DOCUMENTACIÓN CON IA
¿Qué desea saber?
Paso 4: Entrenar Su Modelo de AI
Sus regiones de interés (ROIs) están configuradas. Ahora es momento de enseñarle al AI cómo se ven las piezas "buenas" y "malas".
Las tres reglas cardinales del entrenamiento
Antes que nada, internalice estas tres reglas. Aplican ya sea que esté entrenando un clasificador o un segmentador, con 5 imágenes o 500.
Regla 1: Etiquete únicamente desde la imagen
Nunca observe la pieza física (ni la coloque bajo un microscopio) para decidir si es buena o mala. Si no puede ver el defecto en la imagen de la cámara, el AI no puede aprenderlo.
El AI no es magia. Solo puede trabajar con lo que la cámara ve. Si etiqueta una pieza como "defectuosa" basándose en algo que notó al tocarla o al hacer zoom bajo una lupa, pero la imagen de la cámara se ve bien, está enseñando al AI a ver algo que no está ahí.
Si no puede etiquetarla únicamente desde la imagen, regrese al paso de Instalación y corrija la configuración física: mejor lente, mejor iluminación, montaje más cercano, ángulo diferente.
Regla 2: Revise sus etiquetas dos y tres veces
Los errores de etiquetado le pasan a todos; los ingenieros experimentados también los cometen. Pero una mala etiqueta en un conjunto de datos pequeño puede destruir sus resultados.
Con 5 imágenes de entrenamiento, un error de etiquetado corrompe el 20% de sus datos de entrenamiento. Eso es catastrófico.
Antes de cada ejecución de entrenamiento: Haga clic en Ver Todas las ROIs y verifique cada una de las anotaciones. Esto es lo más fácil de corregir y lo de mayor impacto.
Regla 3: Comience en pequeño, itere rápido
No etiquete 50 imágenes y presione entrenar. En cambio, cree un ciclo ajustado: Etiquete 10-15 imágenes por clase, entrene (aproximadamente 30 segundos), pruebe e intente romperlo, luego agregue datos específicos donde falle. Repita este ciclo de 2 a 4 veces.
Este ciclo es su camino más rápido hacia un buen modelo.
Flujo de trabajo de entrenamiento paso a paso
La interfaz web del OV20i fue rediseñada en v2026.5. Verifique la versión de su software en la esquina superior derecha de la IU de la cámara y elija la pestaña correspondiente. Su elección se mantendrá en cada página de este flujo de configuración.
- Versiones anteriores
- v2026.5 and newer
Siga los pasos numerados a continuación para capturar, etiquetar, entrenar e iterar.
1. Capture imágenes iniciales de entrenamiento
Con su receta activa y piezas en flujo (o colocadas manualmente), capture imágenes. Necesita un mínimo de 10-15 imágenes por clase para comenzar.
Para una inspección simple de aprobado/rechazado:
- 10-15 imágenes de piezas buenas
- 10-15 imágenes de piezas defectuosas
2. Defina sus clases
Elija el tipo de modelo que está entrenando, luego lea las instrucciones correspondientes. El selector de abajo se mantiene sincronizado entre el Paso 2 y el Paso 3, y su elección se preserva en la URL para que sobreviva a una actualización o al compartirla.
- Clasificador
- Segmentador
En la interfaz de etiquetado, agregue las clases que cada tipo de inspección necesite. Conjuntos de clases comunes del clasificador:
- Aprobar / Fallar
- Presente / Ausente
- Bueno / Rayado / Agrietado
Manténgalo simple al principio. Siempre puede agregar clases más adelante.
En la interfaz de etiquetado, agregue clases para los defectos (o características) que quiere que el AI enmascare. Conjuntos de clases comunes del segmentador:
- Defecto / Fondo
- Rayadura / Grieta / Mancha
- Primer plano / Fondo
Mantenga la lista de clases corta al principio. Cada clase necesita su propio color de pincel y sus propios ejemplos etiquetados, por lo que agregar más clases desde el inicio multiplica su trabajo de etiquetado.
3. Etiquetar las imágenes
- Classifier
- Segmenter
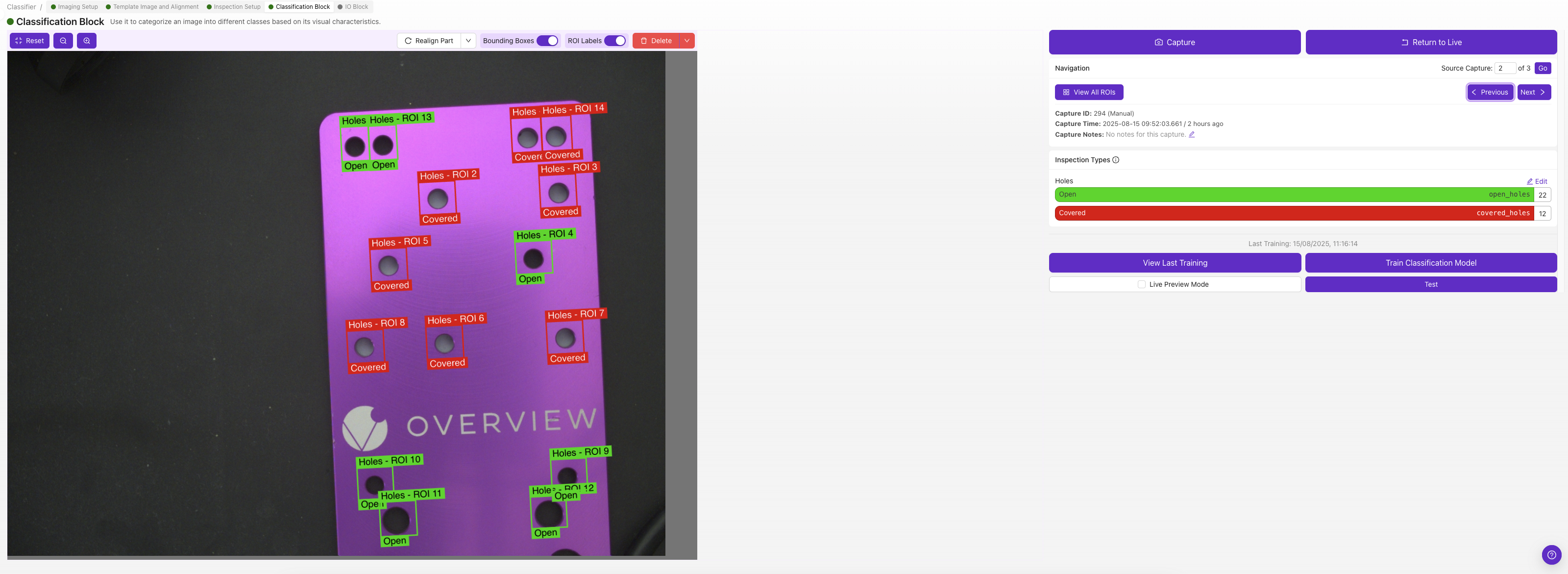
Cada ROI recibe su propia clase de Clasificación, seleccione la clase que describe ese ROI en esa imagen (por ejemplo, "pass" o "fail").
Si no está seguro de si usar Clasificación o Segmentación, comience con Clasificación. Es mucho más rápido de etiquetar y es bueno para la mayoría de los escenarios de aprobado/rechazado. Consulte Classifier vs. Segmenter para obtener orientación.
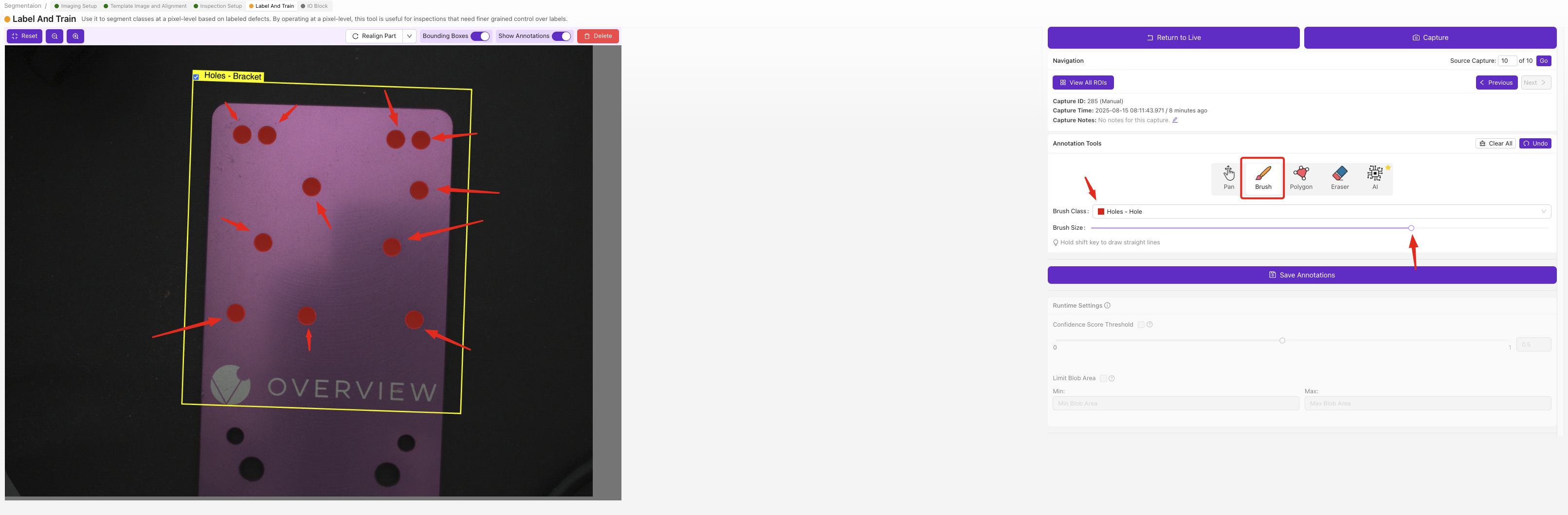
Para cada ROI en cada imagen, use la herramienta de pincel para pintar las áreas defectuosas píxel por píxel. Las regiones pintadas son lo que la AI aprende a detectar; cualquier cosa que no pinte se trata como fondo.
Las etiquetas del segmentador requieren trabajo de pincel a nivel de píxel, lo cual es más lento que las selecciones desplegables del clasificador, pero le brinda mapas precisos de defectos con ubicación y forma. Comience con un pequeño conjunto de defectos claramente definidos y solo agregue más clases una vez que su primer modelo esté funcionando.
4. Entrenar el modelo
- Classifier
- Segmenter
Haga clic en Train. El clasificador ofrece dos modos de entrenamiento:
- Fast mode, aproximadamente de 30 segundos a un minuto. Ideal para iteración rápida durante la configuración, verificación de la coherencia de sus etiquetas y piezas fáciles/bien diferenciadas. La precisión es menor que en modo de producción, pero le permite ver la señal rápidamente.
- Production mode, toma más tiempo pero produce un modelo notablemente más preciso. Siempre use el modo de producción antes de desplegar a la línea. Para piezas complicadas, defectos difíciles de distinguir, o cualquier cosa en la que confiará en producción, el modo de producción es la respuesta correcta.
Un buen ritmo: itere en Fast mode mientras limpia las etiquetas y agrega datos, luego ejecute Production una vez que el resultado se vea bien, y nuevamente antes de desplegar.
Haga clic en Train. La Segmentación tiene solo un modo de entrenamiento, Production, porque las máscaras a nivel de píxel necesitan una pasada de entrenamiento más exhaustiva para ser confiables. El tiempo de entrenamiento escala con el número de imágenes y el número de ROIs que haya etiquetado, por lo que un conjunto inicial pequeño (10-15 imágenes por clase) se entrena en unos minutos; los conjuntos de datos más grandes toman más tiempo.
No hay una opción de "fast" para verificación de coherencia aquí, así que asegúrese de que sus etiquetas estén limpias antes de entrenar (use View All ROIs para revisar cada máscara).
Un segmentador solo aprende los defectos que realmente pinta y le muestra. Cuantos más ejemplos incluya, cubriendo los diferentes tamaños, formas y ubicaciones que un defecto puede tomar, más confiablemente los enmascarará en producción.
¿Le faltan muestras de defectos? Use el Defect Creator Studio para generar más imágenes de entrenamiento del mismo defecto en diferentes tamaños, formas y posiciones, para que no tenga que esperar a que aparezcan en la línea.
5. Pruebe con Vista Previa en Vivo
Haga clic en Modo de Vista Previa en Vivo y procese piezas. Observe los resultados:
- ¿Está acertando en los casos fáciles?
- ¿Dónde tiene dificultades?
- ¿Cuáles son los casos límite?
Intente romperlo. Encuentre los casos donde falla. Estas fallas son su hoja de ruta para mejorar.
- Classifier
- Segmenter

El panel de Prueba muestra la clase predicha y la puntuación de confianza para cada ROI. Procese algunas capturas y busque veredictos de baja confianza (a menudo por debajo del 70%); esos son sus casos límite y las piezas más valiosas para etiquetar a continuación.
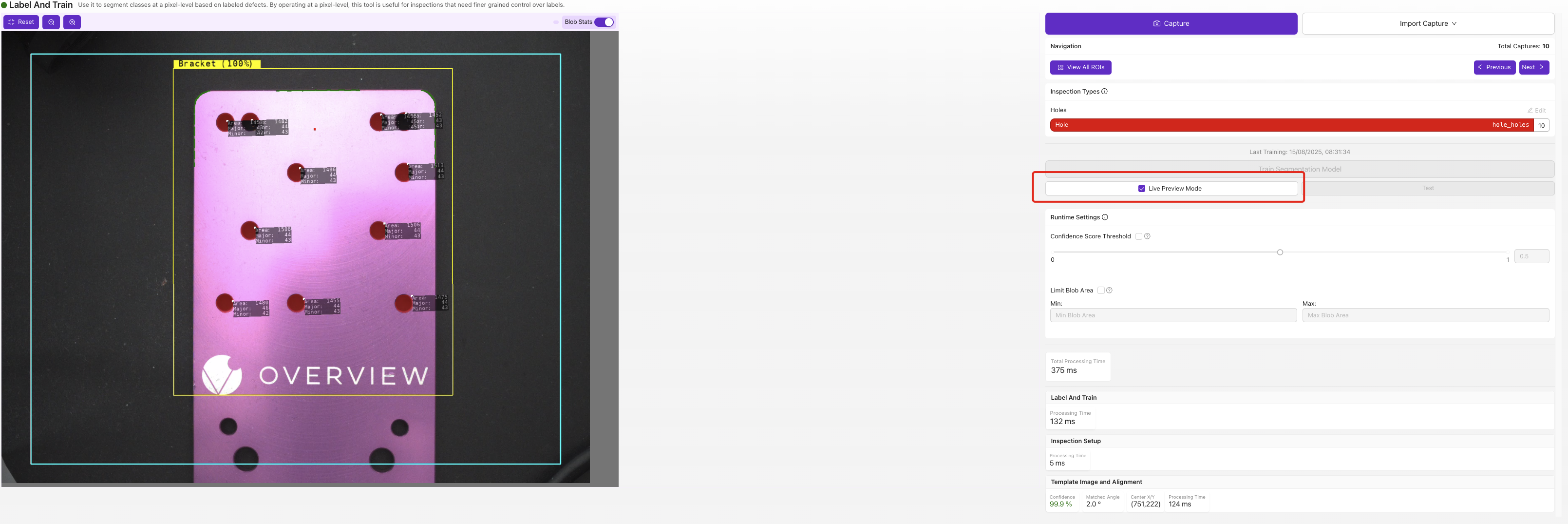
La Vista Previa en Vivo superpone la máscara de defecto predicha directamente sobre la imagen. Esté atento a máscaras que sean demasiado pequeñas, demasiado grandes o que aparezcan donde no hay un defecto real; esos son los modos de falla que abordará con la siguiente ronda de datos etiquetados.
6. Agregue datos específicos
No agregue imágenes nuevas al azar. Agregue imágenes que aborden específicamente los modos de falla que encontró:
- Si confunde rayones con reflejos, agregue más ejemplos de ambos
- Si pasa por alto defectos pequeños, agregue más imágenes de defectos pequeños
- Si falla en piezas en las esquinas, agregue más ejemplos de esquinas
7. Reentrene y vuelva a probar
Repita los pasos 4-6 de dos a cuatro veces. Cada iteración debería mejorar la precisión. Para un recorrido más detallado, incluyendo cómo agregar nuevas imágenes a un modelo existente sin perder el entrenamiento previo, consulte Añadiendo Datos y Reentrenamiento.
El modelo que eligió al crear la receta obtiene su propio paso: Paso 4: Clasificación para un clasificador, o Paso 4: Segmentación para un segmentador. Sus clases se definieron en el paso de Región de Interés (ROIs), por lo que este paso es donde captura imágenes, etiqueta, entrena y prueba. Ambos comparten las mismas seis sub-pestañas en la parte superior. Elija su tipo de modelo:
- Classifier
- Segmenter
Acerca de la Clasificación
Una guía breve para obtener un modelo preciso. Presenta el ciclo de iterar para alcanzar precisión (entrenar rápido, encontrar puntos débiles en la Vista Previa en Vivo, agregar datos específicos, reentrenar y luego promover al modelo de alta precisión de producción) y las mejores prácticas por clase que más importan: balancee sus clases, mantenga una alta relación señal-ruido y cubra los extremos de lo que desea detectar. Para una explicación más profunda de cómo un clasificador convierte cada ROI en un veredicto, lea Entendiendo el clasificador.
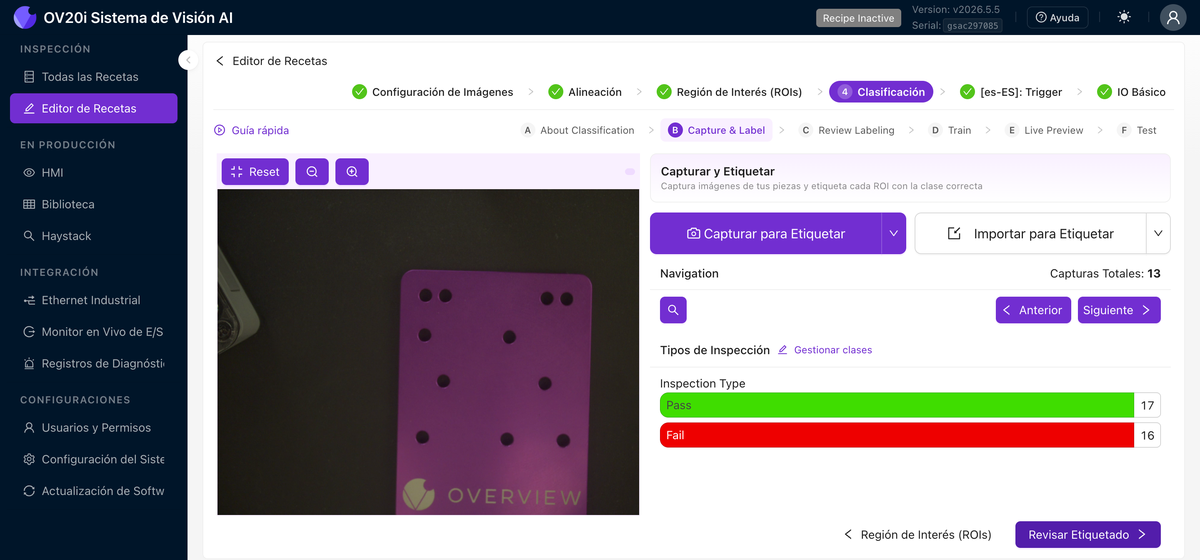
Captura y Etiquetado
Construya su conjunto de datos aquí. Use Capturar para Etiquetar para tomar cuadros de la cámara en vivo, o Importar para Etiquetar para cargar imágenes guardadas. Los controles de Navegación (Anterior, Siguiente, Búsqueda por ID de Captura, y el conteo total de capturas) le permiten desplazarse por el conjunto. Para cada captura, asigne cada ROI a una de sus clases. El conteo por clase (por ejemplo, Aprobar 17 / Fallar 16) muestra de un vistazo qué tan balanceado está su conjunto de datos, y Administrar clases lo lleva a donde se definen las clases.
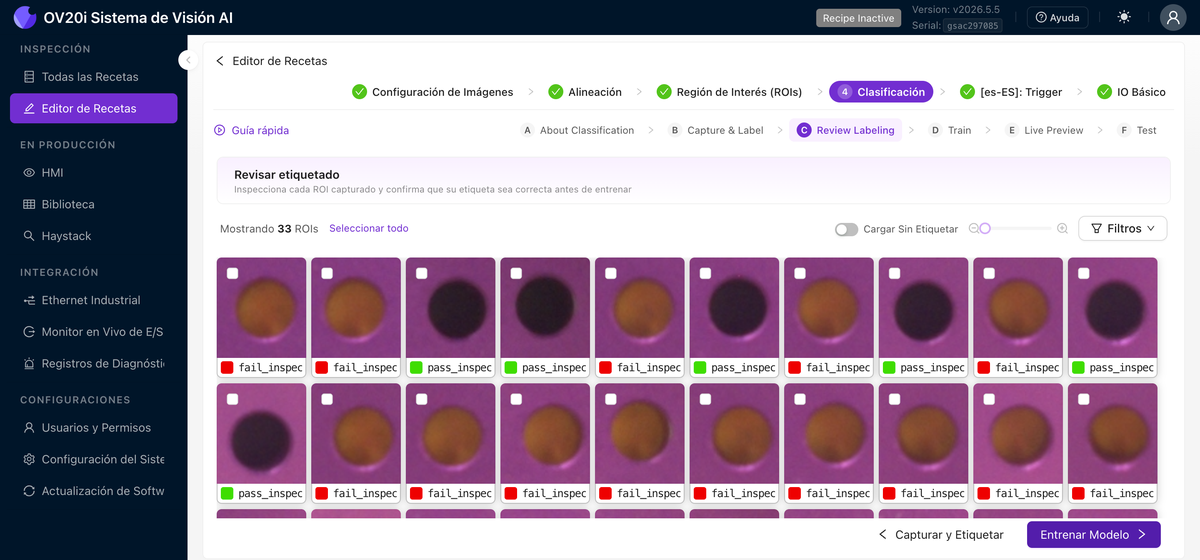
Revisar Etiquetado
Muestra cada recorte de ROI etiquetado en una sola cuadrícula, cada uno marcado con su clase, para que pueda escanear rápidamente en busca de errores de etiquetado. Use Filtros y Seleccionar todo para trabajar en ellos en bloque. Aquí es donde vive el hábito de "revisar cada etiqueta antes de entrenar" en v2026.5.
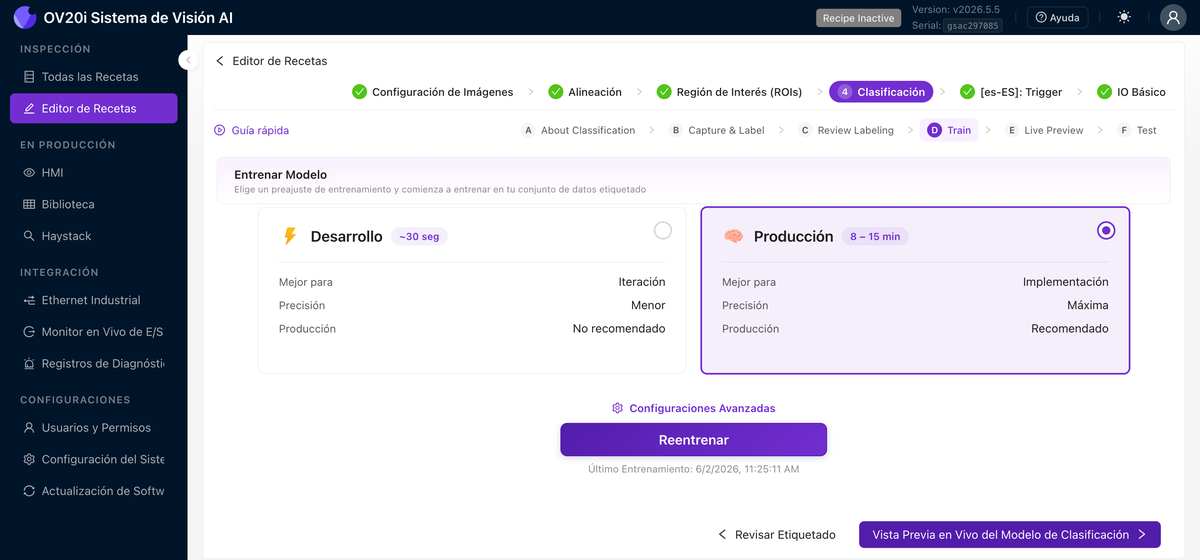
Entrenar
Elija un preajuste y comience a entrenar en su conjunto de datos etiquetado:
- Development se ejecuta en aproximadamente 30 segundos. Menor precisión, pero es el ciclo rápido que usa mientras limpia etiquetas y agrega datos.
- Production tarda de 8 a 15 minutos. Es el modelo de alta precisión que despliega a la línea.
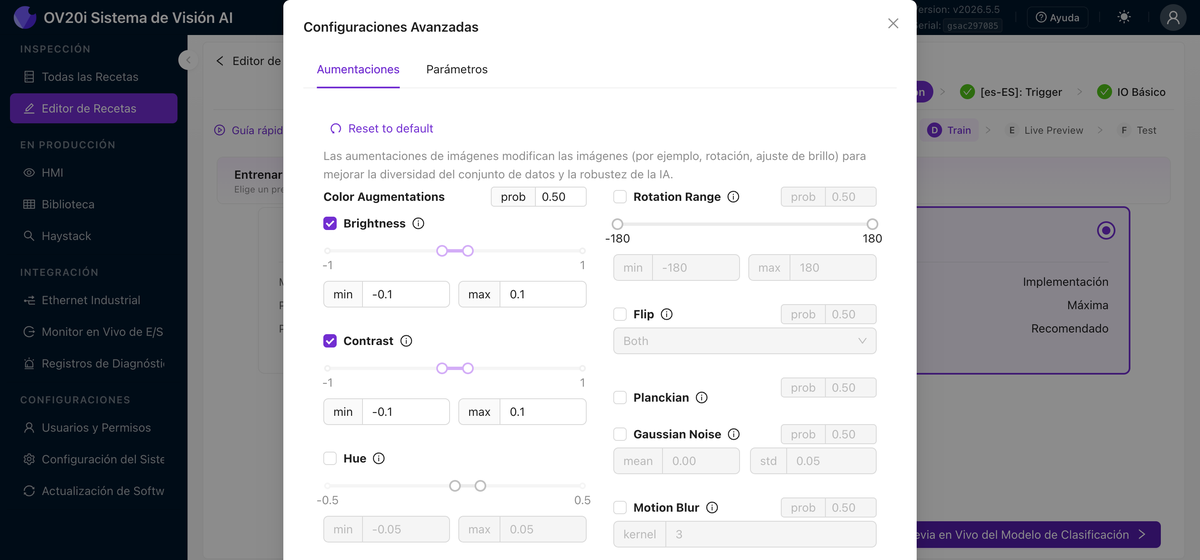
Configuraciones Avanzadas abre aumentos de datos (brillo, contraste, tono, rotación, volteo, Planckian, ruido gaussiano, desenfoque por movimiento) y parámetros de entrenamiento. Vea Aumentos de datos a continuación para saber cuándo usar cada uno. Reentrenar ejecuta el entrenamiento nuevamente después de agregar datos, y el último tiempo de entrenamiento se muestra junto a él.
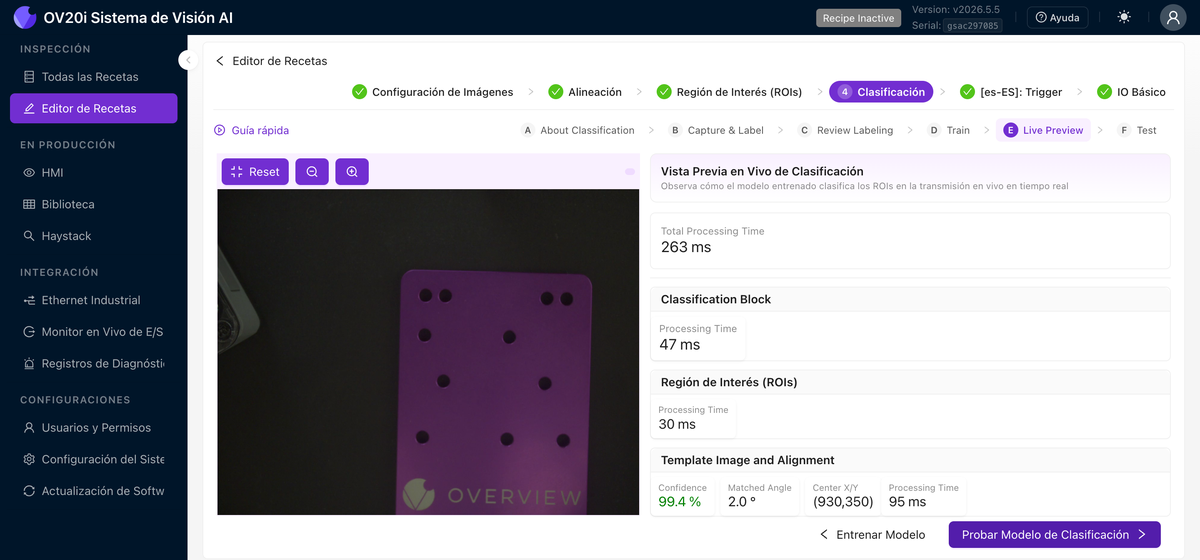
Vista Previa en Vivo
Ejecuta el modelo entrenado en la transmisión en vivo en tiempo real. Muestra la clase predicha de cada ROI junto con la confianza de alineación y el ángulo coincidente, y desglosa el tiempo de procesamiento por bloque (clasificación, ROIs, plantilla y alineación) para que pueda ver dónde se va el tiempo de ciclo. Pase piezas por el sistema y busque veredictos de baja confianza; esas piezas en el límite son las que vale la pena etiquetar a continuación.
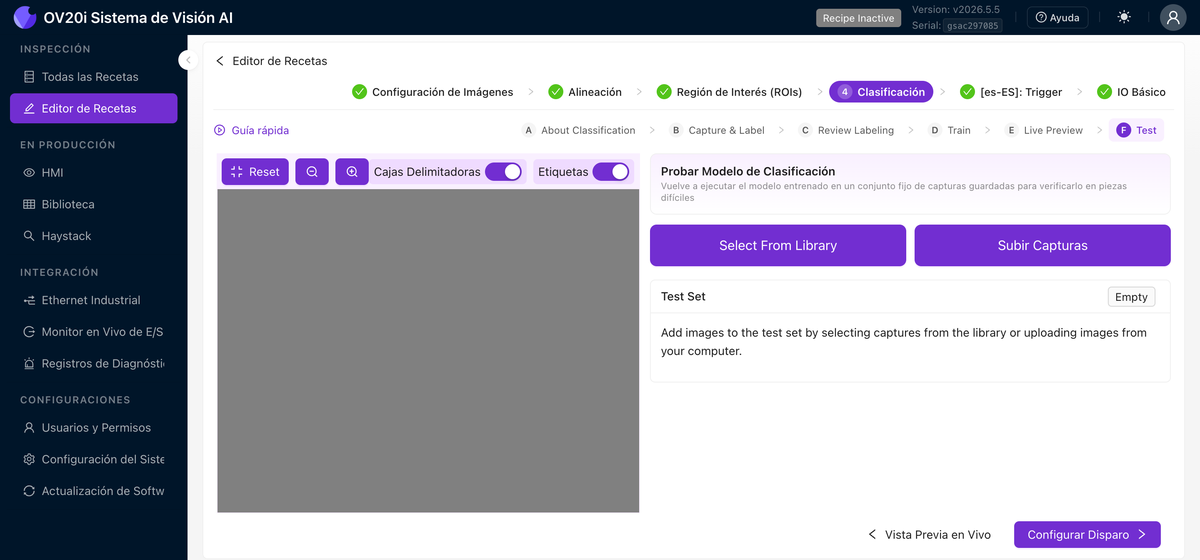
Prueba
Reejecuta el modelo entrenado contra un conjunto fijo de capturas guardadas (Seleccionar de la Biblioteca o Cargar Capturas) para que pueda verificar su funcionamiento en piezas difíciles sin esperar a que bajen por la línea. Active Bounding Boxes, Etiquetas y Mapa de Calor para ver cómo el modelo está decidiendo.
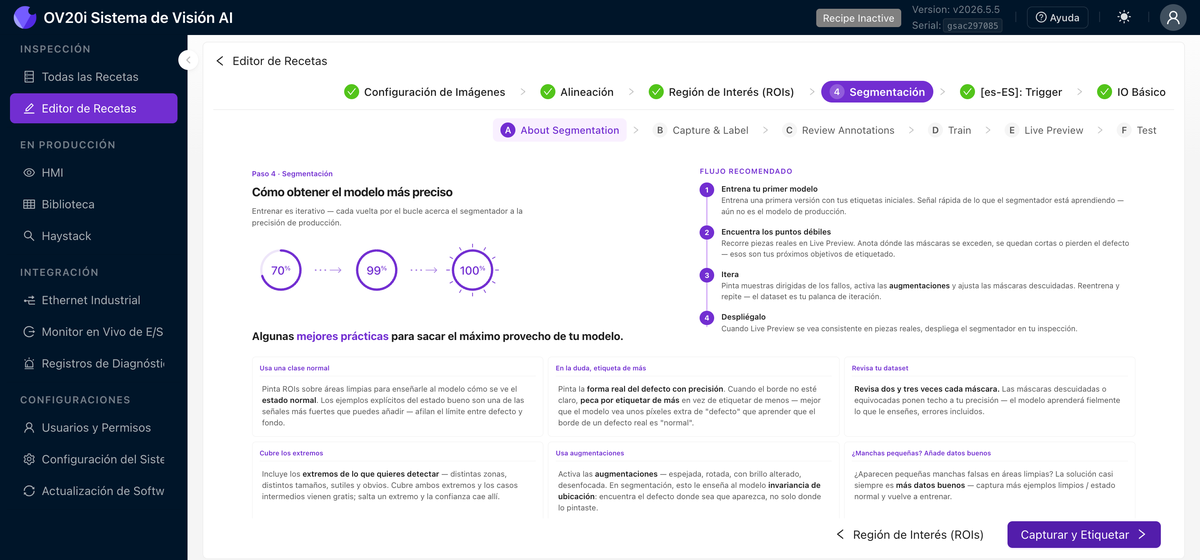
Acerca de la Segmentación
El mismo enfoque de iterar-hasta-lograr-precisión que el clasificador, con mejores prácticas específicas para máscaras: pinte máscaras limpias, prefiera una ligera superposición en el borde de un defecto en lugar de dejar un espacio, y cubra el rango completo de tamaños y texturas de defectos que espera. Para una explicación más profunda de cómo un segmentador produce máscaras de píxeles, conteos y mediciones, lea Entendiendo el Segmentador.
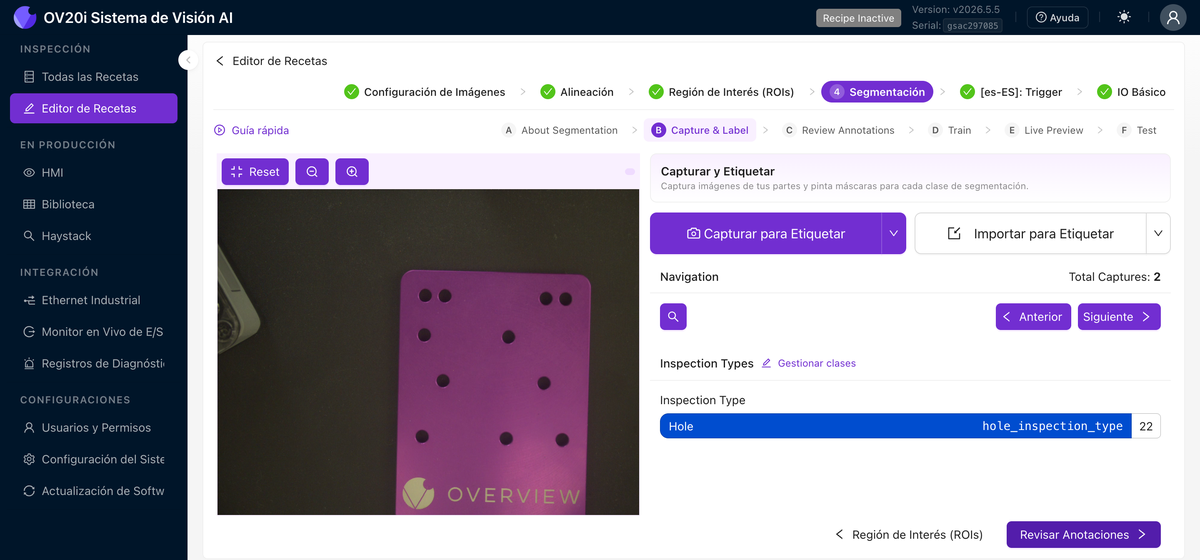
Captura y Etiquetado
Construye el conjunto de datos de la misma manera, pero en lugar de elegir una clase por ROI, pinta una máscara. Use Capturar para Etiquetar o Importar para Etiquetar, luego avance por las capturas con los controles de Navegación. Elija la clase que está etiquetando (cada una tiene su propio color de pincel), luego pinte sobre el defecto en la imagen. Los píxeles pintados son lo que el modelo aprende; todo lo que deje sin pintar es fondo.
La barra de herramientas de anotación le da una herramienta para cada situación:
| Herramienta | Lo que hace |
|---|---|
| Pan | Mueva la imagen sin pintar (úselo mientras tiene zoom) |
| Brush | Pinte libremente la máscara; ajuste el tamaño del pincel para trazos finos o anchos |
| Polygon | Haga clic en puntos para encerrar una región con bordes rectos, útil para defectos con bordes duros |
| Eraser | Eliminar pintura de una máscara que ya ha dibujado |
| AI | Etiquetado asistido por AI: haga clic en un defecto y la herramienta propone una máscara que puede aceptar o refinar |
Algunos controles más aceleran las cosas:
- Predict ejecuta su modelo entrenado en la captura y coloca su máscara predicha como punto de partida, para que la limpie en lugar de pintar desde cero. Esto solo funciona una vez que ha entrenado el modelo al menos una vez.
- Undo retrocede el último trazo.
- Clear All borra la máscara en la captura actual.
- Manage classes salta a la lista de clases.
Revisar Anotaciones
Muestra cada ROI capturada con su máscara pintada para que pueda verificar la cobertura antes del entrenamiento. Arrastre el deslizador Opacidad de máscara para comparar la máscara con la imagen, y use Filtros para acotar el conjunto. Esta es la versión del segmentador del hábito de "revisar cada etiqueta antes de entrenar".
Entrenar
La Segmentación tiene un solo preset, Producción (aproximadamente de 8 a 15 minutos). No hay opción rápida, ya que las máscaras a nivel de píxel necesitan el pase completo de entrenamiento para ser confiables. Configuración Avanzada expone los aumentos de datos y los parámetros, y Reentrenar vuelve a ejecutar el proceso después de añadir datos.
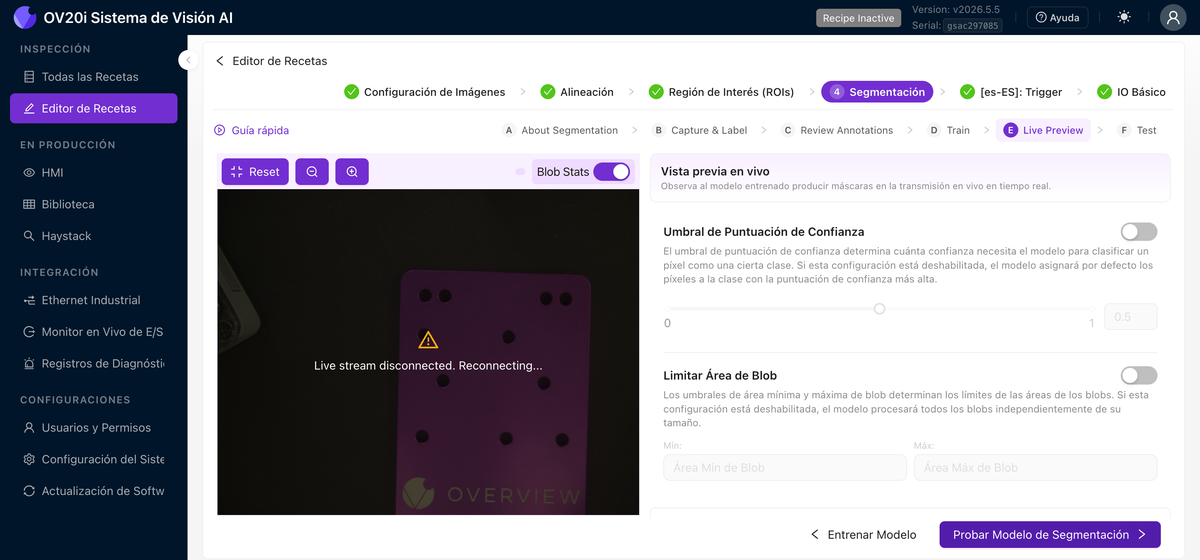
Vista Previa en Vivo
Ejecuta el modelo entrenado sobre la transmisión en vivo y superpone las máscaras de defectos predichas en tiempo real. Active Blob Stats para obtener conteos y áreas por blob, establezca el Umbral de Puntaje de Confianza (qué tan seguro debe estar el modelo para asignar un píxel a una clase), y use Limitar Área de Blob para ignorar blobs por debajo o por encima de un tamaño que usted establezca. Esté atento a máscaras que sean demasiado pequeñas, demasiado grandes o que aparezcan donde no hay un defecto real.
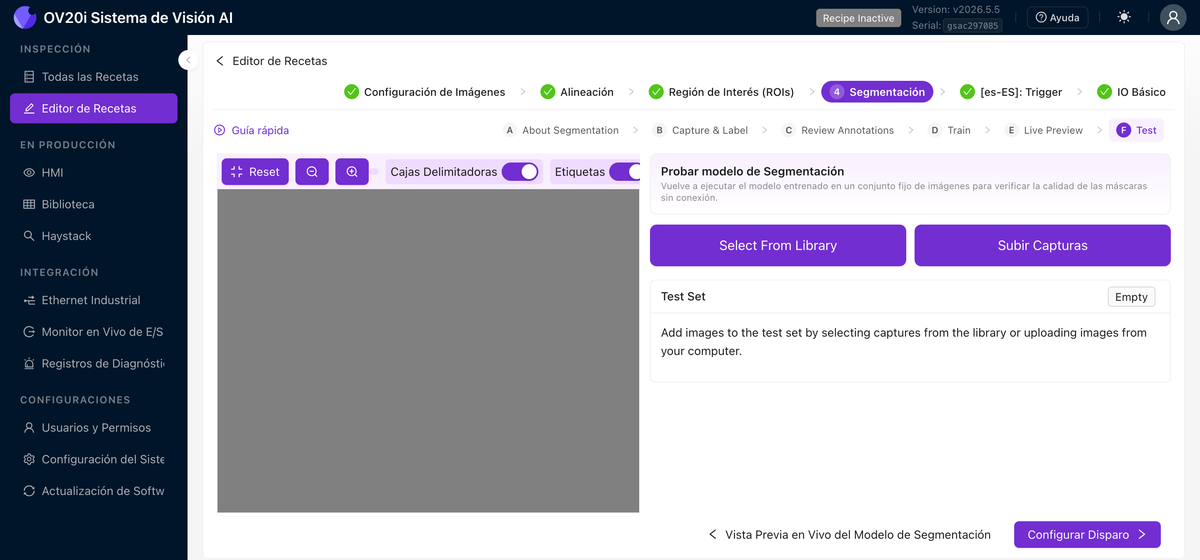
Prueba
Vuelva a ejecutar el modelo entrenado contra un conjunto fijo de capturas guardadas (Seleccionar de la Biblioteca o Cargar Capturas) para verificar la calidad de la máscara sin conexión. Active Cuadros Delimitadores, Etiquetas y Mapa de Calor para ver cómo el modelo está decidiendo.
Un segmentador solo aprende los defectos que usted realmente pinta y le muestra. Incluya tantos ejemplos como pueda, cubriendo los diferentes tamaños, formas y ubicaciones que puede tener un defecto. Si le faltan muestras, genere más con el Defect Creator Studio.
Aumentos de datos: enseñando a la IA a manejar la variación
Los aumentos de datos modifican aleatoriamente sus imágenes de entrenamiento durante el proceso de entrenamiento, ajustando el brillo, agregando rotación, modificando el contraste, etc. Cada imagen se alimenta a la IA cientos de veces con aumentos de datos ligeramente diferentes, pero la etiqueta permanece igual. Así es como se logra que un modelo sea robusto ante las condiciones del mundo real sin tener que capturar un ejemplo de cada variación posible.
Qué activar por defecto
Una pequeña cantidad de variación de brillo casi siempre vale la pena activar; incluso la fábrica más controlada tiene luces de techo que parpadean, sombras que se desplazan a lo largo del turno y una ligera deriva de los LED con el tiempo. El aumento de brillo hace que el modelo sea resistente a todo eso esencialmente sin costo.
Rotación: útil, pero vigile la forma de su ROI
El aumento por rotación es excelente si sus piezas realmente pueden llegar en diferentes ángulos (tornillos sueltos en una banda transportadora, piezas colocadas a mano, cualquier cosa que no esté sujeta en un fixture). Pero interactúa con la forma del ROI:
- ROI cuadrado: el aumento por rotación funciona limpiamente, la imagen rotada aún cabe dentro del cuadro del ROI.
- ROI no cuadrado en un clasificador: la rotación puede recortar la imagen. Cuando un ROI alto y estrecho se rota 45°, las esquinas del contenido rotado caen fuera del cuadro y el modelo entrena con una imagen parcial. Si su pieza puede rotar, haga el ROI cuadrado o confíe en el alineador para manejar la rotación aguas arriba, de modo que no necesite el aumento por rotación aquí.
- Segmentador: aplica la misma preocupación de recorte, pero la segmentación es menos sensible porque aprende a partir de máscaras de píxeles en lugar de la forma completa del ROI.
La diversidad de datos importa
Sus datos de entrenamiento deben representar todo el rango de lo que la AI verá en producción:
- Diferentes momentos del día (si la iluminación varía)
- Diferentes lotes de piezas (el acabado superficial puede variar ligeramente)
- Piezas en diferentes posiciones dentro del cuadro
- Tanto casos fáciles como difíciles
Enfóquese en los casos más difíciles. Si sus datos de entrenamiento incluyen las 10 piezas más difíciles de clasificar, entonces el 90% de las piezas fáciles serán triviales para la AI.
Cuántos datos realmente necesita
Necesita muchos menos datos que la mayoría de los sistemas de AI. La mayoría de las inspecciones funcionan muy bien con solo 5 a 10 imágenes por clase. Para un problema más difícil con múltiples defectos, 15 a 20 imágenes por clase suelen ser suficientes. Comience con poco, identifique dónde el modelo tiene dificultades en la Vista Previa en Vivo y agregue imágenes específicas solo donde las necesite, en lugar de recolectar cientos por adelantado.
Acelere con datos sintéticos: Defect Studio
¿Qué pasa si necesita entrenar para un defecto que rara vez ve? ¿Un tornillo faltante que tendría que quitar intencionalmente, un rayón que tendría que crear, una grieta que ocurre una vez por cada mil piezas? Esperar meses para recolectar suficientes ejemplos no es práctico.
El OV Auto-Defect Creator Studio en tools.overview.ai resuelve esto. Genera imágenes sintéticas de defectos fotorrealistas, hasta 10,000 veces más rápido que esperar a que aparezcan defectos reales en la línea de producción.
Cómo funciona: 5 pasos sencillos
- Cargue una imagen buena de su pieza
- Marque el área donde debería aparecer el defecto
- Describa el defecto en inglés sencillo (p. ej., "deep scratch across the surface" o "missing solder joint")
- Genere las variaciones del defecto (la AI crea resultados fotorrealistas)
- Exporte las imágenes sintéticas directamente a su conjunto de entrenamiento
Por qué funcionan los datos sintéticos
Las imágenes generadas no son simples artefactos "pegados". Son variaciones fotorrealistas que coinciden con su iluminación real, ángulo de cámara y superficie de la pieza. La AI entiende la física de cómo se ven los defectos bajo sus condiciones de imagen específicas.
Casos de uso:
- Defectos raros: Entrene para modos de falla que nunca (o rara vez) ha visto
- Lanzamientos de nuevos productos: Cree una inspección antes de que la primera pieza defectuosa salga de la línea
- Casos límite: Genere ejemplos en el límite para mejorar la frontera de decisión de la AI
- Aumento de datos: Complemente conjuntos de datos pequeños con variedad sintética
Véalo en acción
El mejor enfoque: entrene primero con sus 3 a 5 imágenes reales iniciales, identifique dónde la AI tiene dificultades, luego use Defect Studio para generar ejemplos sintéticos específicos para esos modos de falla particulares. Los datos reales enseñan la línea base; los datos sintéticos llenan los vacíos.
Lista de verificación de entrenamiento
Antes de continuar, confirme:
- Imágenes iniciales capturadas, mínimo 10-15 por clase
- Todas las etiquetas verificadas dos veces (Ver todos los ROIs)
- Entrenado y probado con Vista Previa en Vivo
- Modos de falla identificados y datos específicos agregados
- 2-4 iteraciones de etiquetar → entrenar → probar completadas
- Los resultados cumplen con las expectativas
¿Modelo entrenado y luciendo bien? Pase al Paso 5: Configuración de Salidas.