AI 驅動文件
您想了解什麼?
第四步:訓練您的 AI 模型
您的感興趣區域(ROI)已設定完成。現在該教 AI 識別什麼是"好"和"壞"了。
訓練的三大基本原則
在開始之前,請牢記這三條原則。無論您是訓練分類器還是分割器,使用 5 張影象還是 500 張影象,這些原則都適用。
原則 1:僅從影象進行標註
永遠不要透過檢視實物零件(或將其置於顯微鏡下)來判斷它是好是壞。如果您在相機影象中看不到缺陷,AI 就無法學習它。
AI 並非魔法。它只能根據相機所見的內容工作。如果您因觸控零件或用放大鏡放大而注意到某些問題,從而將其標註為"缺陷",但相機影象看起來正常,那麼您就是在教 AI 看見不存在的東西。
如果您無法僅從影象進行標註,請返回安裝步驟,修正物理設定:更好的鏡頭、更好的光源、更近的安裝位置、不同的角度。
原則 2:反覆核對您的標籤
每個人都會出現誤標;經驗豐富的工程師也不例外。但在小資料集中,一個錯誤的標籤就可能摧毀您的結果。
在 5 張訓練影象中,一個誤標會汙染 20% 的訓練資料。這是災難性的。
每次訓練之前: 點選 View All ROIs,逐一核實每條標註。這是最容易修正且影響最大的事情。
原則 3:從小處著手,快速迭代
不要標註 50 張影象然後直接訓練。相反,請建立一個緊湊的迴圈:每類標註 10-15 張影象,進行訓練(約 30 秒),然後測試並嘗試找出問題,再針對失敗之處新增有針對性的資料。重複這個迴圈 2-4 次。
這個迴圈是通往優秀模型的最快路徑。
分步訓練工作流程
OV20i Web 介面在 v2026.5 中進行了重新設計。請在相機 UI 的右上角檢視您的軟體版本,並選擇匹配的選項卡。您的選擇將在此設定流程的每個頁面上保持一致。
- 較舊版本
- v2026.5 and newer
按照下面的編號步驟進行捕獲、標註、訓練和迭代。
1. 捕獲初始訓練影象
在程式啟用且零件正在流動(或手動放置)的情況下,捕獲影象。開始時每類至少需要 10-15 張影象。
對於簡單的透過/失敗檢測:
- 10-15 張良品影象
- 10-15 張缺陷品影象
2. 定義您的分類
選擇您要訓練的模型型別,然後閱讀相應的說明。下方的切換在第 2 步和第 3 步之間保持同步,您的選擇會儲存在 URL 中,因此即使重新整理或分享也不會丟失。
- 分類器
- 分割器
在標註介面中,新增每種檢測型別所需的分類。常見的分類器類別集:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
最初保持簡單。您隨時可以稍後新增分類。
在標註介面中,為您希望 AI 進行掩膜處理的缺陷(或特徵)新增分類。常見的分割器類別集:
- Defect / Background
- Scratch / Crack / Stain
- Foreground / Background
最初保持分類列表簡短。每個分類都需要自己的畫筆顏色和已標註示例,因此預先新增更多分類會成倍增加您的標註工作量。
3. 標註影象
- Classifier
- Segmenter
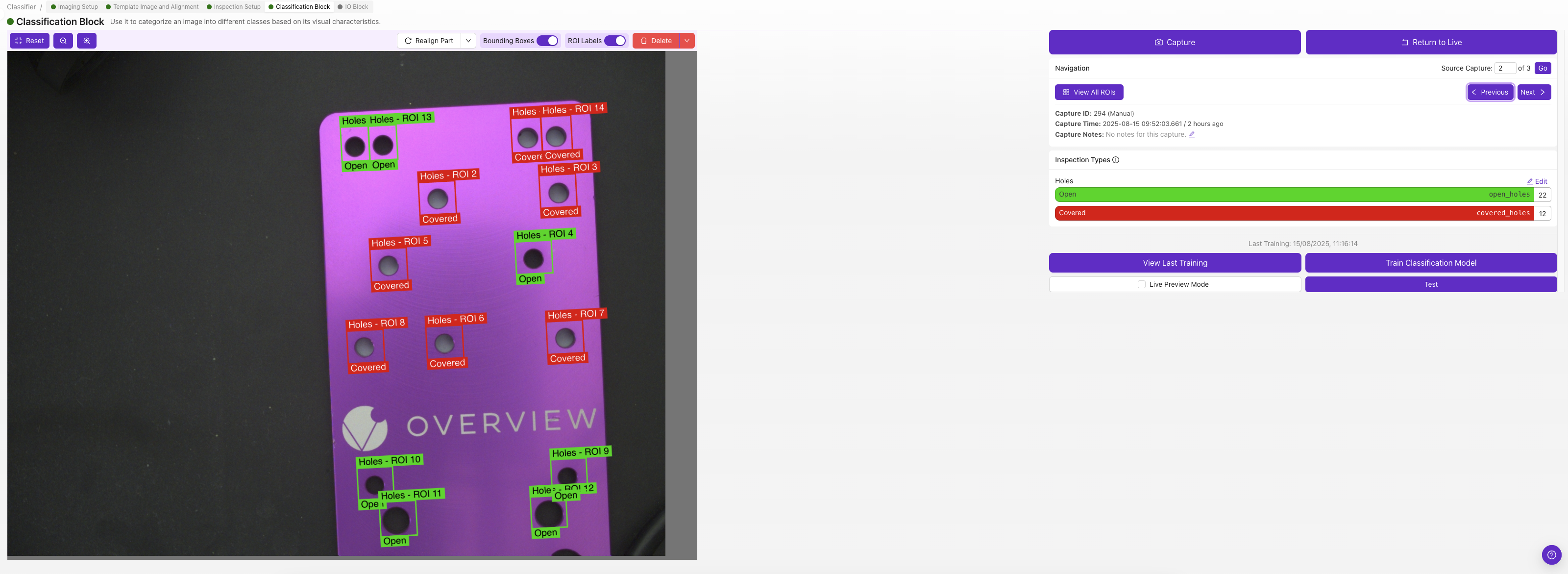
每個ROI都有自己的分類類別,請選擇能描述該影象中該ROI的類別(例如"pass"或"fail")。
如果您不確定使用分類還是分割,請從分類開始。它的標註速度更快,並且適用於大多數透過/失敗場景。請參閱Classifier vs. Segmenter 獲取指導。
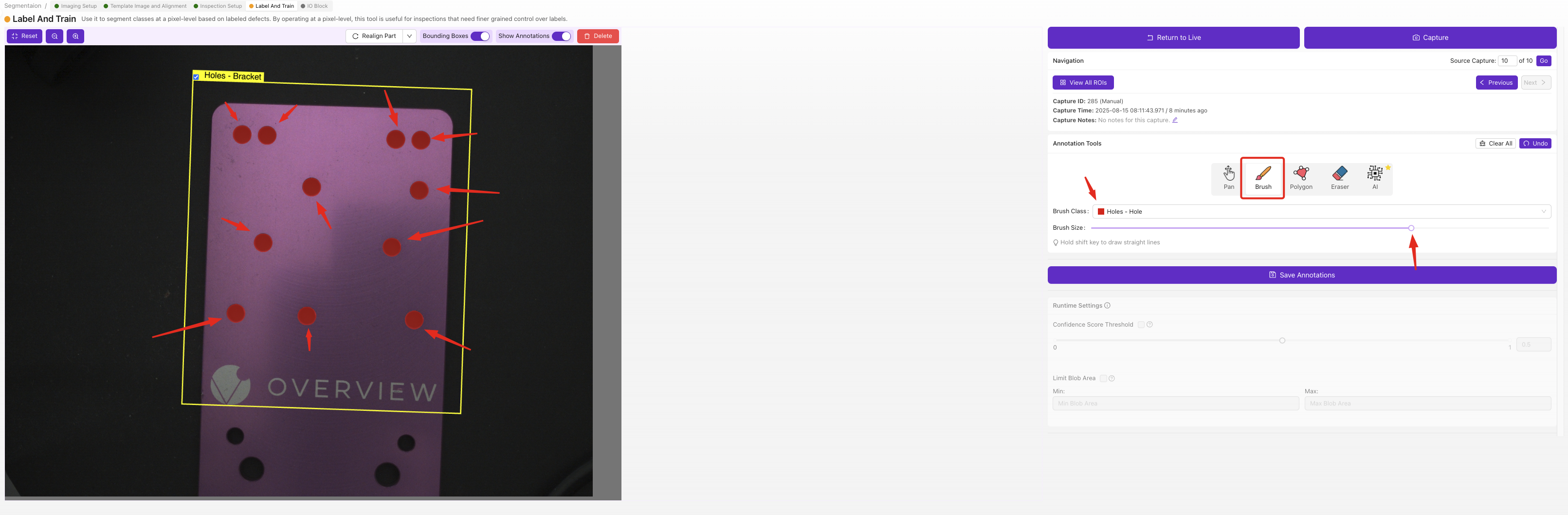
對於每個影象中的每個ROI,使用畫筆工具逐畫素塗繪缺陷區域。塗繪的區域即AI學習檢測的內容,未塗繪的部分將被視為背景。
分割器標籤需要進行畫素級的塗繪,比分類器的下拉選擇更慢,但可以為您提供精確的缺陷對映圖,包含位置和形狀資訊。建議從一小組定義明確的缺陷開始,待您的第一個模型可用後再新增更多類別。
4. 訓練模型
- Classifier
- Segmenter
點選 訓練。分類器提供兩種訓練模式:
- Fast 模式,約 30 秒到 1 分鐘。最適合在設定階段進行快速迭代、檢查標籤的合理性以及處理簡單/區分明顯的零件。準確率低於生產模式,但能讓您快速看到訊號。
- Production 模式,所需時間較長,但生成的模型準確度顯著更高。在部署到生產線之前請始終使用 Production 模式。對於棘手的零件、難以區分的缺陷或任何您要在生產中信賴的內容,Production 模式是正確的選擇。
良好的節奏:在清理標籤和新增資料時使用 Fast 模式進行迭代,待結果看起來不錯時執行一次 Production,並在部署之前再執行一次。
點選 訓練。分割只有一種訓練模式,即 Production,因為畫素級掩碼需要更全面的訓練過程才能可靠。訓練時間隨影象數量和您標註的ROI數量增加而增長,因此較小的初始集(每個類別 10-15 張影象)只需幾分鐘即可完成訓練;更大的資料集則需要更長時間。
此處沒有 "fast" 合理性檢查選項,因此請確保在訓練之前標籤是乾淨的(使用 View All ROIs 來檢視每個掩碼)。
分割器只能學習您實際塗繪並展示給它的缺陷。您包含的示例越多(涵蓋缺陷可能出現的不同尺寸、形狀和位置),它在生產中對這些缺陷進行掩碼的可靠性就越高。
缺陷樣本不足? 使用 Defect Creator Studio 生成更多包含相同缺陷但具有不同尺寸、形狀和位置的訓練影象,這樣您就不必等待它們出現在生產線上。
5. 使用實時預覽進行測試
點選 實時預覽模式 並讓零件透過。觀察結果:
- 它能正確處理簡單的情況嗎?
- 它在哪些方面有困難?
- 哪些是邊界情況?
嘗試讓它出錯。 找出它失敗的情況。這些失敗就是改進的路線圖。
- Classifier
- Segmenter

測試面板顯示每個ROI預測的類別和置信度分數。執行幾次捕獲並查詢低置信度的判定(通常低於70%),這些是邊界情況,也是最值得接下來進行標註的零件。
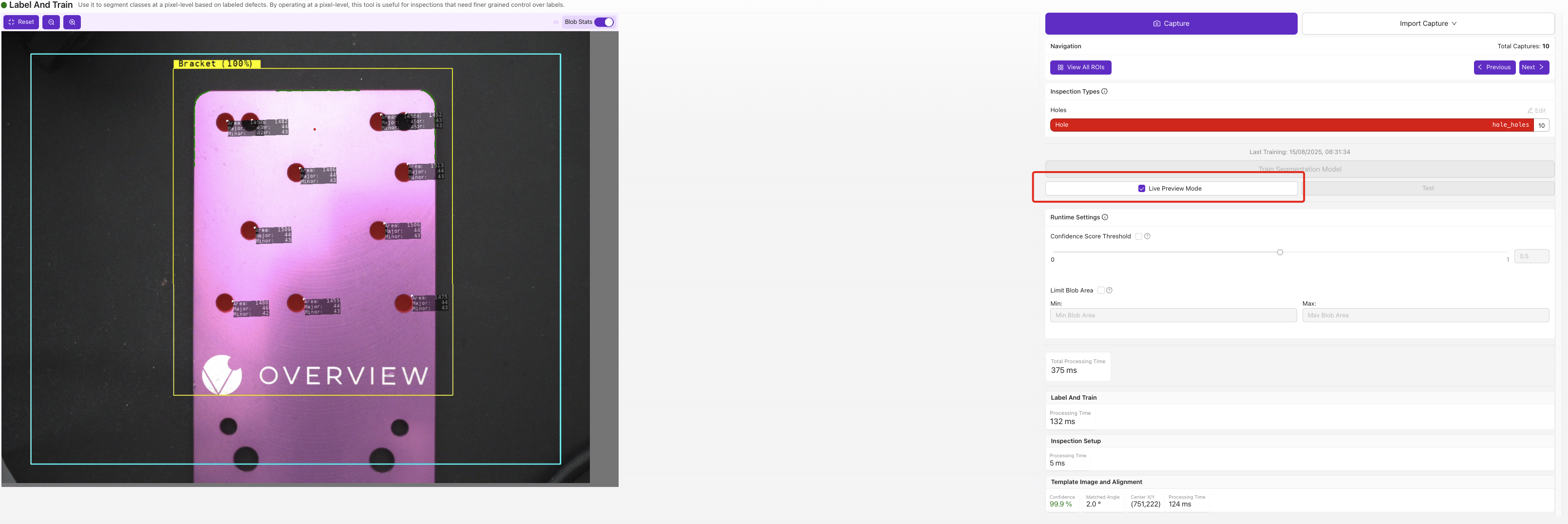
實時預覽將預測的缺陷掩碼直接疊加在影象上。注意那些過小、過大或出現在沒有實際缺陷位置的掩碼,這些就是您下一輪標註資料需要針對的失敗模式。
6. 新增針對性資料
不要隨意新增新影象。新增專門針對您發現的失敗模式的影象:
- 如果它將劃痕與反光混淆,新增更多這兩種情況的示例
- 如果它漏檢小缺陷,新增更多小缺陷的影象
- 如果它在角落處的零件上失敗,新增更多角落示例
7. 重新訓練和重新測試
重複步驟4-6,進行兩到四次。每次迭代都應提高準確性。如需更深入的演示,包括如何在不丟失之前訓練成果的情況下向現有模型新增新影象,請參閱 新增資料與重新訓練。
您在建立程式時選擇的模型會有自己的步驟:分類器的 步驟4:分類,或分割器的 步驟4:分割。您的類別已在 感興趣區域 (ROIs) 步驟中定義,因此這一步驟用於捕獲影象、標註、訓練和測試。兩者頂部共享相同的六個子選項卡。選擇您的模型型別:
- Classifier
- Segmenter
關於分類
獲取準確模型的簡短指南。它闡述了迭代以達到準確度的迴圈(快速訓練、在實時預覽中發現弱點、新增針對性資料、重新訓練,然後推廣到高精度的 生產 模型)以及最重要的每類最佳實踐:平衡您的類別、保持高訊雜比、覆蓋您想檢測內容的極端情況。如需更深入瞭解分類器如何將每個ROI轉換為判定結果,請閱讀 理解分類器。
捕獲與標註
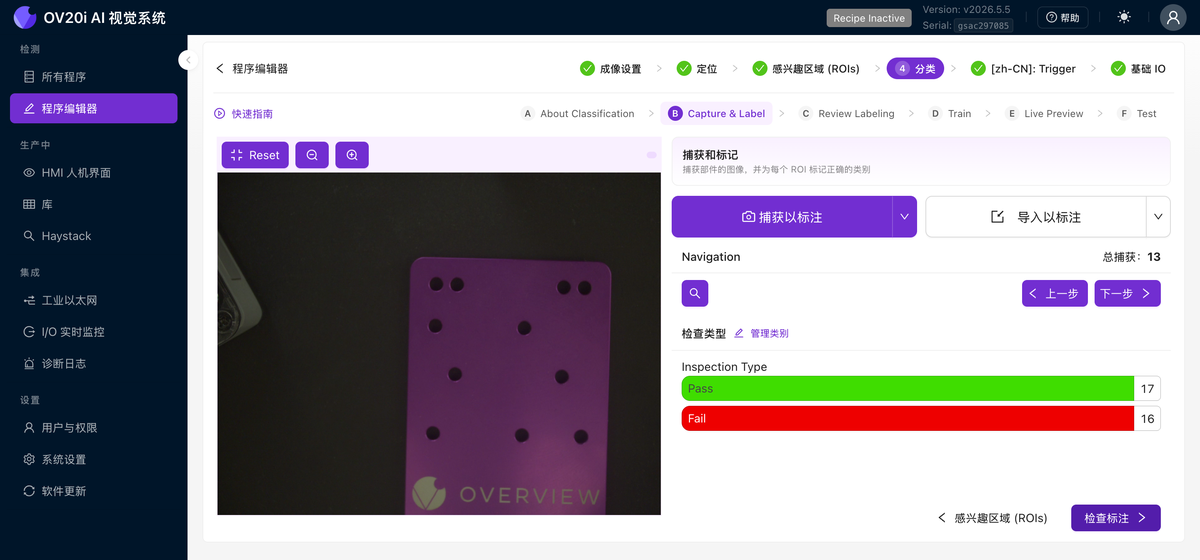
在此構建您的資料集。使用 捕獲以標註 從實時相機抓取幀,或使用 匯入以標註 引入已儲存的影象。導航 控制元件(上一個、下一個、按捕獲ID搜尋以及總捕獲數)可讓您瀏覽整個集合。對於每個捕獲,將每個ROI分配到其所屬的類別之一。每類計數(例如 透過 17 / 失敗 16)一目瞭然地顯示您的資料集的平衡程度,管理類別 可跳轉到定義類別的位置。
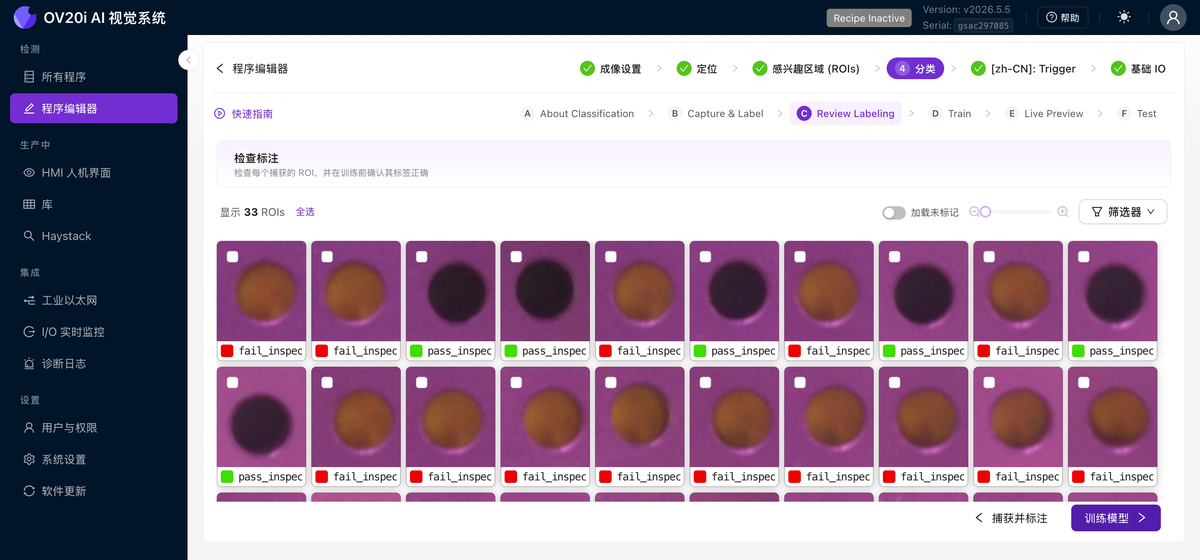
審查標籤
在單個網格中顯示每個已標註的 ROI 裁剪圖,每個都標有其類別,以便您快速掃描查詢錯誤標籤。使用篩選器和全選來批次處理它們。這就是 v2026.5 中"訓練前檢查每個標籤"習慣的所在之處。
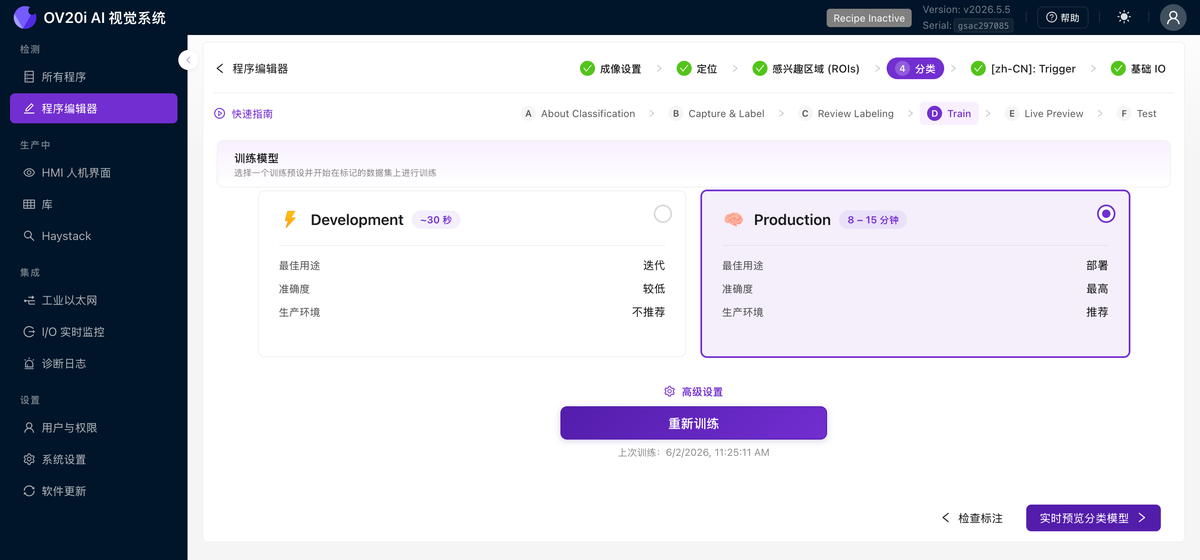
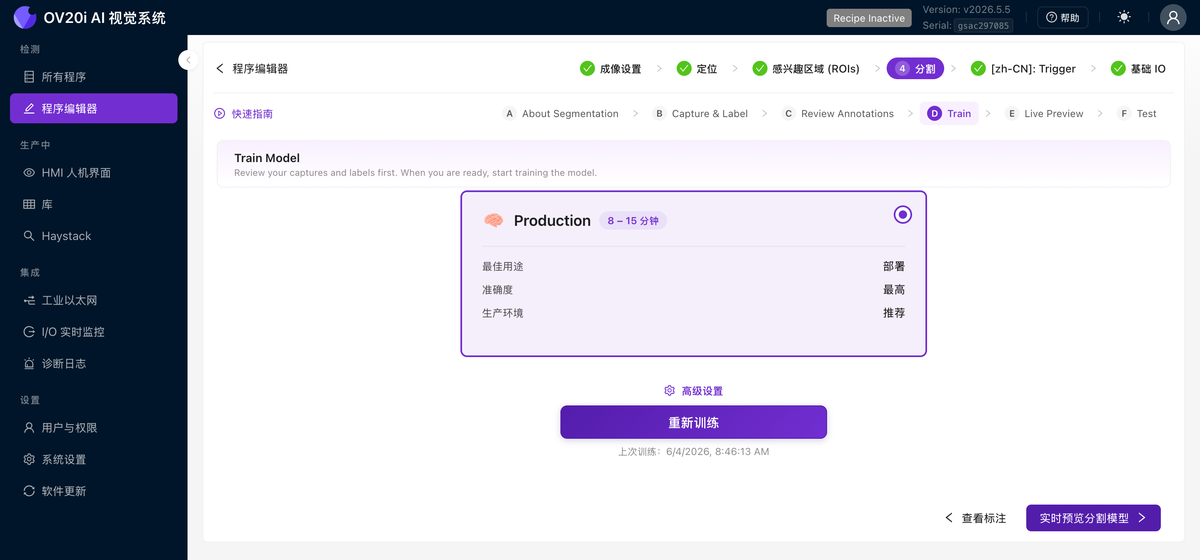
訓練
選擇一個預設並在您標註的資料集上開始訓練:
- Development 執行大約需要 30 秒。準確度較低,但它是您在清理標籤和新增資料時使用的快速迴圈。
- Production 需要 8 到 15 分鐘。它是您部署到產線的高精度模型。
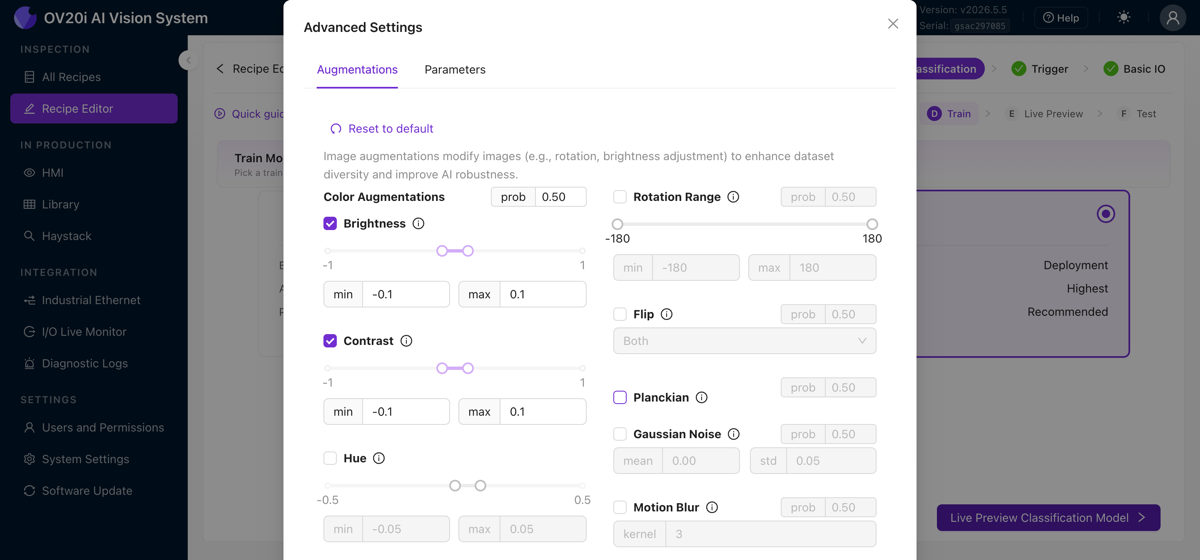
Advanced Settings 開啟資料增強(亮度、對比度、色調、旋轉、翻轉、Planckian、高斯噪聲、運動模糊)和訓練引數。請參閱下方的 資料增強 瞭解何時使用每種增強。Retrain 在您新增資料後再次執行訓練,上次訓練時間顯示在其旁邊。
實時預覽
在實時畫面上實時執行已訓練的模型。它顯示每個 ROI 的預測類別以及對齊置信度和匹配角度,並按模型(分類、ROI、模板和對齊)細分處理時間,因此您可以看到週期時間花在哪裡。讓零件透過並查詢低置信度的判定結果;那些邊界零件就是接下來值得標註的物件。
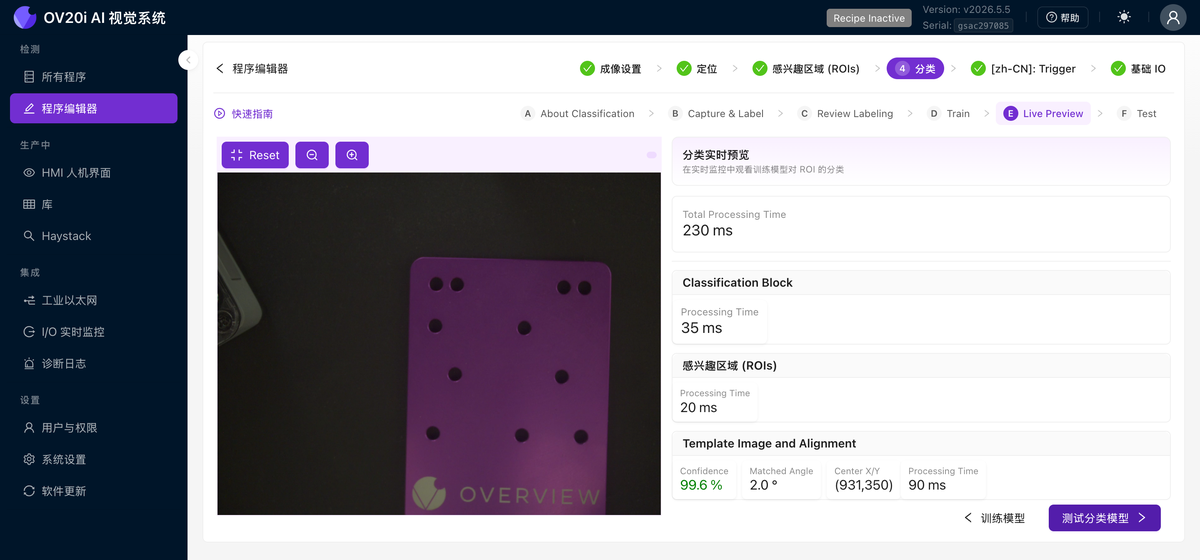
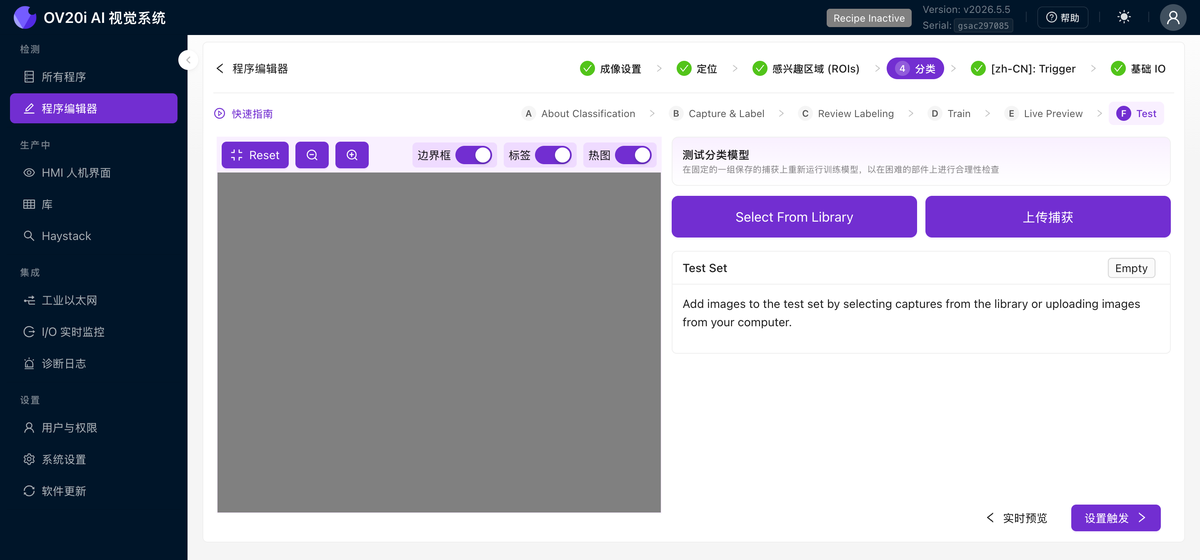
測試
針對一組固定的已儲存捕獲(Select From Library 或 Upload Captures)重新執行已訓練的模型,以便您可以在難處理的零件上進行合理性檢查,而無需等待它們到達產線。切換 Bounding Boxes、Labels 和 Heatmap,以檢視模型如何做出判斷。
關於分割
與分類器相同的迭代至精確的方法,但具有針對掩碼的最佳實踐:繪製乾淨的掩碼,寧願在缺陷邊緣略有重疊也不要留下間隙,並涵蓋您預期的全部缺陷尺寸和紋理範圍。要深入瞭解分割器如何生成畫素掩碼、計數和測量值,請閱讀 理解分割器。
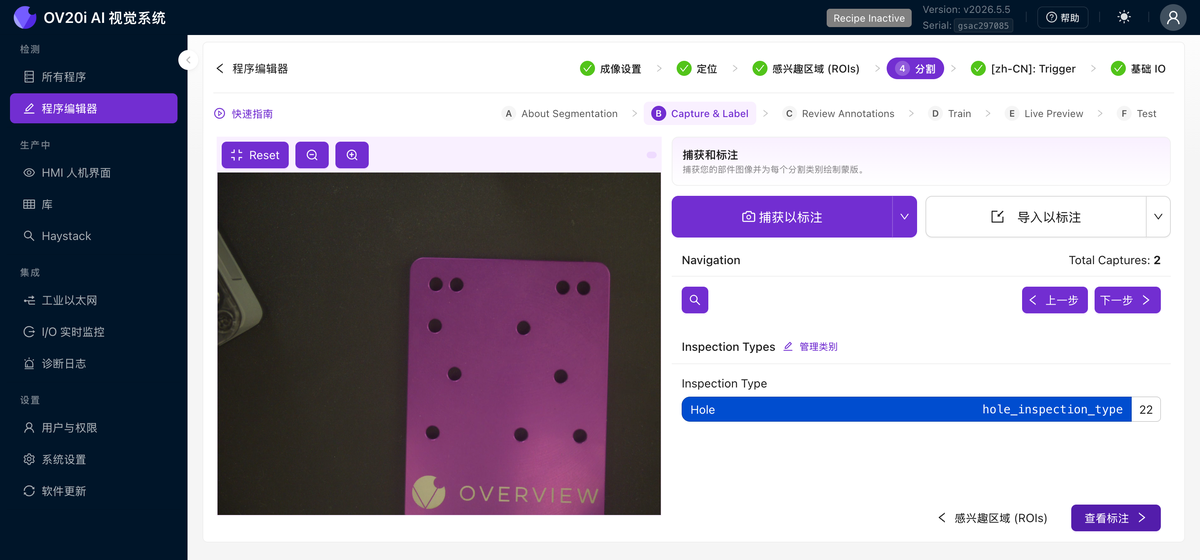
捕獲和標註
您以相同的方式構建資料集,但不是為每個 ROI 選擇一個類別,而是繪製一個掩碼。使用 Capture to Label 或 Import to Label,然後使用 Navigation 控制元件逐個瀏覽捕獲影象。選擇您要標註的類別(每個類別都有自己的畫筆顏色),然後在影象上的缺陷上進行繪製。繪製的畫素就是模型學習的內容;未繪製的所有內容都是背景。
標註工具欄為每種情況提供了一個工具:
| 工具 | 功能 |
|---|---|
| Pan | 在不繪製的情況下移動影象(在放大時使用) |
| Brush | 自由繪製掩碼;調整畫筆大小以進行精細或寬幅筆觸 |
| Polygon | 點選點以用直邊圍合一個區域,對於硬邊缺陷很有用 |
| Eraser | 從您已繪製的掩碼中移除塗繪 |
| AI | AI 輔助標註:點選缺陷,工具會提出一個掩碼,您可以接受或細化 |
還有一些其他控制元件可加快速度:
- Predict 在捕獲影象上執行您已訓練的模型,並將其預測的掩碼作為起點放入,這樣您就可以對其進行清理,而不是從頭開始繪製。這僅在您至少訓練過一次模型後才有效。
- Undo 撤銷上一筆筆觸。
- Clear All 清除當前捕獲上的掩碼。
- Manage classes 跳轉到類別列表。
檢視標註
顯示每個已捕獲的 ROI 及其繪製的掩碼,以便您在訓練前檢查覆蓋情況。拖動 Mask opacity 滑塊以將掩碼與影象進行比較,並使用 Filters 縮小集合範圍。這是分割器版本的"訓練前檢查每個標籤"的習慣。
訓練
分割只有一個預設,生產(約 8 到 15 分鐘)。沒有快速選項,因為畫素級掩碼需要完整的訓練過程才能可靠。Advanced Settings 顯示資料增強和引數,Retrain 在您新增資料後再次執行。
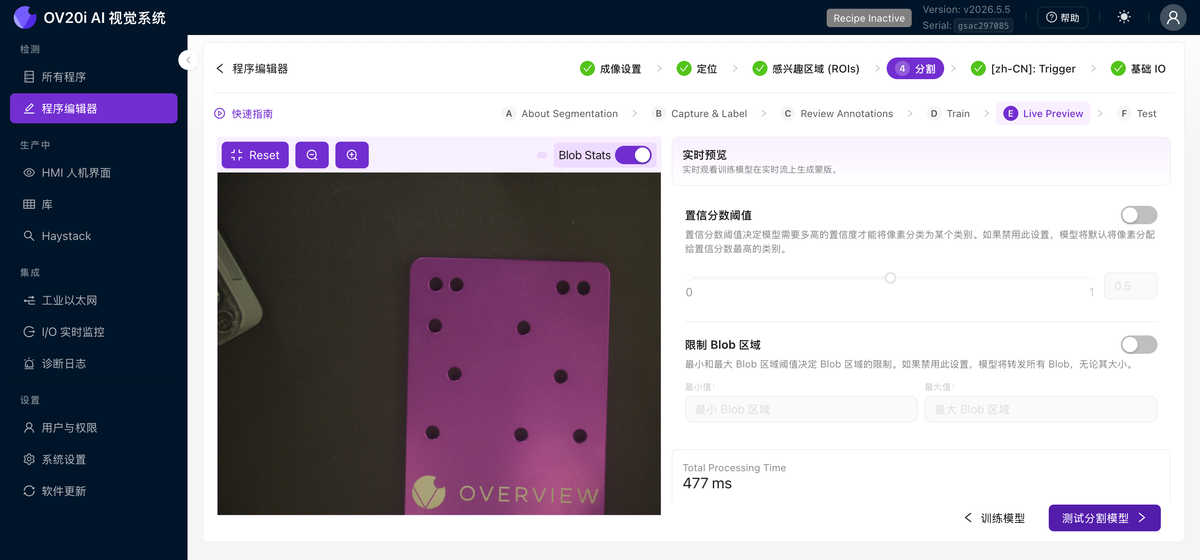
實時預覽
在實時畫面上執行已訓練的模型,並實時疊加預測的缺陷掩碼。開啟 Blob Stats 以檢視每個 blob 的計數和麵積,設定 Confidence Score Threshold(模型將畫素分配到某個類別所需的把握程度),並使用 Limit Blob Area 忽略低於或高於您設定大小的 blob。注意掩碼是否太小、太大,或者出現在沒有實際缺陷的位置。
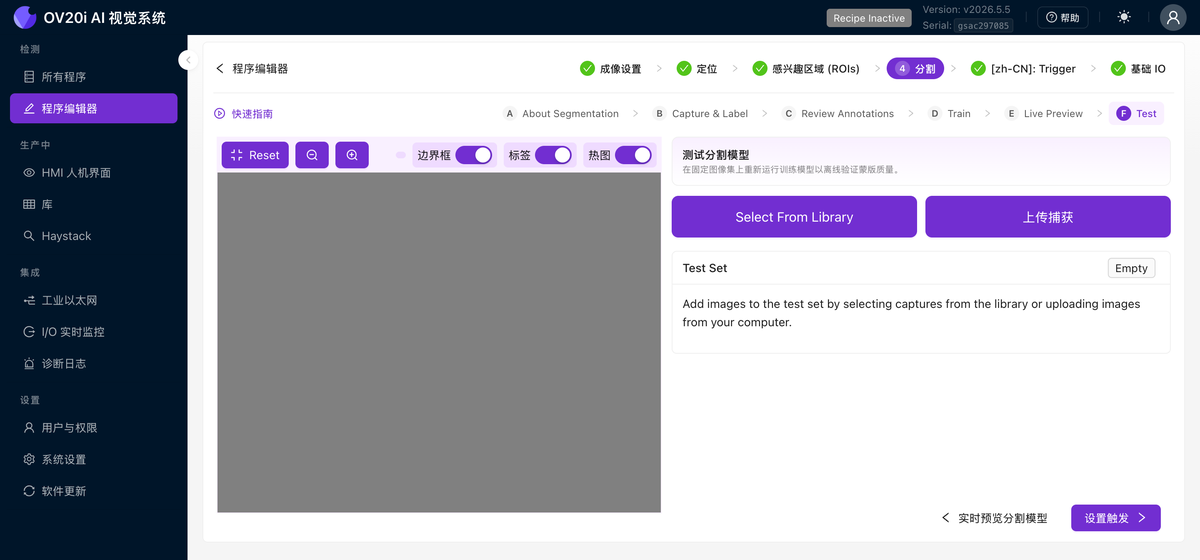
測試
針對一組固定的已儲存捕獲(Select From Library 或 Upload Captures)重新執行已訓練的模型,以離線驗證掩碼質量。切換 Bounding Boxes、Labels 和 Heatmap,檢視模型是如何決策的。
分割器只會學習您實際繪製並展示給它的缺陷。儘可能包含更多示例,涵蓋缺陷可能出現的不同大小、形狀和位置。如果樣本不足,可使用 Defect Creator Studio 生成更多樣本。
資料增強:教 AI 應對變化
資料增強在訓練過程中隨機修改您的訓練影象,調整亮度、新增旋轉、調整對比度等。每張影象都會以略有不同的資料增強方式被輸入 AI 數百次,但標籤保持不變。這就是您如何讓模型對真實世界條件具有魯棒性,而無需捕獲每種可能變化的示例。
預設應開啟哪些
少量的 brightness 變化幾乎總是值得開啟,即使是控制最嚴格的工廠也會有頂燈閃爍、班次中陰影移動以及隨時間產生的輕微 LED 漂移。亮度資料增強幾乎免費地讓模型對所有這些情況都具有韌性。
旋轉:有用,但要注意您的 ROI 形狀
旋轉資料增強非常適合 當您的零件確實可能以不同角度到達時(傳送帶上的鬆動螺絲、手工放置的零件,任何未被夾具固定的零件)。但它與 ROI 形狀會相互影響:
- 方形 ROI: 旋轉資料增強可以乾淨地工作,旋轉後的影象仍能適配 ROI 框內。
- 分類器上的非方形 ROI: 旋轉可能會裁剪影象。當一個高而窄的 ROI 旋轉 45° 時,旋轉內容的角會落在框外,模型將在不完整的影象上進行訓練。如果您的零件可能旋轉,要麼將 ROI 設為方形,要麼依賴 對齊器 在上游處理旋轉,這樣此處就不需要旋轉資料增強。
- 分割器: 同樣存在裁剪問題,但分割對此不那麼敏感,因為它從畫素掩碼而非整個 ROI 形狀中學習。
資料多樣性很重要
您的訓練資料應代表 AI 在生產中將看到的全部範圍:
- 一天中的不同時間(如果光照有變化)
- 不同批次的零件(表面光潔度可能略有不同)
- 處於畫面中不同位置的零件
- 簡單和困難的情況均需涵蓋
重點關注最困難的案例。 如果您的訓練資料包含 10 個最難分類的零件,那麼其餘 90% 簡單的零件對 AI 來說將毫不費力。
您實際需要多少資料
您需要的資料比大多數 AI 系統都少得多。大多數檢測只需每個類別 5 到 10 張影象 即可良好工作。對於較難的多缺陷問題,每個類別 15 到 20 張影象 通常已綽綽有餘。從少量開始,在實時預覽中找到模型表現不佳的地方,然後僅在需要時針對性地新增影象,而不是一開始就收集數百張。
使用合成資料加速:Defect Studio
如果您需要針對一種很少見的缺陷進行訓練怎麼辦?比如一顆您必須故意擰下的螺絲、一道您必須刻意製造的劃痕、或一千個零件中才出現一次的裂紋?等待數月以收集足夠的樣本是不切實際的。
OV Auto-Defect Creator Studio(位於 tools.overview.ai)解決了這個問題。它能生成逼真的合成缺陷影象,比等待生產線上出現真實缺陷快最多 10,000 倍。
工作原理:5 個簡單步驟
- 上傳一張零件的良品影象
- 標記缺陷應出現的區域
- 用簡明英文描述缺陷(例如,"deep scratch across the surface" 或 "missing solder joint")
- 生成缺陷變體(AI 生成逼真的結果)
- 將合成影象直接匯出到您的訓練集
為什麼合成資料有效
生成的影象不僅僅是"貼上去"的偽影。它們是與您實際的光照、相機角度和零件表面相匹配的逼真變體。AI 能理解在您特定的成像條件下缺陷的物理表現。
使用場景:
- 罕見缺陷: 針對從未見過(或很少見到)的故障模式進行訓練
- 新產品釋出: 在第一個有缺陷的零件下線之前就建立檢測
- 邊緣案例: 生成邊界示例以改善 AI 的決策邊界
- 資料增強: 用合成的多樣性補充小資料集
觀看實際演示
最佳方法:先使用您最初的 3-5 張真實影象進行訓練,找出 AI 表現不佳的地方,然後使用 Defect Studio 針對這些特定故障模式生成有針對性的合成示例。真實資料教會基線;合成資料填補空白。
訓練檢查清單
繼續之前,請確認:
- 已捕獲初始影象,每個類別至少 10-15 張
- 已仔細核對所有標籤(View All ROIs)
- 已使用實時預覽完成訓練和測試
- 已識別失敗模式並新增針對性資料
- 已完成 2-4 輪 標註 → 訓練 → 測試 迭代
- 結果符合預期
模型已訓練好且表現良好?請前往 第 5 步:設定輸出。