KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
Schritt 4: KI-Modell trainieren
Ihre Regions of Interest (ROIs) sind festgelegt. Jetzt ist es an der Zeit, der KI beizubringen, wie "gut" und "schlecht" aussehen.
Die drei Grundregeln des Trainings
Bevor Sie etwas anderes tun, verinnerlichen Sie diese drei Regeln. Sie gelten unabhängig davon, ob Sie einen Classifier oder einen Segmenter trainieren, mit 5 Bildern oder mit 500.
Regel 1: Labeln Sie nur anhand des Bildes
Schauen Sie sich niemals das physische Teil an (oder legen Sie es unter ein Mikroskop), um zu entscheiden, ob es gut oder schlecht ist. Wenn Sie den Fehler im Kamerabild nicht sehen können, kann die KI ihn auch nicht erlernen.
Die KI ist keine Zauberei. Sie kann nur mit dem arbeiten, was die Kamera sieht. Wenn Sie ein Teil als "defekt" labeln, weil Sie beim Anfassen oder unter der Lupe etwas bemerkt haben, das Kamerabild aber in Ordnung aussieht, bringen Sie der KI bei, etwas zu sehen, das gar nicht da ist.
Wenn Sie es nicht allein anhand des Bildes labeln können, gehen Sie zurück zum Install-Schritt und korrigieren Sie den physischen Aufbau: besseres Objektiv, bessere Beleuchtung, näher montieren, anderer Winkel.
Regel 2: Überprüfen Sie Ihre Labels doppelt und dreifach
Fehlbeschriftungen passieren jedem; auch erfahrene Ingenieure machen sie. Aber ein einziges falsches Label in einem kleinen Datensatz kann Ihre Ergebnisse zunichtemachen.
Bei 5 Trainingsbildern beschädigt eine Fehlbeschriftung 20 % Ihrer Trainingsdaten. Das ist katastrophal.
Vor jedem Trainingslauf: Klicken Sie auf View All ROIs und überprüfen Sie jede einzelne Annotation. Das ist die einfachste Korrektur mit der größten Wirkung.
Regel 3: Klein anfangen, schnell iterieren
Labeln Sie nicht 50 Bilder und starten Sie dann das Training. Erstellen Sie stattdessen eine enge Schleife: Labeln Sie 10-15 Bilder pro Klasse, trainieren (ca. 30 Sekunden), testen und versuchen, das Modell zu brechen, und fügen Sie dann gezielt Daten dort hinzu, wo es versagt. Wiederholen Sie diesen Zyklus 2-4 Mal.
Diese Schleife ist Ihr schnellster Weg zu einem guten Modell.
Schritt-für-Schritt-Trainings-Workflow
Die Weboberfläche des OV20i wurde in v2026.5 neu gestaltet. Überprüfen Sie Ihre Softwareversion in der oberen rechten Ecke der Kamera-UI und wählen Sie den passenden Tab. Ihre Auswahl gilt für jede Seite dieses Setup-Workflows.
- Older versions
- v2026.5 and newer
Folgen Sie den nummerierten Schritten unten, um Bilder aufzunehmen, zu labeln, zu trainieren und zu iterieren.
1. Erste Trainingsbilder aufnehmen
Bei aktivem Rezept und laufenden (oder manuell platzierten) Teilen nehmen Sie Bilder auf. Sie benötigen mindestens 10-15 Bilder pro Klasse, um zu starten.
Für eine einfache Pass/Fail-Inspektion:
- 10-15 Bilder von guten Teilen
- 10-15 Bilder von defekten Teilen
2. Klassen definieren
Wählen Sie den Modelltyp, den Sie trainieren, und lesen Sie dann die passenden Anweisungen. Der Umschalter unten bleibt zwischen Schritt 2 und Schritt 3 synchronisiert, und Ihre Auswahl wird in der URL gespeichert, sodass sie ein Neuladen oder Teilen übersteht.
- Classifier
- Segmenter
Fügen Sie in der Labeling-Oberfläche die Klassen hinzu, die jeder Inspektionstyp benötigt. Häufige Classifier-Klassensätze:
- Pass / Fail
- Present / Absent
- Good / Scratched / Cracked
Halten Sie es zunächst einfach. Sie können später jederzeit Klassen hinzufügen.
Fügen Sie in der Labeling-Oberfläche Klassen für die Fehler (oder Merkmale) hinzu, die die KI maskieren soll. Häufige Segmenter-Klassensätze:
- Defect / Background
- Scratch / Crack / Stain
- Foreground / Background
Halten Sie die Klassenliste zunächst kurz. Jede Klasse benötigt eine eigene Pinselfarbe und eigene gelabelte Beispiele, sodass das Hinzufügen weiterer Klassen zu Beginn Ihren Labeling-Aufwand vervielfacht.
3. Bilder beschriften
- Classifier
- Segmenter
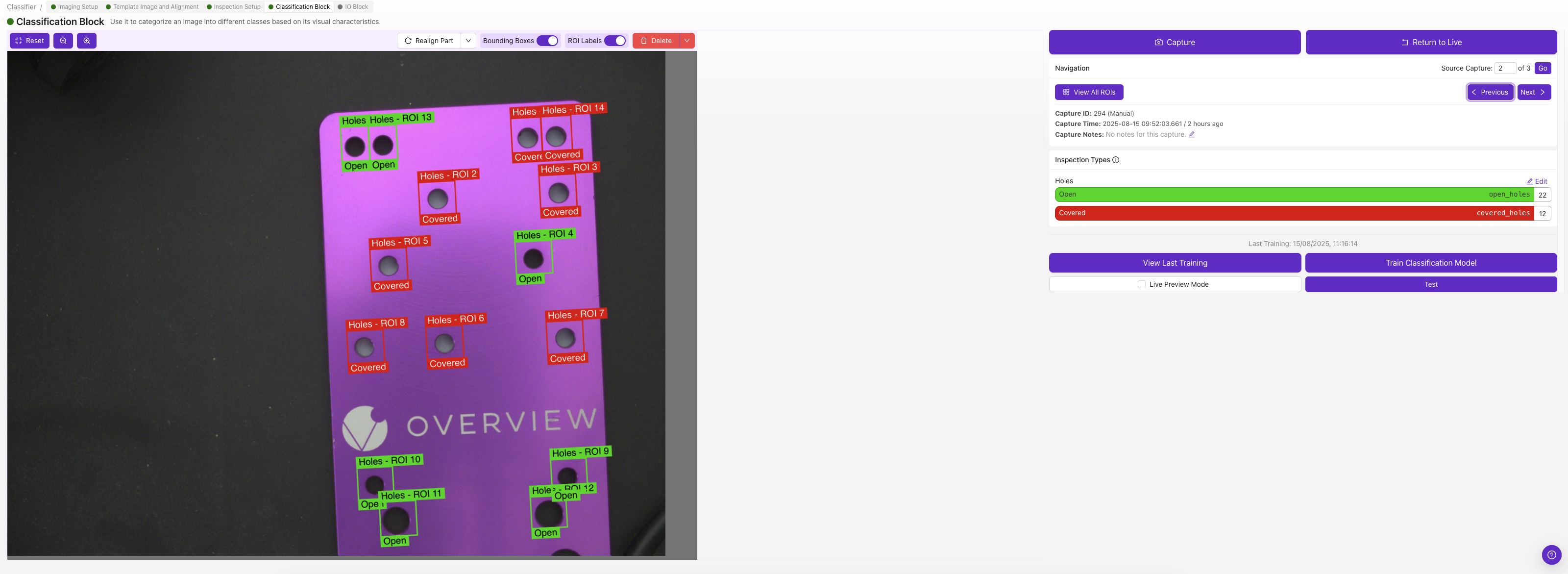
Jede ROI erhält ihre eigene Klassifizierungsklasse. Wählen Sie die Klasse, die diese ROI in diesem Bild beschreibt (z. B. "pass" oder "fail").
Wenn Sie unsicher sind, ob Sie Klassifizierung oder Segmentierung verwenden sollen, beginnen Sie mit der Klassifizierung. Sie ist deutlich schneller zu beschriften und für die meisten Pass/Fail-Szenarien geeignet. Eine Orientierungshilfe finden Sie unter Classifier vs. Segmenter.
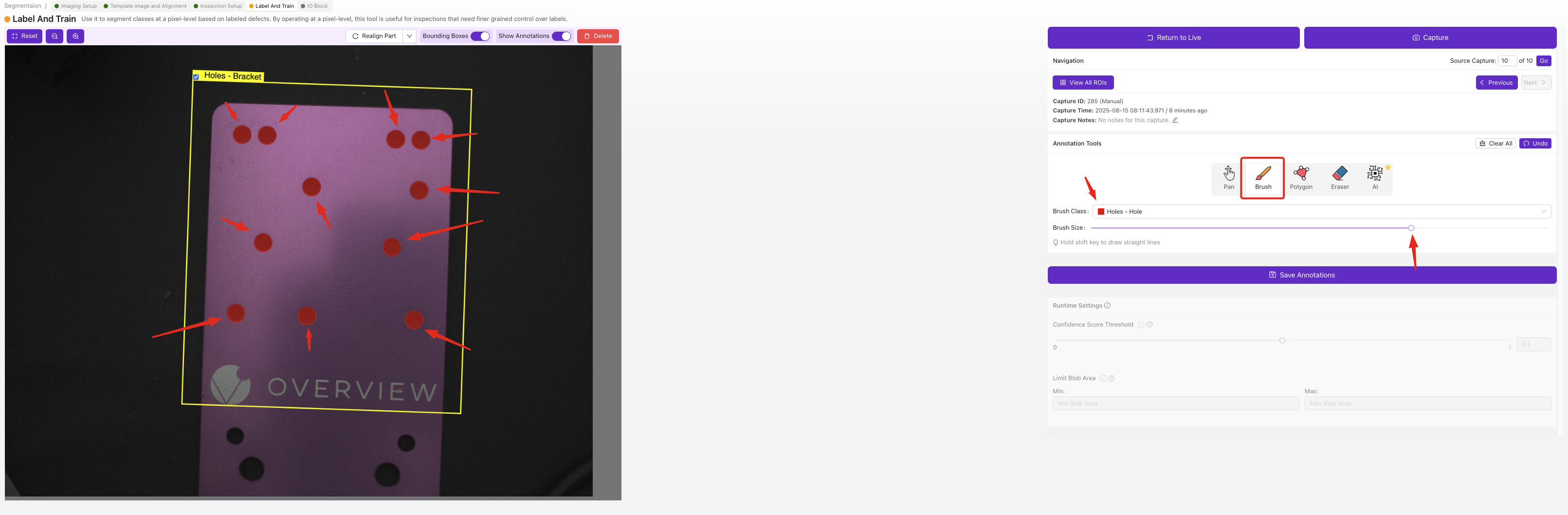
Verwenden Sie für jede ROI in jedem Bild das Pinselwerkzeug, um die fehlerhaften Bereiche pixelgenau einzufärben. Die eingefärbten Bereiche sind das, was die KI zu erkennen lernt – alles, was Sie nicht einfärben, wird als Hintergrund behandelt.
Segmenter-Beschriftungen erfordern Pinselarbeit auf Pixelebene, was langsamer ist als die Dropdown-Auswahl beim Classifier, liefert Ihnen aber präzise Fehlerkarten mit Position und Form. Beginnen Sie mit einer kleinen Auswahl klar definierter Fehler und fügen Sie erst weitere Klassen hinzu, wenn Ihr erstes Modell funktioniert.
4. Modell trainieren
- Classifier
- Segmenter
Klicken Sie auf Train. Der Classifier bietet zwei Trainingsmodi:
- Fast mode, etwa 30 Sekunden bis eine Minute. Ideal für schnelle Iterationen während der Einrichtung, zur Plausibilitätsprüfung Ihrer Beschriftungen und für einfache/gut trennbare Teile. Die Genauigkeit ist geringer als im Production mode, aber Sie sehen das Signal schnell.
- Production mode, dauert länger, erzeugt aber ein deutlich genaueres Modell. Verwenden Sie vor dem Einsatz in der Linie immer den Production mode. Für anspruchsvolle Teile, schwer zu unterscheidende Fehler oder alles, worauf Sie sich in der Produktion verlassen wollen, ist der Production mode die richtige Wahl.
Ein bewährter Rhythmus: Iterieren Sie im Fast mode, während Sie Beschriftungen bereinigen und Daten hinzufügen, führen Sie dann Production aus, sobald das Ergebnis gut aussieht, und erneut vor dem Deployment.
Klicken Sie auf Train. Die Segmentierung verfügt nur über einen Trainingsmodus, Production, da Masken auf Pixelebene den gründlicheren Trainingsdurchlauf benötigen, um zuverlässig zu sein. Die Trainingszeit skaliert mit der Anzahl der Bilder und der Anzahl der von Ihnen beschrifteten ROIs, sodass eine kleine Startmenge (10–15 Bilder pro Klasse) in wenigen Minuten trainiert wird; größere Datensätze dauern länger.
Hier gibt es keine "schnelle" Plausibilitätsprüfung, stellen Sie also sicher, dass Ihre Beschriftungen sauber sind, bevor Sie trainieren (verwenden Sie View All ROIs, um jede Maske zu überprüfen).
Ein Segmenter lernt nur die Fehler, die Sie tatsächlich einfärben und ihm zeigen. Je mehr Beispiele Sie einbeziehen – die verschiedenen Größen, Formen und Positionen abdecken, die ein Fehler annehmen kann – desto zuverlässiger wird er sie in der Produktion maskieren.
Zu wenige Fehlerproben? Verwenden Sie das Defect Creator Studio, um mehr Trainingsbilder desselben Fehlers in verschiedenen Größen, Formen und Positionen zu generieren, damit Sie nicht darauf warten müssen, dass sie in der Linie auftreten.
5. Test mit Live Preview
Klicken Sie auf Live Preview Mode und führen Sie Teile durch. Beobachten Sie die Ergebnisse:
- Werden einfache Fälle korrekt erkannt?
- Wo gibt es Schwierigkeiten?
- Was sind die Grenzfälle?
Versuchen Sie, das Modell zu überfordern. Finden Sie die Fälle, in denen es versagt. Diese Fehler sind Ihre Roadmap für Verbesserungen.
- Classifier
- Segmenter

Das Test-Panel zeigt die vorhergesagte Klasse und den Confidence Score für jede ROI. Führen Sie einige Aufnahmen durch und achten Sie auf Verdikte mit geringer Confidence (oft unter 70 %); das sind Ihre Grenzfälle und die Teile, die als Nächstes gelabelt werden sollten.
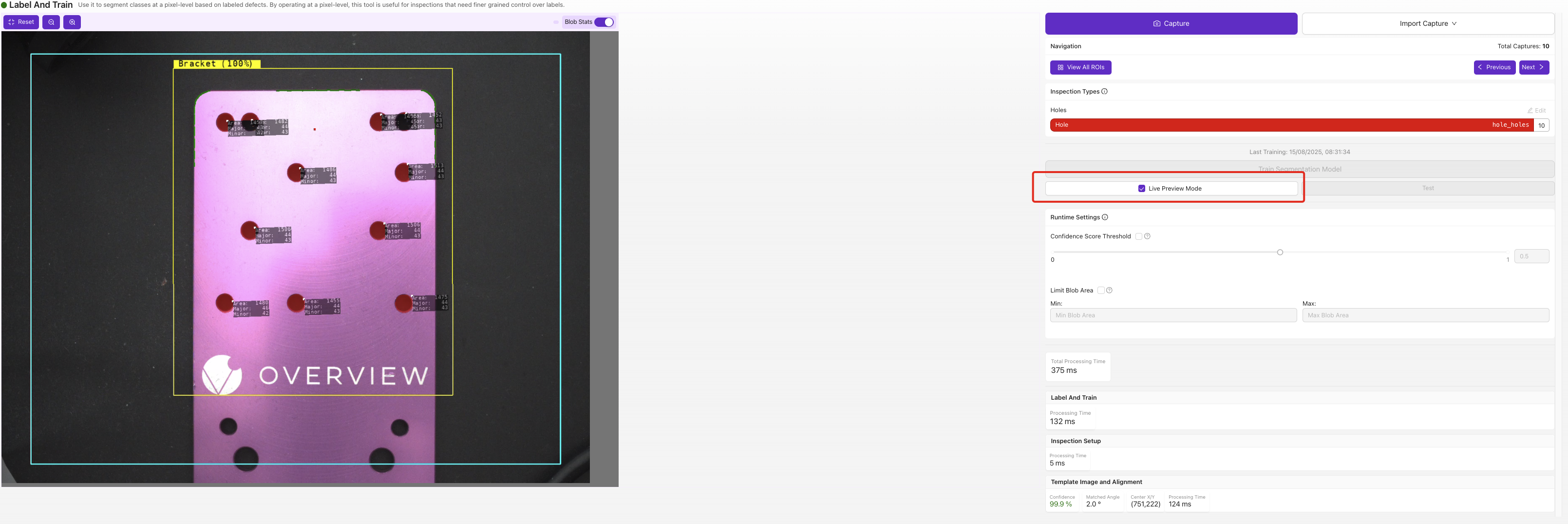
Live Preview legt die vorhergesagte Fehlermaske direkt auf das Bild. Achten Sie auf Masken, die zu klein oder zu groß sind oder dort erscheinen, wo kein tatsächlicher Fehler vorliegt – das sind die Fehlermodi, die Sie mit der nächsten Runde gelabelter Daten gezielt angehen.
6. Gezielte Daten hinzufügen
Fügen Sie keine zufälligen neuen Bilder hinzu. Fügen Sie Bilder hinzu, die gezielt die gefundenen Fehlermodi adressieren:
- Verwechselt das Modell Kratzer mit Reflexionen, fügen Sie mehr Beispiele von beiden hinzu
- Übersieht es kleine Defekte, fügen Sie mehr Bilder kleiner Defekte hinzu
- Versagt es bei Teilen in den Ecken, fügen Sie mehr Beispiele aus den Ecken hinzu
7. Neutrainieren und erneut testen
Wiederholen Sie die Schritte 4–6 zwei- bis viermal. Jede Iteration sollte die Genauigkeit verbessern. Eine ausführlichere Anleitung, einschließlich der Hinzufügung neuer Bilder zu einem bestehenden Modell ohne Verlust des vorherigen Trainings, finden Sie unter Daten hinzufügen & Neutrainieren.
Das Modell, das Sie beim Erstellen des Recipes ausgewählt haben, erhält einen eigenen Schritt: Step 4: Classification für einen Classifier oder Step 4: Segmentation für einen Segmenter. Ihre Klassen wurden bereits im Schritt Region of Interest (ROIs) definiert, daher werden in diesem Schritt Bilder aufgenommen, gelabelt, trainiert und getestet. Beide teilen sich oben dieselben sechs Unter-Tabs. Wählen Sie Ihren Modelltyp:
- Classifier
- Segmenter
About Classification
Ein kurzes Playbook, um ein präzises Modell zu erhalten. Es beschreibt den Iterate-to-Accuracy-Loop (schnell trainieren, Schwachstellen in der Live Preview finden, gezielte Daten hinzufügen, neutrainieren und anschließend zum hochpräzisen Production-Modell hochstufen) sowie die wichtigsten Best Practices pro Klasse: Klassen ausbalancieren, ein hohes Signal-Rausch-Verhältnis beibehalten und die Extremfälle dessen abdecken, was Sie erkennen möchten. Eine ausführlichere Erklärung, wie ein Classifier jede ROI in ein Verdikt umwandelt, finden Sie unter Understanding the Classifier.
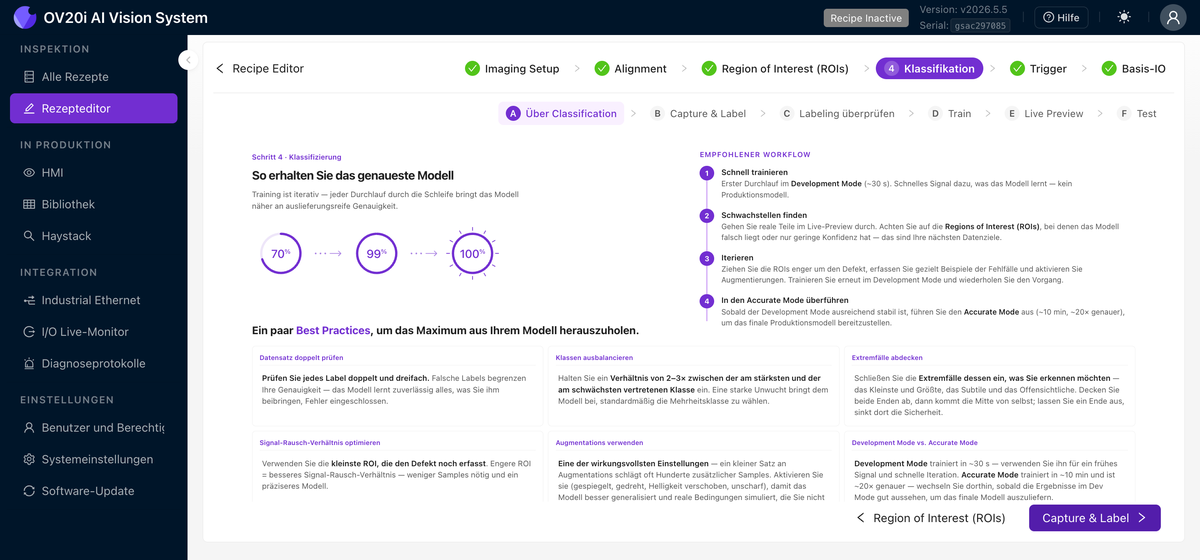
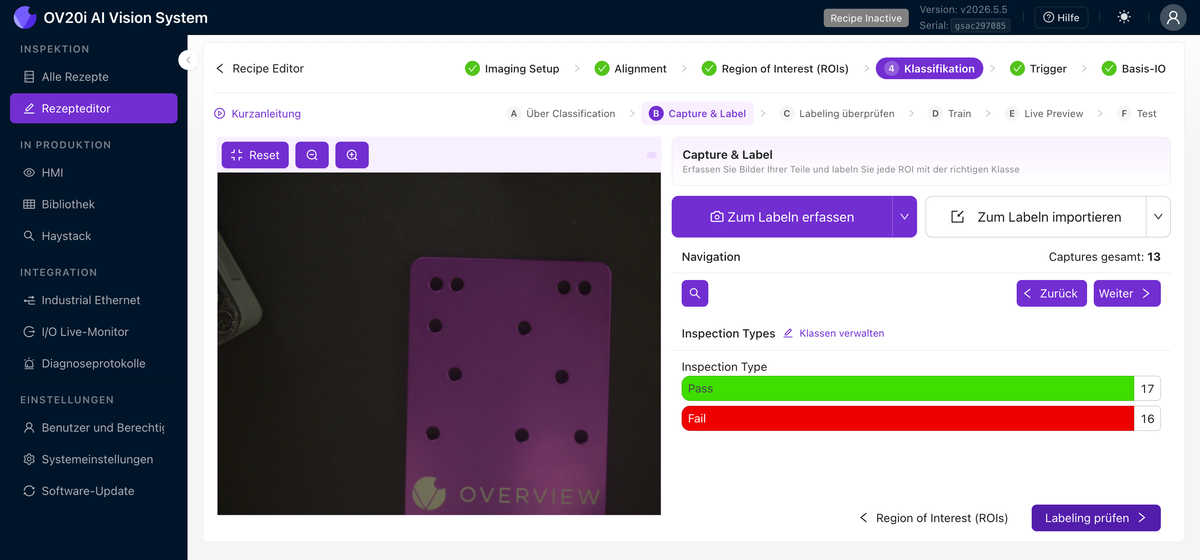
Capture & Label
Erstellen Sie hier Ihren Datensatz. Verwenden Sie Capture to Label, um Frames von der Live-Kamera zu erfassen, oder Import to Label, um gespeicherte Bilder zu importieren. Die Navigation-Steuerelemente (Previous, Next, Search by Capture ID und die Gesamtzahl der Captures) ermöglichen die Navigation durch den Datensatz. Weisen Sie für jede Aufnahme jede ROI einer ihrer Klassen zu. Die Zählung pro Klasse (z. B. Pass 17 / Fail 16) zeigt auf einen Blick, wie ausgewogen Ihr Datensatz ist, und Manage classes führt zu der Stelle, an der die Klassen definiert werden.
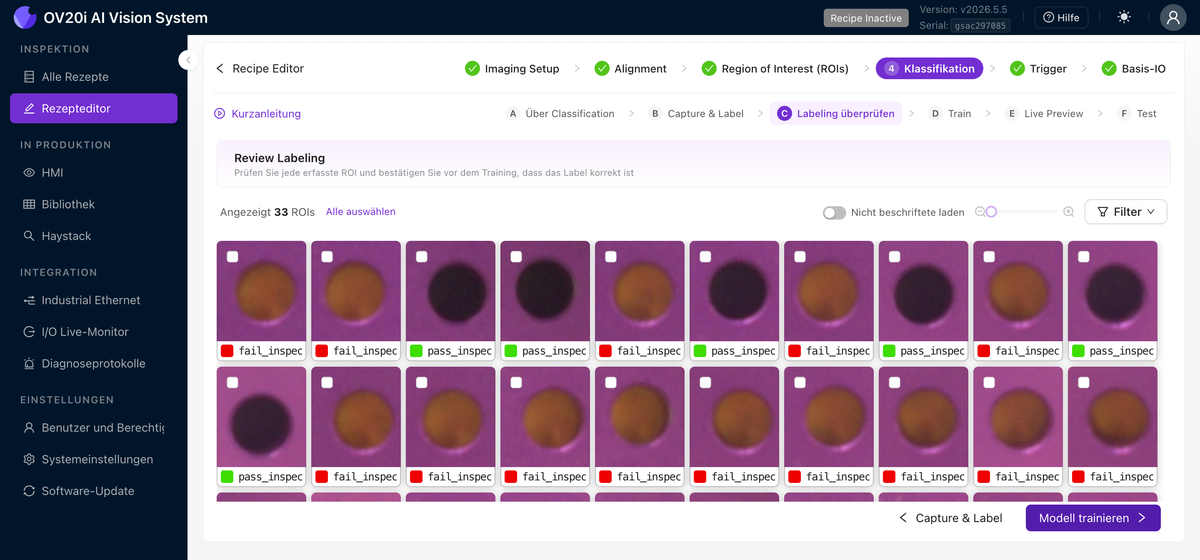
Review Labeling
Zeigt jeden gelabelten ROI-Ausschnitt in einem einzigen Raster, jeweils mit seiner Klasse markiert, sodass Sie schnell nach Fehlbeschriftungen suchen können. Verwenden Sie Filters und Select all, um sie in großen Mengen zu bearbeiten. Hier ist die Gewohnheit "jedes Label vor dem Training überprüfen" in v2026.5 verankert.
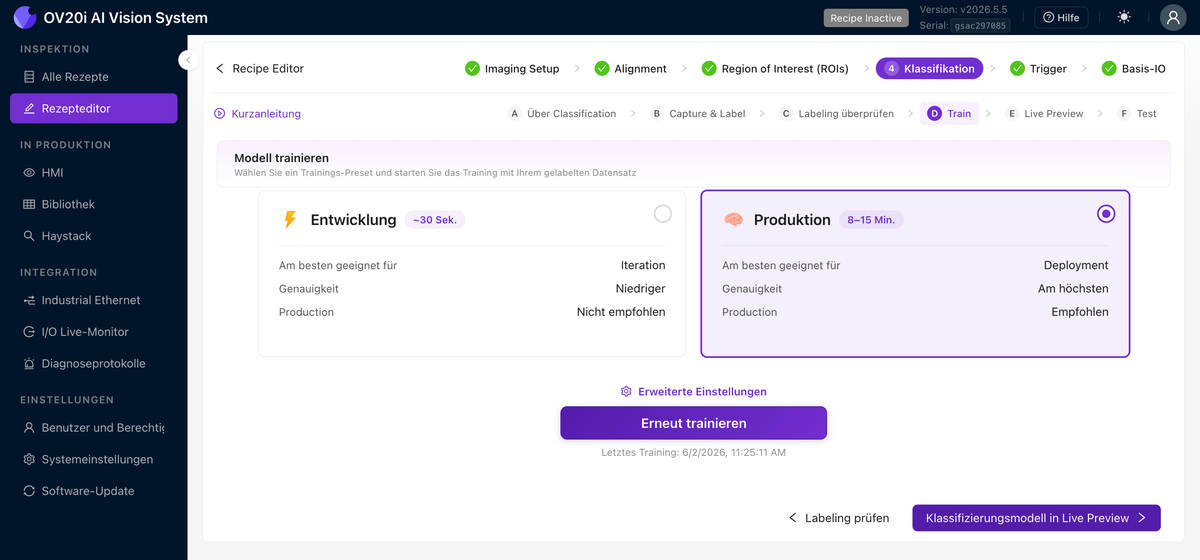
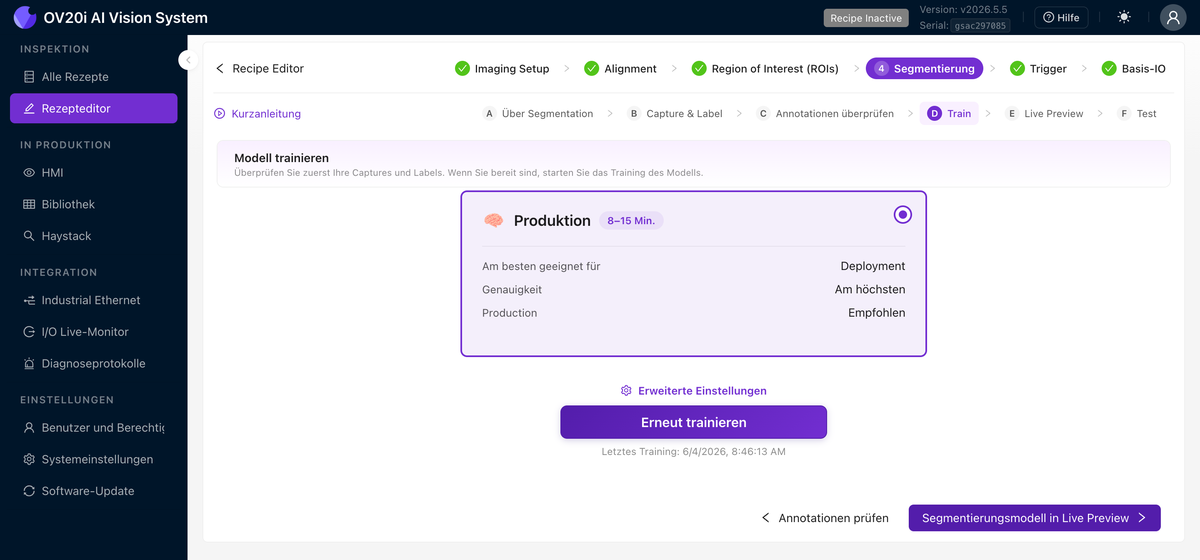
Train
Wählen Sie ein Preset und starten Sie das Training mit Ihrem gelabelten Datensatz:
- Development läuft in etwa 30 Sekunden. Geringere Genauigkeit, aber es ist die schnelle Schleife, die Sie beim Bereinigen von Labels und Hinzufügen von Daten verwenden.
- Production dauert 8 bis 15 Minuten. Es ist das hochpräzise Modell, das Sie an der Linie bereitstellen.
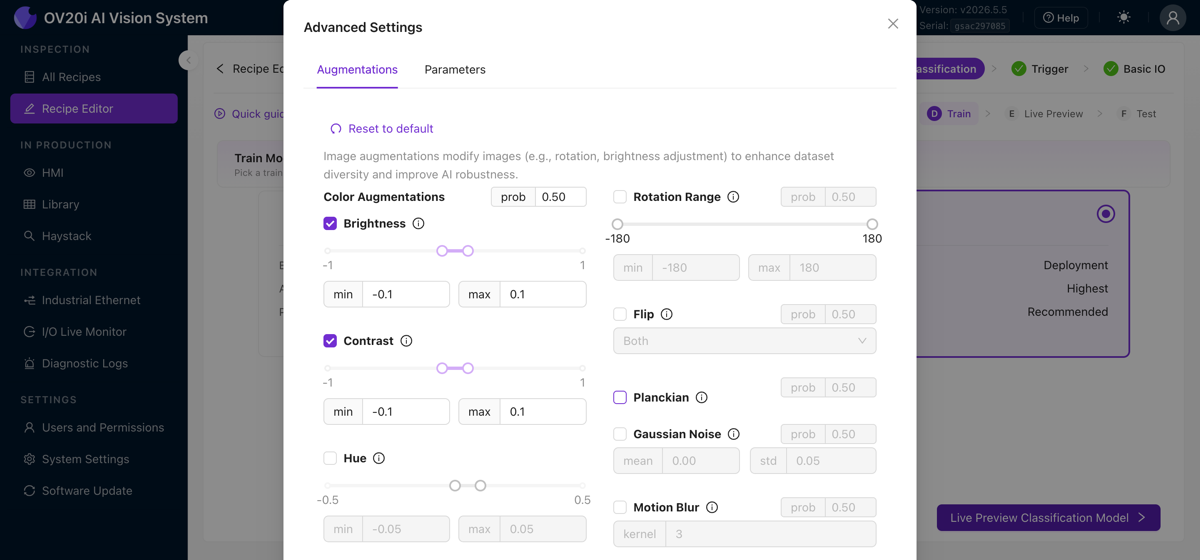
Advanced Settings öffnet Augmentierungen (Helligkeit, Kontrast, Farbton, Rotation, Spiegelung, Planckian, Gaußsches Rauschen, Bewegungsunschärfe) und Trainingsparameter. Siehe Augmentierungen unten für die jeweiligen Anwendungsfälle. Retrain führt das Training erneut aus, nachdem Sie Daten hinzugefügt haben, und die letzte Trainingszeit wird daneben angezeigt.
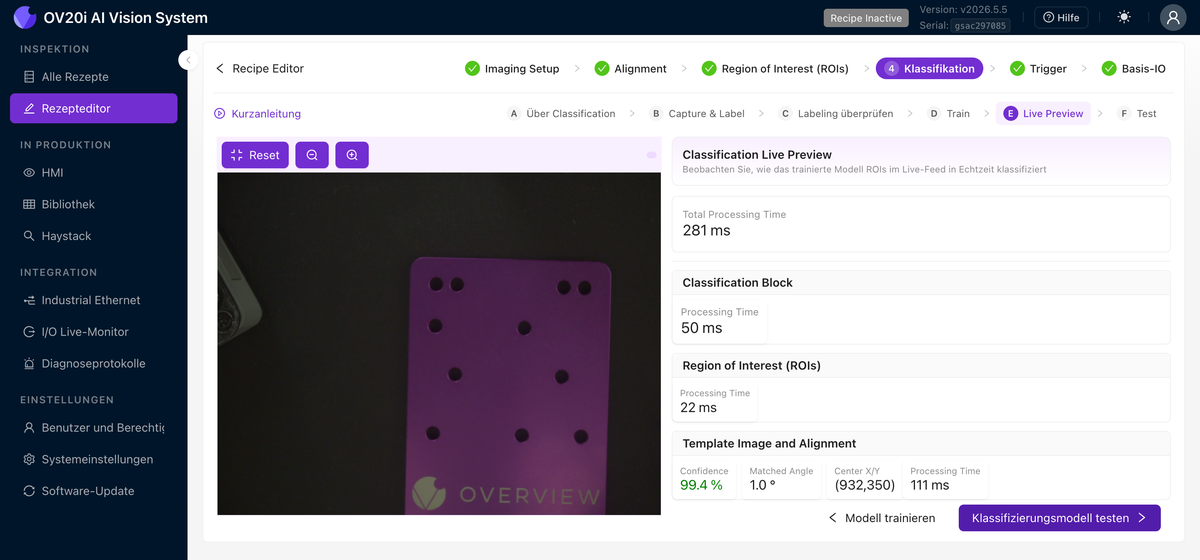
Live Preview
Führt das trainierte Modell in Echtzeit auf dem Live-Feed aus. Es zeigt die vorhergesagte Klasse jeder ROI zusammen mit der Ausrichtungskonfidenz und dem übereinstimmenden Winkel und schlüsselt die Verarbeitungszeit pro Block auf (Klassifizierung, ROIs, Template und Ausrichtung), sodass Sie sehen können, wo die Zykluszeit hingeht. Lassen Sie Teile durchlaufen und suchen Sie nach Urteilen mit geringer Konfidenz; diese Grenzfälle sind die Teile, die als Nächstes gelabelt werden sollten.
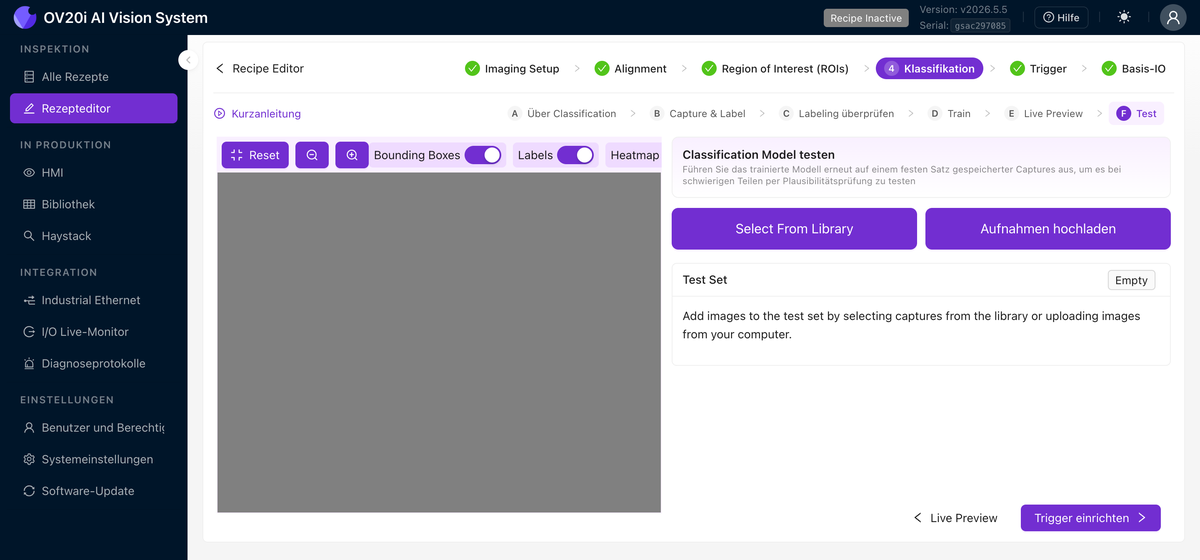
Test
Führt das trainierte Modell erneut auf einer festen Menge gespeicherter Aufnahmen aus (Select From Library oder Upload Captures), sodass Sie es auf schwierigen Teilen plausibilisieren können, ohne darauf warten zu müssen, dass sie auf der Linie ankommen. Schalten Sie Bounding Boxes, Labels und Heatmap um, um zu sehen, wie das Modell entscheidet.
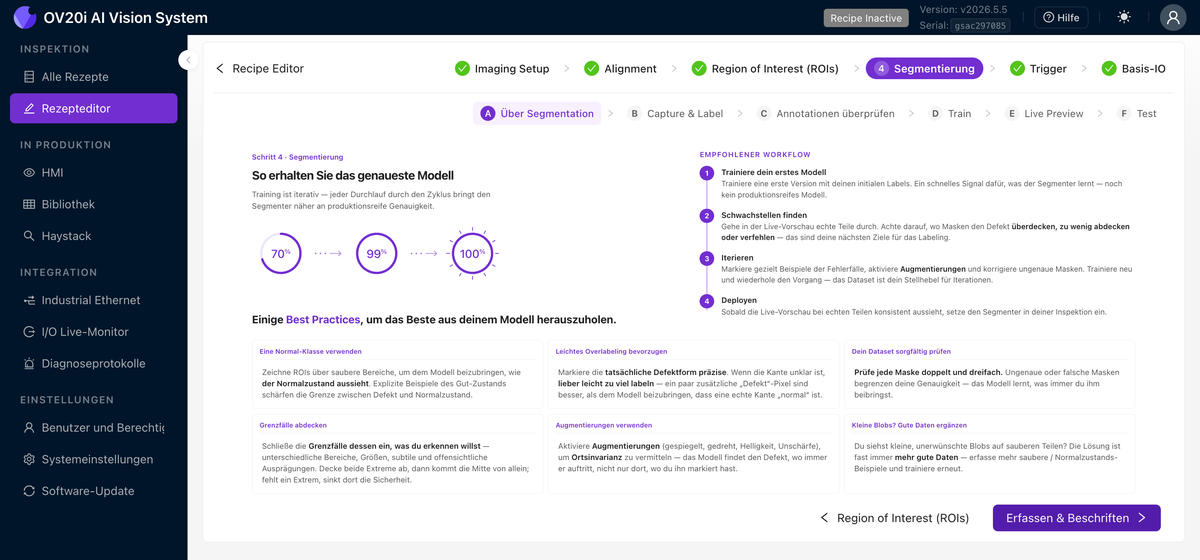
About Segmentation
Dasselbe Iterate-to-Accuracy-Vorgehen wie beim Classifier, mit maskenspezifischen Best Practices: Malen Sie saubere Masken, bevorzugen Sie eine leichte Überlappung am Rand eines Defekts gegenüber einer Lücke, und decken Sie den gesamten Bereich an Defektgrößen und -texturen ab, den Sie erwarten. Eine ausführlichere Erklärung, wie ein Segmenter Pixelmasken, Zählungen und Messungen erzeugt, finden Sie unter Understanding the Segmenter.
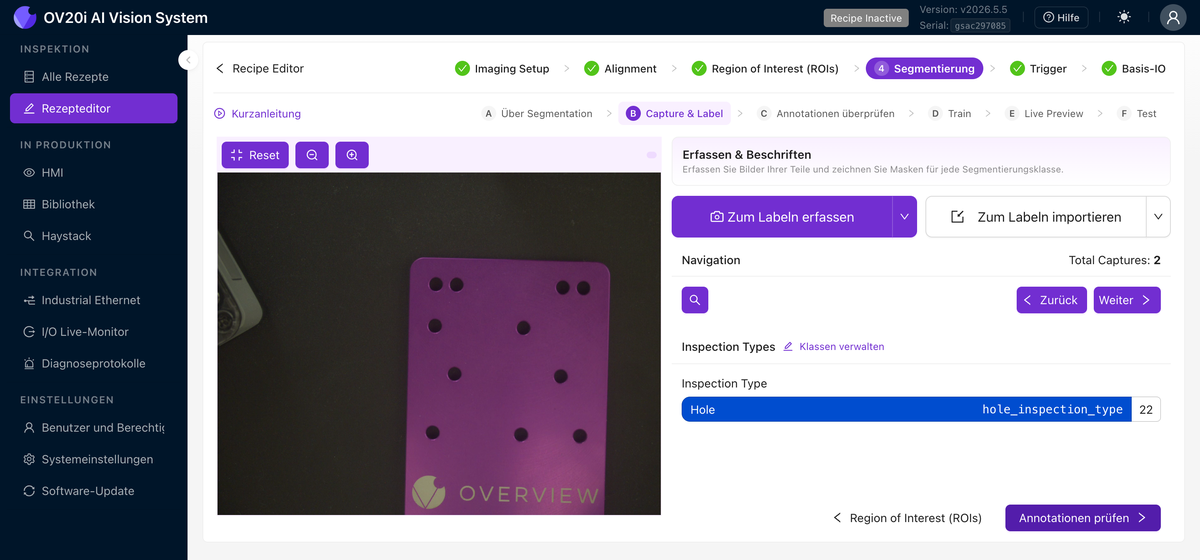
Capture & Label
Sie erstellen den Datensatz auf dieselbe Weise, aber anstatt eine Klasse pro ROI auszuwählen, malen Sie eine Maske. Verwenden Sie Capture to Label oder Import to Label und gehen Sie dann die Aufnahmen mit den Navigation-Steuerelementen durch. Wählen Sie die Klasse aus, die Sie labeln (jede hat ihre eigene Pinselfarbe), und malen Sie dann über den Defekt auf dem Bild. Die gemalten Pixel sind das, was das Modell lernt; alles, was Sie ungemalt lassen, ist Hintergrund.
Die Annotations-Toolbar bietet Ihnen ein Werkzeug für jede Situation:
| Werkzeug | Was es tut |
|---|---|
| Pan | Bewegen Sie sich auf dem Bild, ohne zu malen (verwenden Sie es im Zoom-Modus) |
| Brush | Freihandmalen der Maske; passen Sie die Pinselgröße für feine oder breite Striche an |
| Polygon | Klicken Sie Punkte, um eine Region mit geraden Kanten einzuschließen, nützlich für Defekte mit harten Kanten |
| Eraser | Entfernen Sie Farbe von einer bereits gezeichneten Maske |
| AI | KI-unterstütztes Labeling: Klicken Sie auf einen Defekt, und das Werkzeug schlägt eine Maske vor, die Sie akzeptieren oder verfeinern können |
Einige weitere Steuerelemente beschleunigen die Arbeit:
- Predict führt Ihr trainiertes Modell auf der Aufnahme aus und fügt die vorhergesagte Maske als Startpunkt ein, sodass Sie diese bereinigen, anstatt von Grund auf zu malen. Dies funktioniert nur, wenn Sie das Modell mindestens einmal trainiert haben.
- Undo macht den letzten Strich rückgängig.
- Clear All löscht die Maske auf der aktuellen Aufnahme.
- Manage classes springt zur Klassenliste.
Review Annotations
Zeigt jede erfasste ROI mit ihrer eingezeichneten Maske an, sodass Sie die Abdeckung vor dem Training überprüfen können. Ziehen Sie den Schieberegler Mask opacity, um die Maske mit dem Bild zu vergleichen, und verwenden Sie Filters, um die Auswahl einzugrenzen. Dies ist die Segmenter-Version der Gewohnheit „jedes Label vor dem Training prüfen".
Train
Die Segmentierung hat eine einzige Voreinstellung, Production (ca. 8 bis 15 Minuten). Es gibt keine schnelle Option, da pixelgenaue Masken den vollständigen Trainingsdurchlauf benötigen, um zuverlässig zu sein. Advanced Settings zeigt Augmentationen und Parameter an, und Retrain läuft erneut, nachdem Sie Daten hinzugefügt haben.
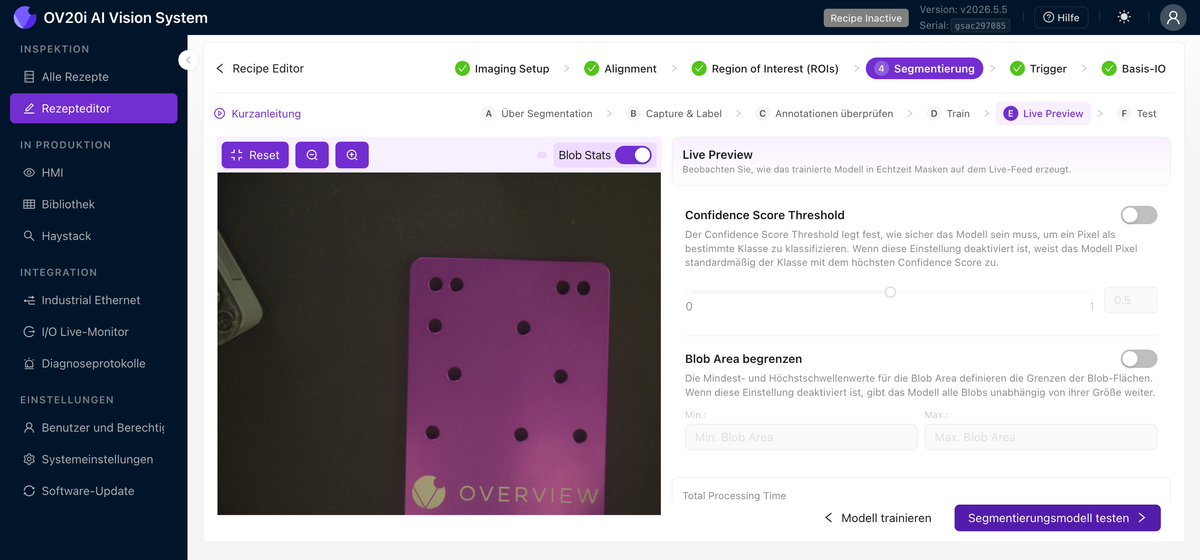
Live Preview
Führt das trainierte Modell auf dem Live-Feed aus und überlagert die vorhergesagten Defektmasken in Echtzeit. Aktivieren Sie Blob Stats für Anzahl und Flächen pro Blob, legen Sie den Confidence Score Threshold fest (wie sicher das Modell sein muss, um ein Pixel einer Klasse zuzuordnen), und verwenden Sie Limit Blob Area, um Blobs unterhalb oder oberhalb einer festgelegten Größe zu ignorieren. Achten Sie auf Masken, die zu klein oder zu groß sind oder dort landen, wo kein echter Defekt vorliegt.
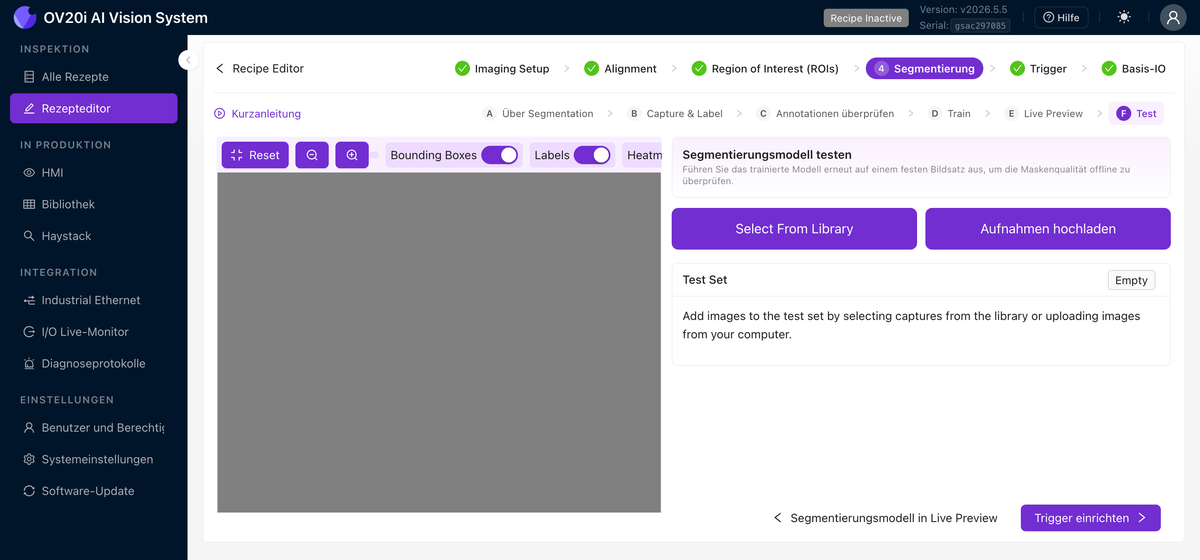
Test
Führen Sie das trainierte Modell erneut gegen einen festen Satz gespeicherter Aufnahmen aus (Select From Library oder Upload Captures), um die Maskenqualität offline zu überprüfen. Schalten Sie Bounding Boxes, Labels und Heatmap um, um zu sehen, wie das Modell entscheidet.
Ein Segmenter lernt nur die Defekte, die Sie tatsächlich einzeichnen und ihm zeigen. Fügen Sie so viele Beispiele wie möglich hinzu, die die verschiedenen Größen, Formen und Positionen abdecken, die ein Defekt annehmen kann. Wenn Ihnen Samples fehlen, erzeugen Sie weitere mit dem Defect Creator Studio.
Augmentations: der KI beibringen, mit Variation umzugehen
Augmentationen verändern Ihre Trainingsbilder während des Trainingsprozesses zufällig, indem sie die Helligkeit anpassen, Rotation hinzufügen, den Kontrast verändern usw. Jedes Bild wird der KI hunderte Male mit leicht unterschiedlichen Augmentationen zugeführt, das Label bleibt jedoch dasselbe. So machen Sie ein Modell robust gegenüber realen Bedingungen, ohne ein Beispiel für jede mögliche Variation erfassen zu müssen.
Was standardmäßig aktiviert werden sollte
Eine kleine Menge brightness-Variation lohnt sich fast immer – selbst die kontrollierteste Fabrik hat Deckenbeleuchtung, die flackert, Schatten, die sich im Laufe der Schicht verschieben, und geringfügige LED-Drift im Laufe der Zeit. Helligkeits-Augmentation macht das Modell quasi kostenlos resilient gegenüber all dem.
Rotation: nützlich, aber achten Sie auf die ROI-Form
Rotations-Augmentation ist großartig, wenn Ihre Teile tatsächlich in unterschiedlichen Winkeln eintreffen können (lose Schrauben auf einem Förderband, von Hand platzierte Teile, alles, was nicht in einer Vorrichtung gehalten wird). Aber sie interagiert mit der ROI-Form:
- Quadratische ROI: Rotations-Augmentation funktioniert sauber, das gedrehte Bild passt weiterhin in den ROI-Rahmen.
- Nicht-quadratische ROI bei einem Classifier: Rotation kann das Bild beschneiden. Wenn eine hohe, schmale ROI um 45° gedreht wird, fallen die Ecken des gedrehten Inhalts aus dem Rahmen heraus und das Modell trainiert auf einem unvollständigen Bild. Wenn sich Ihr Teil drehen kann, machen Sie die ROI entweder quadratisch oder verlassen Sie sich auf den Aligner, um die Rotation vorgelagert zu behandeln, sodass Sie hier keine Rotations-Augmentation benötigen.
- Segmenter: Das gleiche Beschneidungsproblem gilt, aber Segmentierung ist weniger empfindlich, da sie aus Pixelmasken und nicht aus der gesamten ROI-Form lernt.
Datenvielfalt ist wichtig
Ihre Trainingsdaten sollten die gesamte Bandbreite dessen abbilden, was die KI in der Produktion sehen wird:
- Verschiedene Tageszeiten (wenn die Beleuchtung variiert)
- Verschiedene Teilechargen (Oberflächenbeschaffenheit kann leicht variieren)
- Teile in unterschiedlichen Positionen innerhalb des Bildausschnitts
- Sowohl einfache als auch schwierige Fälle
Konzentrieren Sie sich auf die schwierigsten Fälle. Wenn Ihre Trainingsdaten die 10 am schwierigsten zu klassifizierenden Teile enthalten, sind die 90 % der einfachen Teile für die KI trivial.
Wie viele Daten Sie tatsächlich benötigen
Sie benötigen weit weniger Daten als bei den meisten KI-Systemen. Die meisten Inspektionen funktionieren bereits mit nur 5 bis 10 Bildern pro Klasse hervorragend. Für ein schwierigeres Problem mit mehreren Fehlern reichen in der Regel 15 bis 20 Bilder pro Klasse aus. Beginnen Sie klein, finden Sie in der Live Preview heraus, wo das Modell Schwierigkeiten hat, und ergänzen Sie nur dort gezielt Bilder, wo es nötig ist, anstatt im Voraus Hunderte zu sammeln.
Beschleunigung mit synthetischen Daten: Defect Studio
Was, wenn Sie für einen Fehler trainieren müssen, den Sie selten sehen? Eine fehlende Schraube, die Sie absichtlich entfernen müssten, einen Kratzer, den Sie erzeugen müssten, einen Riss, der einmal pro tausend Teile auftritt? Monatelang zu warten, um genügend Beispiele zu sammeln, ist nicht praktikabel.
Das OV Auto-Defect Creator Studio auf tools.overview.ai löst dieses Problem. Es erzeugt fotorealistische synthetische Fehlerbilder – bis zu 10.000-mal schneller, als auf das Auftreten echter Fehler in der Produktionslinie zu warten.
So funktioniert es: 5 einfache Schritte
- Laden Sie ein gutes Bild Ihres Teils hoch
- Markieren Sie den Bereich, in dem der Fehler erscheinen soll
- Beschreiben Sie den Fehler in einfachem Englisch (z. B. „deep scratch across the surface" oder „missing solder joint")
- Generieren Sie die Fehlervarianten (die KI erstellt fotorealistische Ergebnisse)
- Exportieren Sie die synthetischen Bilder direkt in Ihren Trainingsdatensatz
Warum synthetische Daten funktionieren
Die generierten Bilder sind nicht einfach „aufgeklebte" Artefakte. Es handelt sich um fotorealistische Varianten, die zu Ihrer tatsächlichen Beleuchtung, Ihrem Kamerawinkel und Ihrer Teileoberfläche passen. Die KI versteht die Physik dahinter, wie Fehler unter Ihren spezifischen Bildgebungsbedingungen aussehen.
Anwendungsfälle:
- Seltene Fehler: Trainieren Sie für Fehlermodi, die Sie noch nie (oder selten) gesehen haben
- Neue Produkteinführungen: Erstellen Sie eine Inspektion, bevor das erste fehlerhafte Teil vom Band läuft
- Grenzfälle: Generieren Sie grenzwertige Beispiele, um die Entscheidungsgrenze der KI zu verbessern
- Daten-Augmentation: Ergänzen Sie kleine Datensätze mit synthetischer Vielfalt
Sehen Sie es in Aktion
Der beste Ansatz: Trainieren Sie zunächst mit Ihren ersten 3–5 echten Bildern, identifizieren Sie, wo die KI Schwierigkeiten hat, und nutzen Sie dann Defect Studio, um gezielt synthetische Beispiele für diese spezifischen Fehlermodi zu generieren. Echte Daten vermitteln die Grundlage; synthetische Daten füllen die Lücken.
Trainings-Checkliste
Bevor Sie fortfahren, bestätigen Sie:
- Erste Bilder aufgenommen, mindestens 10–15 pro Klasse
- Alle Labels doppelt überprüft (View All ROIs)
- Trainiert und mit Live Preview getestet
- Fehlerfälle identifiziert und gezielte Daten hinzugefügt
- 2–4 Iterationen von Labeln → Trainieren → Testen abgeschlossen
- Ergebnisse entsprechen den Erwartungen
Modell trainiert und sieht gut aus? Weiter zu Schritt 5: Ausgänge einrichten.