverlust weiter sinkt, ist dies ein Hinweis auf Overfitting, und Sie sollten das Training früher beenden.
Architektur

- Definition: Wählt die Größe und Komplexität des neuronalen Netzes aus.
- Small: Trainiert schneller und ist für die meisten Datensätze oft ausreichend. Ideal für schnelle Experimente oder kleinere Datensätze.
- Größere Modelle können mehr Details erfassen, neigen jedoch bei kleinen Datensätzen zu Overfitting, während kleinere Modelle effizienter sind und bei begrenzten Daten besser generalisieren.
Beginnen Sie mit Small – das ist oft ausreichend und ermöglicht schnellere Iterationen, bevor Sie hochskalieren.
External GPU

Kontaktieren Sie den Support, um mehr über External GPU zu erfahren.
Trainingsparameter (Classification)
Trainingsparameter (auch Hyperparameter genannt) sind die Einstellungen, die steuern, wie ein Machine-Learning-Modell aus Daten lernt.
Learning Rate

- Definition: Steuert, wie schnell das Modell während des Trainings seine internen Gewichte aktualisiert.
- Wert (0,003): Je höher die Learning Rate, desto schneller lernt das Modell, aber zu hohe Werte können zu Instabilität oder geringer Genauigkeit führen.
- Slider-Bereich: Von 10^-4 (sehr langsam) bis 10^-1 (sehr schnell).
Ein Wert zwischen 0,001 und 0,01 ist in der Regel ein guter Ausgangspunkt für Segmentierungsaufgaben.
Validation Percent

- Definition: Legt fest, welcher Anteil Ihres Datensatzes für die Validierung (Testen während des Trainings) reserviert wird.
- Zweck: Validierungsdaten helfen dabei zu überwachen, wie gut das Modell bei unbekannten Beispielen abschneidet, und verhindern Overfitting.
- Bereich: 0–50 %.
Übliche Werte liegen bei 10–20 %.
Bei 0 % werden alle Daten für das Training verwendet, was die Trainingsgenauigkeit verbessern kann, aber das Erkennen von Overfitting erschwert.
ROI (Region of Interest) Größe
- Definition: Definiert die Größe (Breite × Höhe) des Bildbereichs, der während des Trainings verwendet wird.
- Nicht aktiviert: Standardmäßig bestimmt das Modell den ROI automatisch anhand Ihrer Daten.
- Wenn aktiviert: Sie können Breite und Höhe manuell festlegen, wenn Sie konsistente Eingabeabmessungen benötigen (zum Beispiel alle Bilder auf 256×256 Pixel zugeschnitten).
Verwenden Sie eine feste Größe (z. B. 256×256), wenn Ihr Datensatz Bilder unterschiedlicher Größen enthält und Sie eine konsistente Eingabe für bessere Stabilität, Reproduzierbarkeit oder zur Übereinstimmung mit einer bekannten Modellarchitektur wünschen.
Lassen Sie die automatische Auswahl zu, wenn Ihre Daten bereits eine einheitliche Auflösung haben oder wenn das System basierend auf den Merkmalen Ihres Datensatzes die beste Region of Interest optimieren soll.
Anzahl der Iterationen (Epochs)
- Definition: Eine Epoche = ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz.
- Wert (100): Das Modell wird für 100 vollständige Durchläufe trainiert.
Eine Erhöhung dieser Zahl verbessert in der Regel die Genauigkeit bis zu einem gewissen Punkt, dauert aber länger.
Faustregel: Überwachen Sie den Trainings- und Validierungsverlust während des Trainings. Wenn der Validierungsverlust nicht mehr abnimmt, während der Trainingsverlust weiter sinkt, ist dies ein Zeichen dafür, dass das Modell überangepasst (overfitting) ist und Sie das Training früher beenden sollten.
Architektur
- Definition: Wählt die Größe und Komplexität des neuronalen Netzes aus.
- Small: Trainiert schneller und ist für die meisten Datensätze oft ausreichend. Ideal für schnelle Experimente oder kleinere Datensätze.
Beginnen Sie mit Small, das ist oft ausreichend und hilft Ihnen, schneller zu iterieren, bevor Sie hochskalieren.
| Architektur und Kamera | Beschreibung | Empfohlene Verwendung |
|---|---|---|
| ConvNeXt-Pico | Ultraleichtes Modell, optimiert für Geschwindigkeit und geringen Speicherverbrauch. | Ideal für schnelle Experimente oder begrenzte Hardware. |
| ConvNeXt-Nano | Etwas größer als Pico; bessere Genauigkeit bei minimalem Mehraufwand. | Gute Balance für kleine bis mittlere Datensätze. |
| ConvNeXt-Tiny | Bietet verbesserte Genauigkeit und ist dennoch effizient. | Geeignet für mittelgroße Datensätze und längere Trainingsläufe. |
| ConvNeXt-Small | Leistungsfähigste Variante in dieser Liste. Höhere Kapazität und Genauigkeit. | Verwenden Sie diese für große Datensätze oder wenn maximale Leistung erforderlich ist. |
Externe GPU
Kontaktieren Sie den Support, um mehr über die externe GPU zu erfahren.