AI 驱动文档
您想了解什么?
第四步:训练您的 AI 模型
您的感兴趣区域(ROI)已设置完成。现在该教 AI 识别什么是"好"和"坏"了。
训练的三大基本原则
在开始之前,请牢记这三条原则。无论您是训练分类器还是分割器,使用 5 张图像还是 500 张图像,这些原则都适用。
原则 1:仅从图像进行标注
永远不要通过查看实物零件(或将其置于显微镜下)来判断它是好是坏。如果您在相机图像中看不到缺陷,AI 就无法学习它。
AI 并非魔法。它只能根据相机所见的内容工作。如果您因触摸零件或用放大镜放大而注意到某些问题,从而将其标注为"缺陷",但相机图像看起来正常,那么您就是在教 AI 看见不存在的东西。
如果您无法仅从图像进行标注,请返回安装步骤,修正物理设置:更好的镜头、更好的光源、更近的安装位置、不同的角度。
原则 2:反复核对您的标签
每个人都会出现误标;经验丰富的工程师也不例外。但在小数据集中,一个错误的标签就可能摧毁您的结果。
在 5 张训练图像中,一个误标会污染 20% 的训练数据。这是灾难性的。
每次训练之前: 点击 View All ROIs,逐一核实每条标注。这是最容易修正且影响最大的事情。
原则 3:从小处着手,快速迭代
不要标注 50 张图像然后直接训练。相反,请创建一个紧凑的循环:每类标注 10-15 张图像,进行训练(约 30 秒),然后测试并尝试找出问题,再针对失败之处添加有针对性的数据。重复这个循环 2-4 次。
这个循环是通往优秀模型的最快路径。
分步训练工作流程
OV20i Web 界面在 v2026.5 中进行了重新设计。请在相机 UI 的右上角查看您的软件版本,并选择匹配的选项卡。您的选择将在此设置流程的每个页面上保持一致。
- 较旧版本
- v2026.5 and newer
按照下面的编号步骤进行捕获、标注、训练和迭代。
1. 捕获初始训练图像
在程序激活且零件正在流动(或手动放置)的情况下,捕获图像。开始时每类至少需要 10-15 张图像。
对于简单的通过/失败检测:
- 10-15 张良品图像
- 10-15 张缺陷品图像
2. 定义您的分类
选择您要训练的模型类型,然后阅读相应的说明。下方的切换在第 2 步和第 3 步之间保持同步,您的选择会保存在 URL 中,因此即使刷新或分享也不会丢失。
- 分类器
- 分割器
在标注界面中,添加每种检测类型所需的分类。常见的分类器类别集:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
最初保持简单。您随时可以稍后添加分类。
在标注界面中,为您希望 AI 进行掩膜处理的缺陷(或特征)添加分类。常见的分割器类别集:
- Defect / Background
- Scratch / Crack / Stain
- Foreground / Background
最初保持分类列表简短。每个分类都需要自己的画笔颜色和已标注示例,因此预先添加更多分类会成倍增加您的标注工作量。
3. 标注图像
- Classifier
- Segmenter
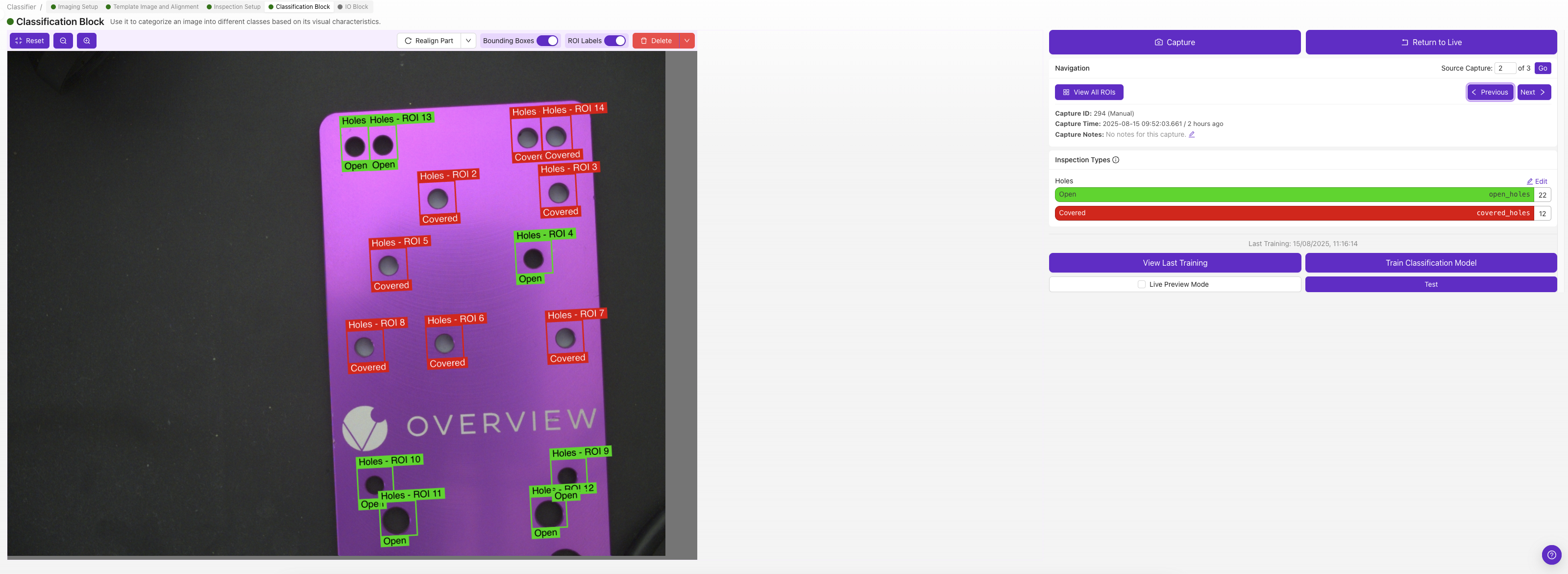
每个ROI都有自己的分类类别,请选择能描述该图像中该ROI的类别(例如"pass"或"fail")。
如果您不确定使用分类还是分割,请从分类开始。它的标注速度更快,并且适用于大多数通过/失败场景。请参阅Classifier vs. Segmenter 获取指导。
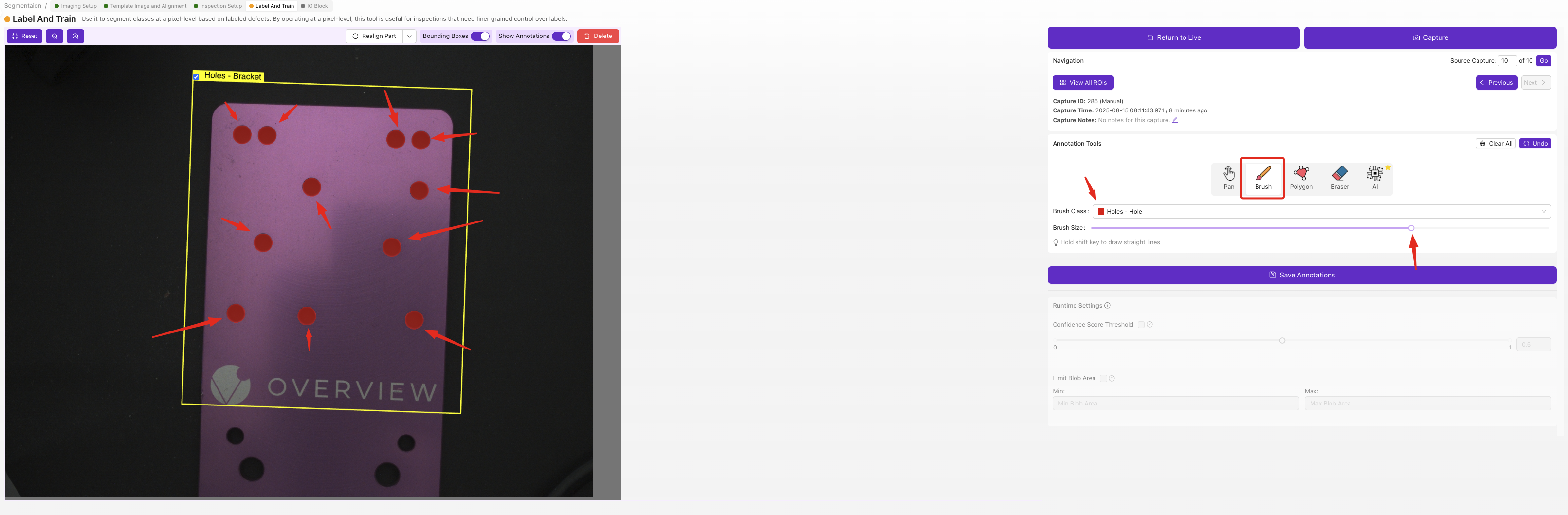
对于每个图像中的每个ROI,使用画笔工具逐像素涂绘缺陷区域。涂绘的区域即AI学习检测的内容,未涂绘的部分将被视为背景。
分割器标签需要进行像素级的涂绘,比分类器的下拉选择更慢,但可以为您提供精确的缺陷映射图,包含位置和形状信息。建议从一小组定义明确的缺陷开始,待您的第一个模型可用后再添加更多类别。
4. 训练模型
- Classifier
- Segmenter
点击 训练。分类器提供两种训练模式:
- Fast 模式,约 30 秒到 1 分钟。最适合在设置阶段进行快速迭代、检查标签的合理性以及处理简单/区分明显的零件。准确率低于生产模式,但能让您快速看到信号。
- Production 模式,所需时间较长,但生成的模型准确度显著更高。在部署到生产线之前请始终使用 Production 模式。对于棘手的零件、难以区分的缺陷或任何您要在生产中信赖的内容,Production 模式是正确的选择。
良好的节奏:在清理标签和添加数据时使用 Fast 模式进行迭代,待结果看起来不错时运行一次 Production,并在部署之前再运行一次。
点击 训练。分割只有一种训练模式,即 Production,因为像素级掩码需要更全面的训练过程才能可靠。训练时间随图像数量和您标注的ROI数量增加而增长,因此较小的初始集(每个类别 10-15 张图像)只需几分钟即可完成训练;更大的数据集则需要更长时间。
此处没有 "fast" 合理性检查选项,因此请确保在训练之前标签是干净的(使用 View All ROIs 来查看每个掩码)。
分割器只能学习您实际涂绘并展示给它的缺陷。您包含的示例越多(涵盖缺陷可能出现的不同尺寸、形状和位置),它在生产中对这些缺陷进行掩码的可靠性就越高。
缺陷样本不足? 使用 Defect Creator Studio 生成更多包含相同缺陷但具有不同尺寸、形状和位置的训练图像,这样您就不必等待它们出现在生产线上。
5. 使用实时预览进行测试
点击 实时预览模式 并让零件通过。观察结果:
- 它能正确处理简单的情况吗?
- 它在哪些方面有困难?
- 哪些是边界情况?
尝试让它出错。 找出它失败的情况。这些失败就是改进的路线图。
- Classifier
- Segmenter

测试面板显示每个ROI预测的类别和置信度分数。运行几次捕获并查找低置信度的判定(通常低于70%),这些是边界情况,也是最值得接下来进行标注的零件。
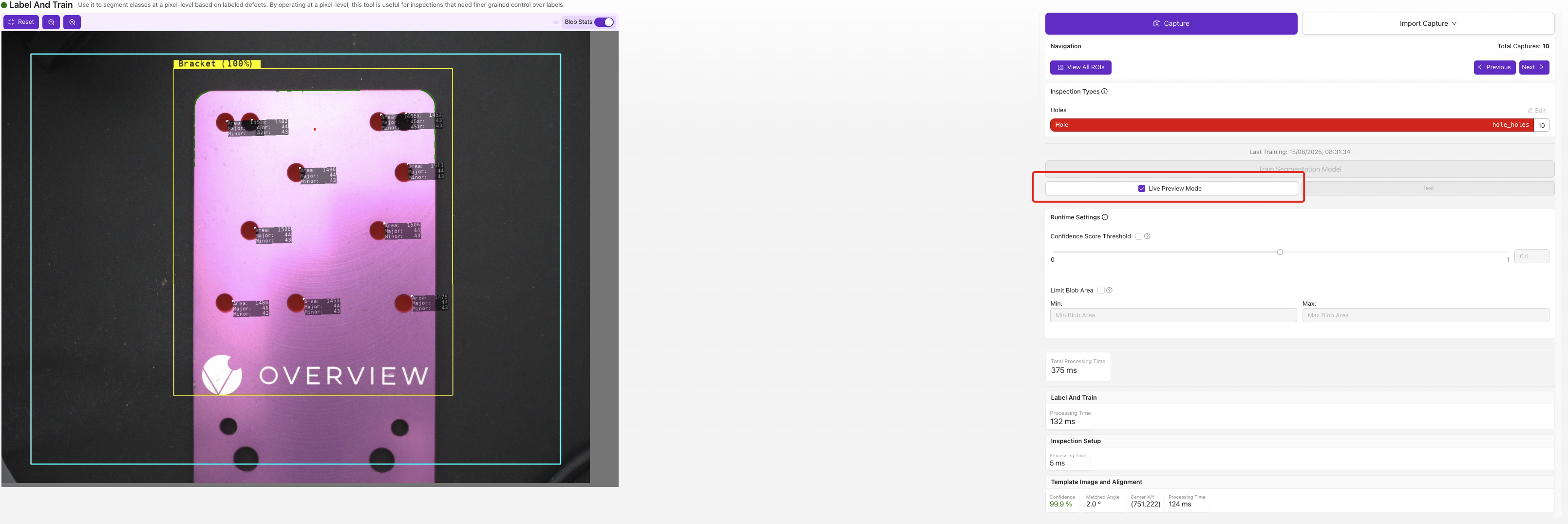
实时预览将预测的缺陷掩码直接叠加在图像上。注意那些过小、过大或出现在没有实际缺陷位置的掩码,这些就是您下一轮标注数据需要针对的失败模式。
6. 添加针对性数据
不要随意添加新图像。添加专门针对您发现的失败模式的图像:
- 如果它将划痕与反光混淆,添加更多这两种情况的示例
- 如果它漏检小缺陷,添加更多小缺陷的图像
- 如果它在角落处的零件上失败,添加更多角落示例
7. 重新训练和重新测试
重复步骤4-6,进行两到四次。每次迭代都应提高准确性。如需更深入的演示,包括如何在不丢失之前训练成果的情况下向现有模型添加新图像,请参阅 添加数据与重新训练。
您在创建程序时选择的模型会有自己的步骤:分类器的 步骤4:分类,或分割器的 步骤4:分割。您的类别已在 感兴趣区域 (ROIs) 步骤中定义,因此这一步骤用于捕获图像、标注、训练和测试。两者顶部共享相同的六个子选项卡。选择您的模型类型:
- Classifier
- Segmenter
关于分类
获取准确模型的简短指南。它阐述了迭代以达到准确度的循环(快速训练、在实时预览中发现弱点、添加针对性数据、重新训练,然后推广到高精度的 生产 模型)以及最重要的每类最佳实践:平衡您的类别、保持高信噪比、覆盖您想检测内容的极端情况。如需更深入了解分类器如何将每个ROI转换为判定结果,请阅读 理解分类器。
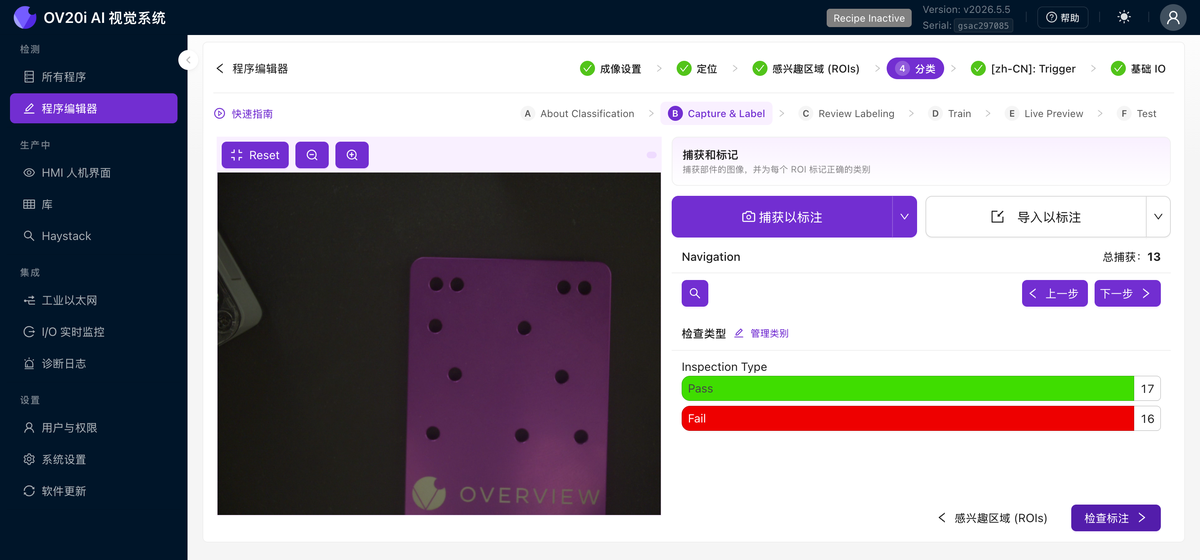
捕获与标注
在此构建您的数据集。使用 捕获以标注 从实时相机抓取帧,或使用 导入以标注 引入已保存的图像。导航 控件(上一个、下一个、按捕获ID搜索以及总捕获数)可让您浏览整个集合。对于每个捕获,将每个ROI分配到其所属的类别之一。每类计数(例如 通过 17 / 失败 16)一目了然地显示您的数据集的平衡程度,管理类别 可跳转到定义类别的位置。
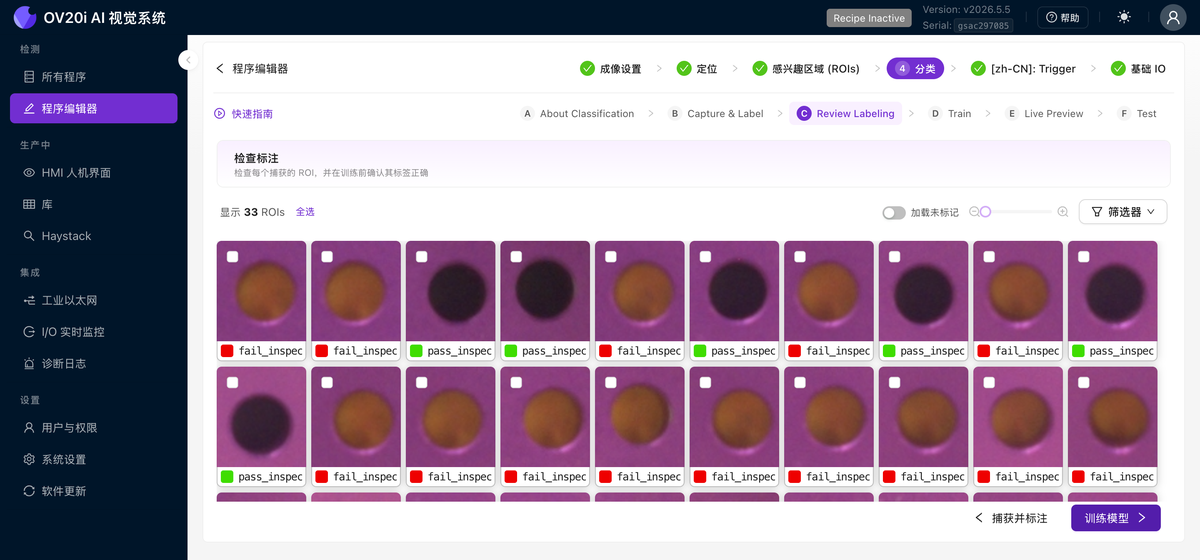
审查标签
在单个网格中显示每个已标注的 ROI 裁剪图,每个都标有其类别,以便您快速扫描查找错误标签。使用筛选器和全选来批量处理它们。这就是 v2026.5 中"训练前检查每个标签"习惯的所在之处。
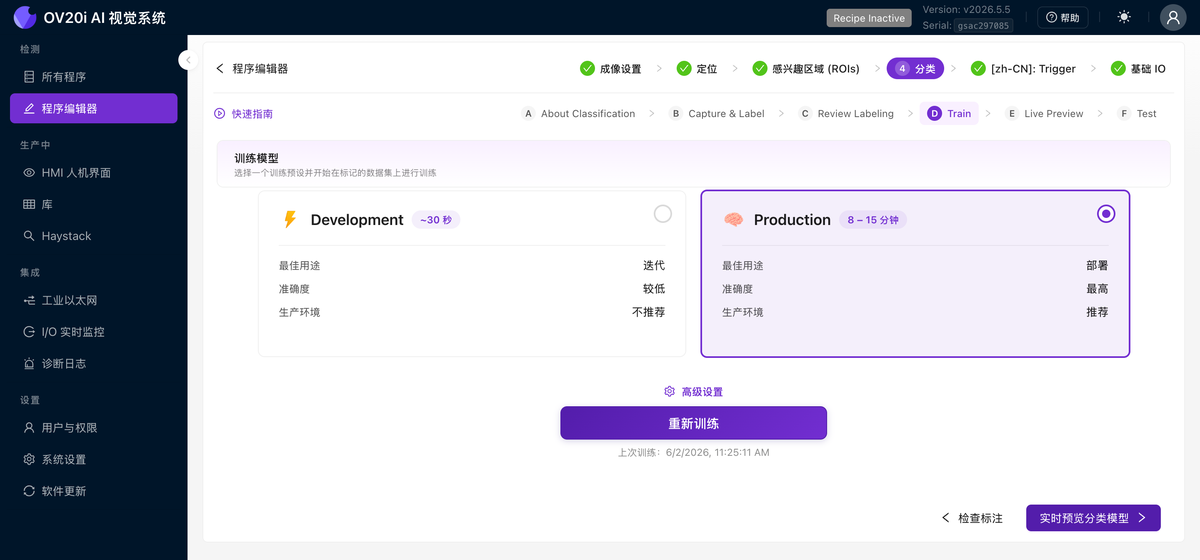
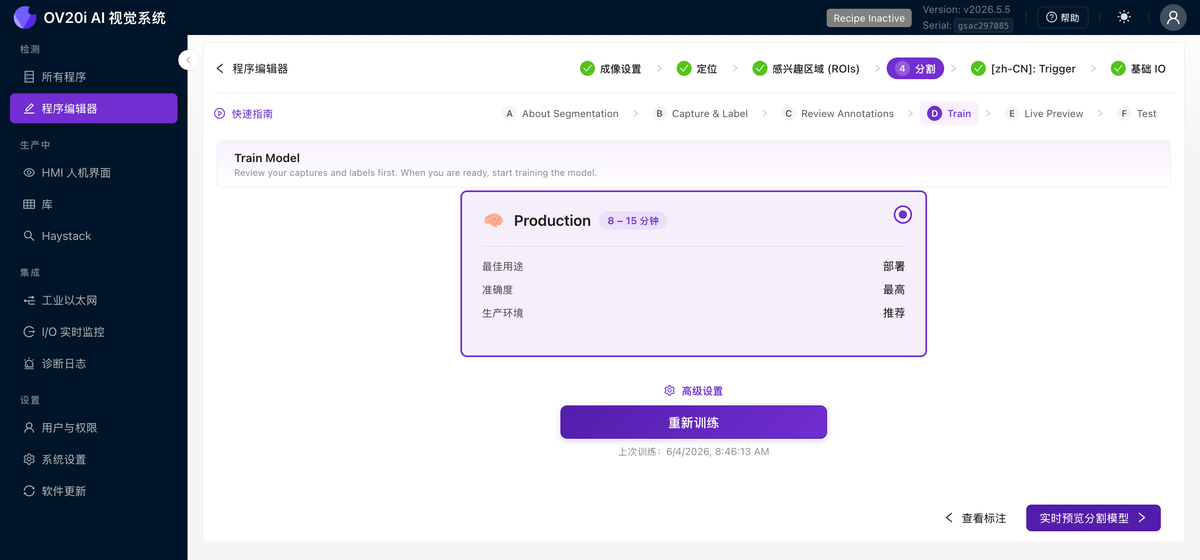
训练
选择一个预设并在您标注的数据集上开始训练:
- Development 运行大约需要 30 秒。准确度较低,但它是您在清理标签和添加数据时使用的快速循环。
- Production 需要 8 到 15 分钟。它是您部署到产线的高精度模型。
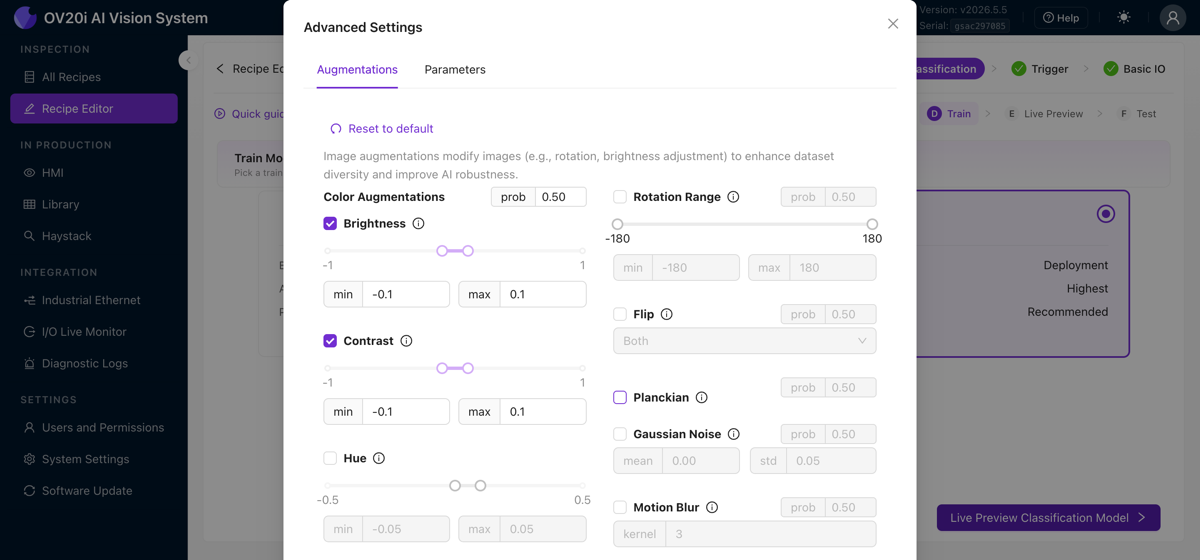
Advanced Settings 打开数据增强(亮度、对比度、色调、旋转、翻转、Planckian、高斯噪声、运动模糊)和训练参数。请参阅下方的 数据增强 了解何时使用每种增强。Retrain 在您添加数据后再次运行训练,上次训练时间显示在其旁边。
实时预览
在实时画面上实时运行已训练的模型。它显示每个 ROI 的预测类别以及对齐置信度和匹配角度,并按模型(分类、ROI、模板和对齐)细分处理时间,因此您可以看到周期时间花在哪里。让零件通过并查找低置信度的判定结果;那些边界零件就是接下来值得标注的对象。
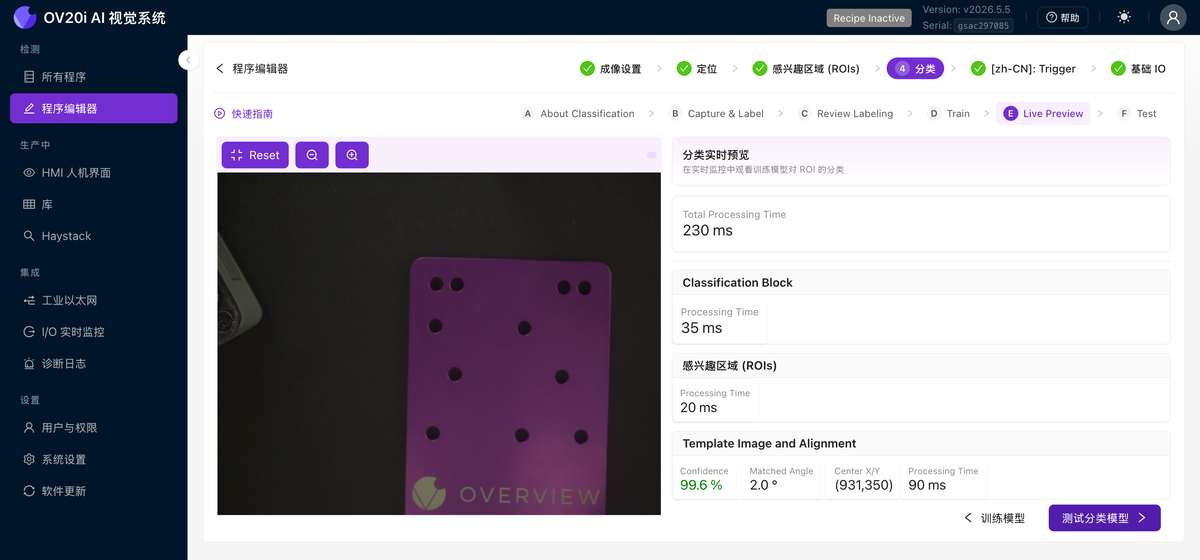
测试
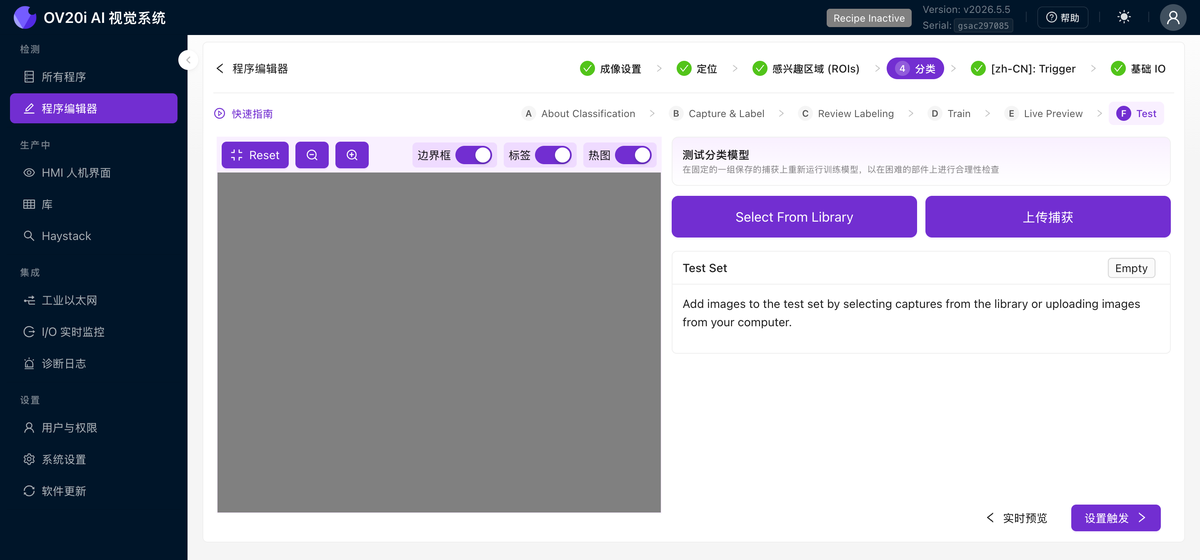
针对一组固定的已保存捕获(Select From Library 或 Upload Captures)重新运行已训练的模型,以便您可以在难处理的零件上进行合理性检查,而无需等待它们到达产线。切换 Bounding Boxes、Labels 和 Heatmap,以查看模型如何做出判断。
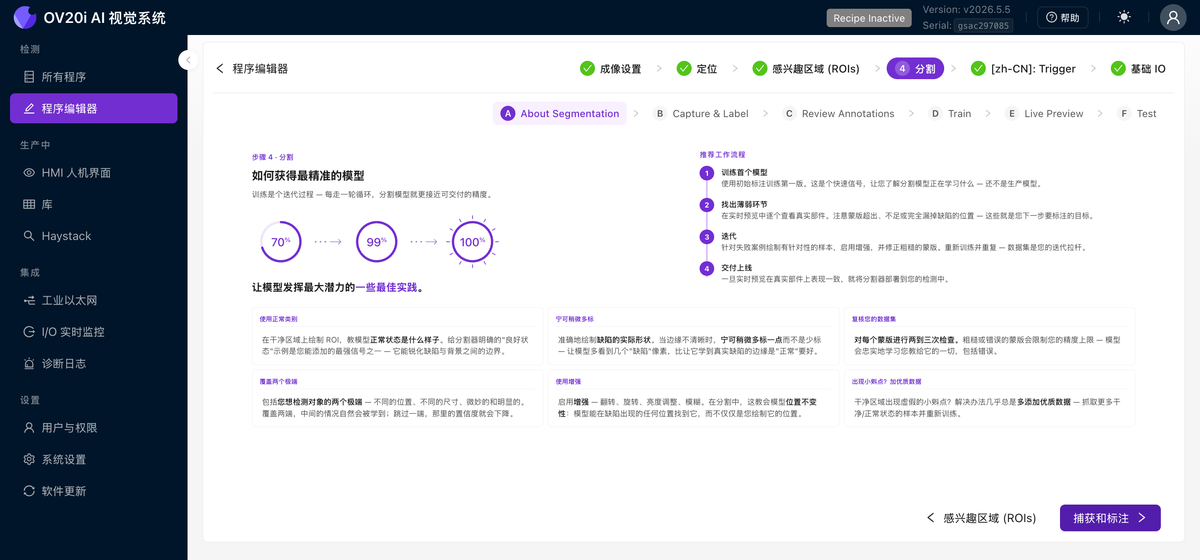
关于分割
与分类器相同的迭代至精确的方法,但具有针对掩码的最佳实践:绘制干净的掩码,宁愿在缺陷边缘略有重叠也不要留下间隙,并涵盖您预期的全部缺陷尺寸和纹理范围。要深入了解分割器如何生成像素掩码、计数和测量值,请阅读 理解分割器。
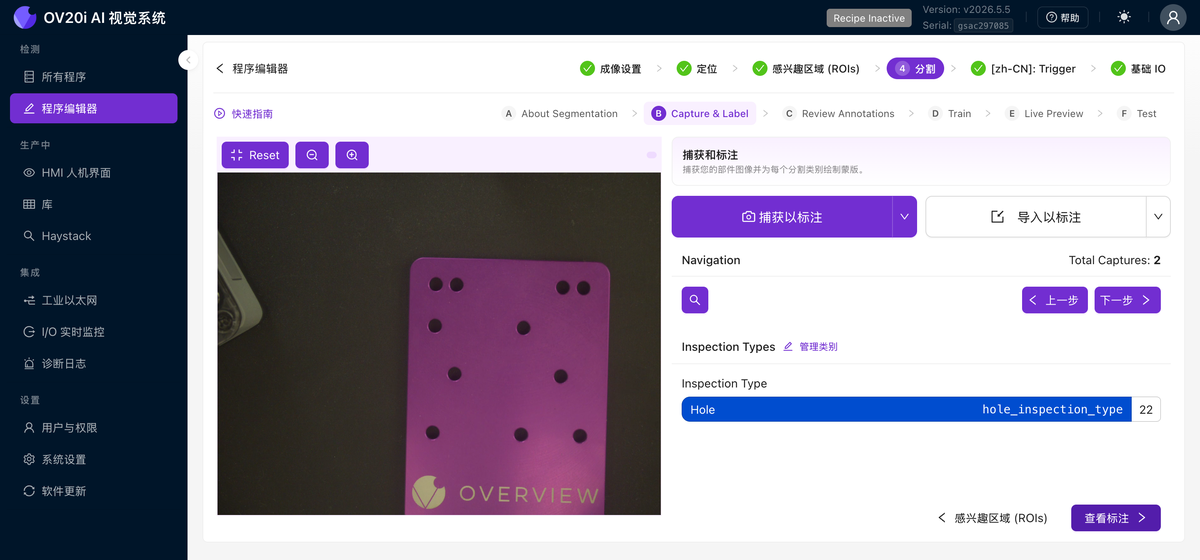
捕获和标注
您以相同的方式构建数据集,但不是为每个 ROI 选择一个类别,而是绘制一个掩码。使用 Capture to Label 或 Import to Label,然后使用 Navigation 控件逐个浏览捕获图像。选择您要标注的类别(每个类别都有自己的画笔颜色),然后在图像上的缺陷上进行绘制。绘制的像素就是模型学习的内容;未绘制的所有内容都是背景。
标注工具栏为每种情况提供了一个工具:
| 工具 | 功能 |
|---|---|
| Pan | 在不绘制的情况下移动图像(在放大时使用) |
| Brush | 自由绘制掩码;调整画笔大小以进行精细或宽幅笔触 |
| Polygon | 点击点以用直边围合一个区域,对于硬边缺陷很有用 |
| Eraser | 从您已绘制的掩码中移除涂绘 |
| AI | AI 辅助标注:点击缺陷,工具会提出一个掩码,您可以接受或细化 |
还有一些其他控件可加快速度:
- Predict 在捕获图像上运行您已训练的模型,并将其预测的掩码作为起点放入,这样您就可以对其进行清理,而不是从头开始绘制。这仅在您至少训练过一次模型后才有效。
- Undo 撤销上一笔笔触。
- Clear All 清除当前捕获上的掩码。
- Manage classes 跳转到类别列表。
查看标注
显示每个已捕获的 ROI 及其绘制的掩码,以便您在训练前检查覆盖情况。拖动 Mask opacity 滑块以将掩码与图像进行比较,并使用 Filters 缩小集合范围。这是分割器版本的"训练前检查每个标签"的习惯。
训练
分割只有一个预设,生产(约 8 到 15 分钟)。没有快速选项,因为像素级掩码需要完整的训练过程才能可靠。Advanced Settings 显示数据增强和参数,Retrain 在您添加数据后再次运行。
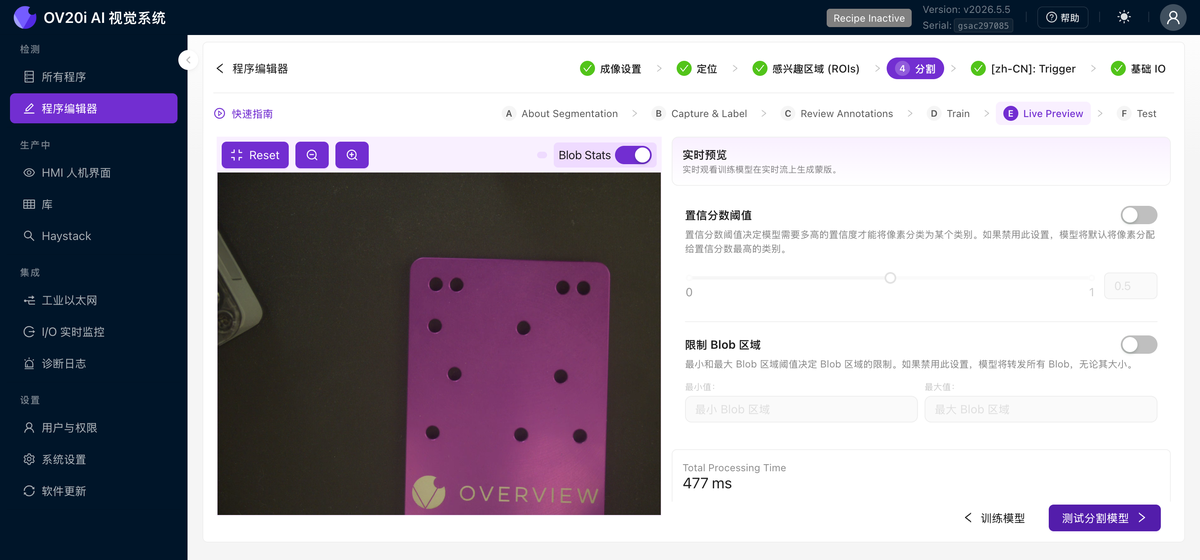
实时预览
在实时画面上运行已训练的模型,并实时叠加预测的缺陷掩码。开启 Blob Stats 以查看每个 blob 的计数和面积,设置 Confidence Score Threshold(模型将像素分配到某个类别所需的把握程度),并使用 Limit Blob Area 忽略低于或高于您设定大小的 blob。注意掩码是否太小、太大,或者出现在没有实际缺陷的位置。
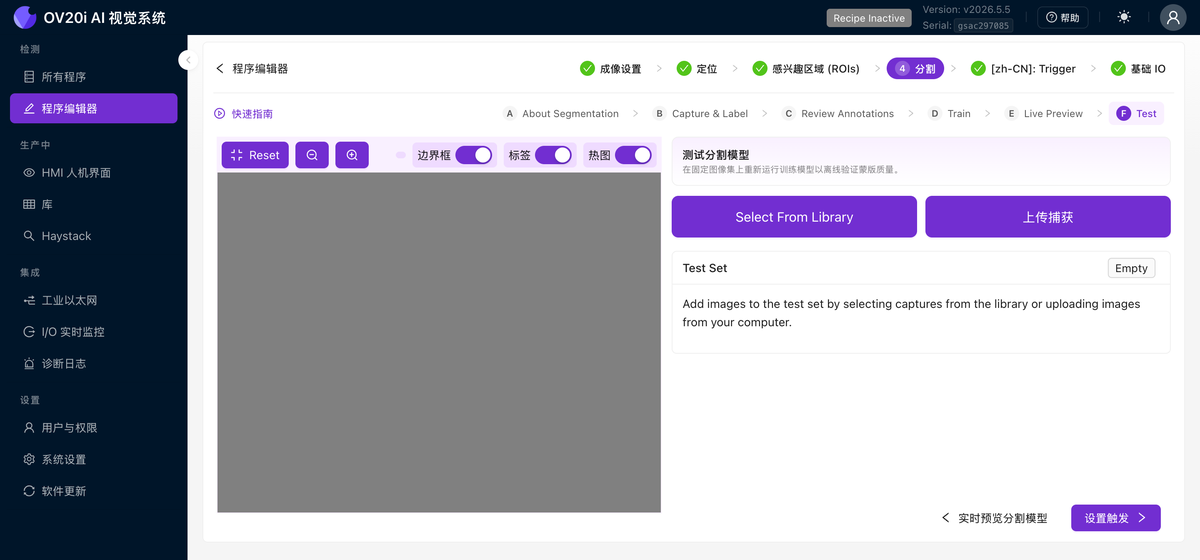
测试
针对一组固定的已保存捕获(Select From Library 或 Upload Captures)重新运行已训练的模型,以离线验证掩码质量。切换 Bounding Boxes、Labels 和 Heatmap,查看模型是如何决策的。
分割器只会学习您实际绘制并展示给它的缺陷。尽可能包含更多示例,涵盖缺陷可能出现的不同大小、形状和位置。如果样本不足,可使用 Defect Creator Studio 生成更多样本。
数据增强:教 AI 应对变化
数据增强在训练过程中随机修改您的训练图像,调整亮度、添加旋转、调整对比度等。每张图像都会以略有不同的数据增强方式被输入 AI 数百次,但标签保持不变。这就是您如何让模型对真实世界条件具有鲁棒性,而无需捕获每种可能变化的示例。
默认应开启哪些
少量的 brightness 变化几乎总是值得开启,即使是控制最严格的工厂也会有顶灯闪烁、班次中阴影移动以及随时间产生的轻微 LED 漂移。亮度数据增强几乎免费地让模型对所有这些情况都具有韧性。
旋转:有用,但要注意您的 ROI 形状
旋转数据增强非常适合 当您的零件确实可能以不同角度到达时(传送带上的松动螺丝、手工放置的零件,任何未被夹具固定的零件)。但它与 ROI 形状会相互影响:
- 方形 ROI: 旋转数据增强可以干净地工作,旋转后的图像仍能适配 ROI 框内。
- 分类器上的非方形 ROI: 旋转可能会裁剪图像。当一个高而窄的 ROI 旋转 45° 时,旋转内容的角会落在框外,模型将在不完整的图像上进行训练。如果您的零件可能旋转,要么将 ROI 设为方形,要么依赖 对齐器 在上游处理旋转,这样此处就不需要旋转数据增强。
- 分割器: 同样存在裁剪问题,但分割对此不那么敏感,因为它从像素掩码而非整个 ROI 形状中学习。
数据多样性很重要
您的训练数据应代表 AI 在生产中将看到的全部范围:
- 一天中的不同时间(如果光照有变化)
- 不同批次的零件(表面光洁度可能略有不同)
- 处于画面中不同位置的零件
- 简单和困难的情况均需涵盖
重点关注最困难的案例。 如果您的训练数据包含 10 个最难分类的零件,那么其余 90% 简单的零件对 AI 来说将毫不费力。
您实际需要多少数据
您需要的数据比大多数 AI 系统都少得多。大多数检测只需每个类别 5 到 10 张图像 即可良好工作。对于较难的多缺陷问题,每个类别 15 到 20 张图像 通常已绰绰有余。从少量开始,在实时预览中找到模型表现不佳的地方,然后仅在需要时针对性地添加图像,而不是一开始就收集数百张。
使用合成数据加速:Defect Studio
如果您需要针对一种很少见的缺陷进行训练怎么办?比如一颗您必须故意拧下的螺丝、一道您必须刻意制造的划痕、或一千个零件中才出现一次的裂纹?等待数月以收集足够的样本是不切实际的。
OV Auto-Defect Creator Studio(位于 tools.overview.ai)解决了这个问题。它能生成逼真的合成缺陷图像,比等待生产线上出现真实缺陷快最多 10,000 倍。
工作原理:5 个简单步骤
- 上传一张零件的良品图像
- 标记缺陷应出现的区域
- 用简明英文描述缺陷(例如,"deep scratch across the surface" 或 "missing solder joint")
- 生成缺陷变体(AI 生成逼真的结果)
- 将合成图像直接导出到您的训练集
为什么合成数据有效
生成的图像不仅仅是"贴上去"的伪影。它们是与您实际的光照、相机角度和零件表面相匹配的逼真变体。AI 能理解在您特定的成像条件下缺陷的物理表现。
使用场景:
- 罕见缺陷: 针对从未见过(或很少见到)的故障模式进行训练
- 新产品发布: 在第一个有缺陷的零件下线之前就建立检测
- 边缘案例: 生成边界示例以改善 AI 的决策边界
- 数据增强: 用合成的多样性补充小数据集
观看实际演示
最佳方法:先使用您最初的 3-5 张真实图像进行训练,找出 AI 表现不佳的地方,然后使用 Defect Studio 针对这些特定故障模式生成有针对性的合成示例。真实数据教会基线;合成数据填补空白。
训练检查清单
继续之前,请确认:
- 已捕获初始图像,每个类别至少 10-15 张
- 已仔细核对所有标签(View All ROIs)
- 已使用实时预览完成训练和测试
- 已识别失败模式并添加针对性数据
- 已完成 2-4 轮 标注 → 训练 → 测试 迭代
- 结果符合预期
模型已训练好且表现良好?请前往 第 5 步:设置输出。