AI 驅動文件
您想了解什麼?
訓練分類器
本指南介紹如何在 OV10i 相機系統上配置和訓練分類模型。當您需要根據視覺特徵自動將物件分類到不同類別時,請使用此步驟。
影片指南
觀看本主題的實際操作:OV Auto-Defect Creator Studio
何時使用分類: 按型別、尺寸、顏色或狀態對零件進行分揀;識別不同的產品變體;具有多個可接受類別的質量控制。
先決條件
- 已配置影象設定的活動程式
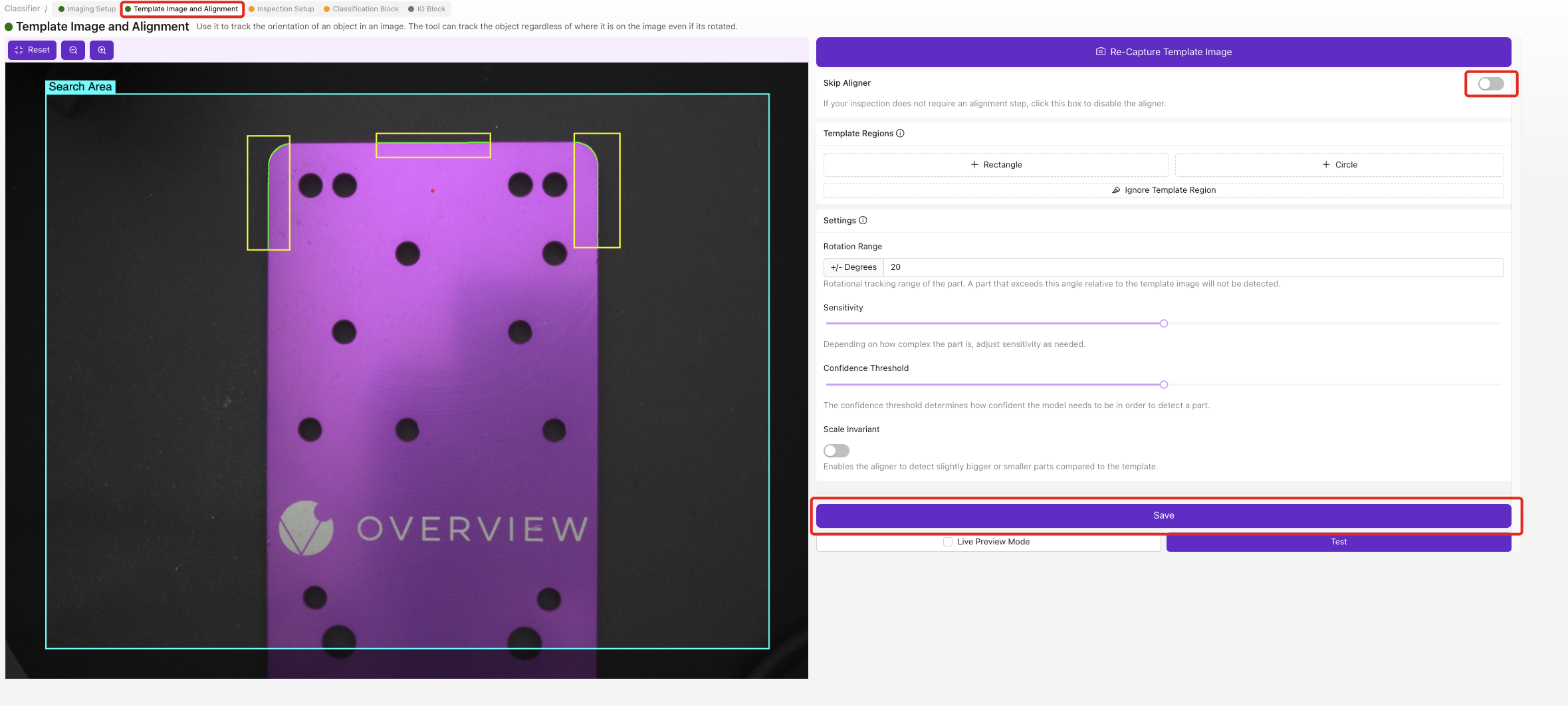
- 已完成模板影象和對齊(或已跳過)
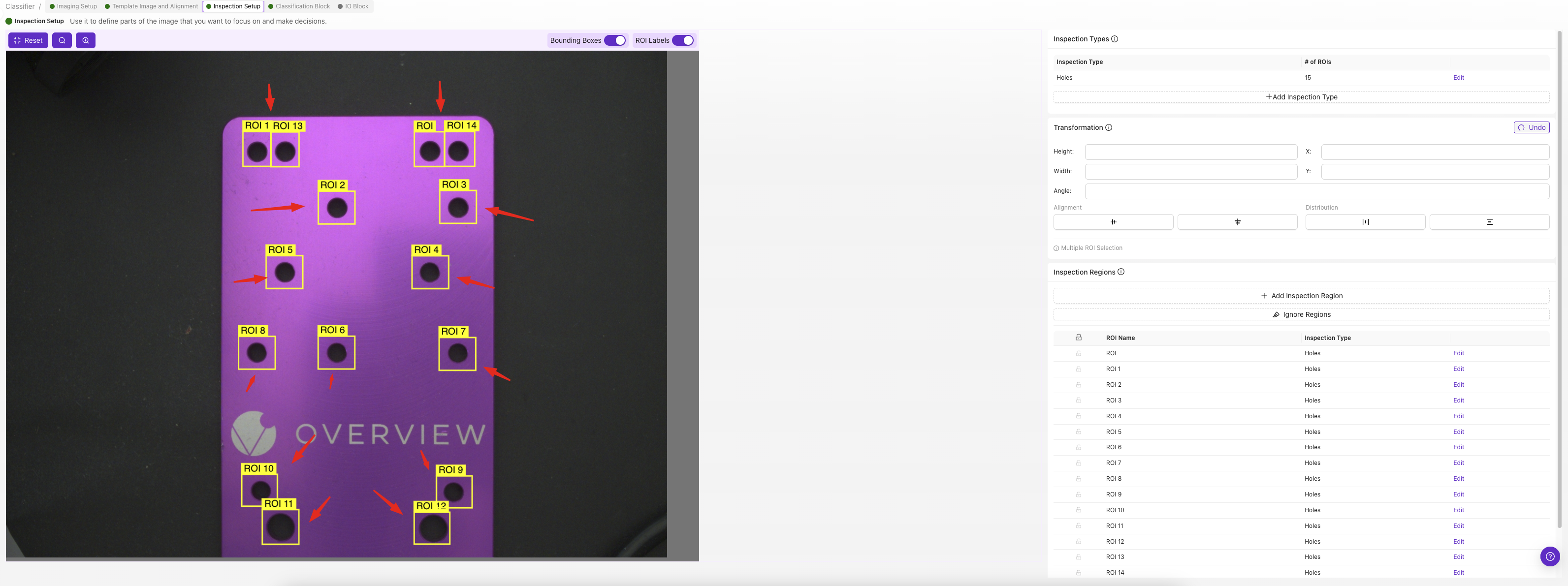
- 已定義檢查 ROI
- 代表您要檢測的每個類別的樣本物件
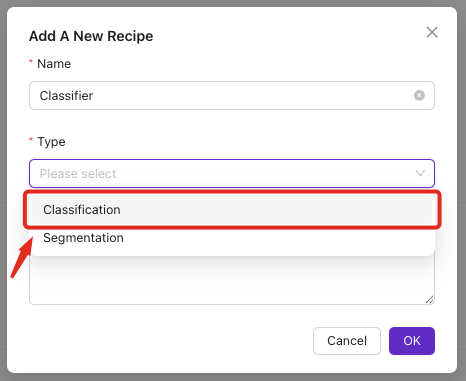
第一步:訪問分類模組
1.1 導航至分類
- 點選麵包屑選單中的 "Classification Block",或
- 從導航欄的下拉選單中選擇
![]()
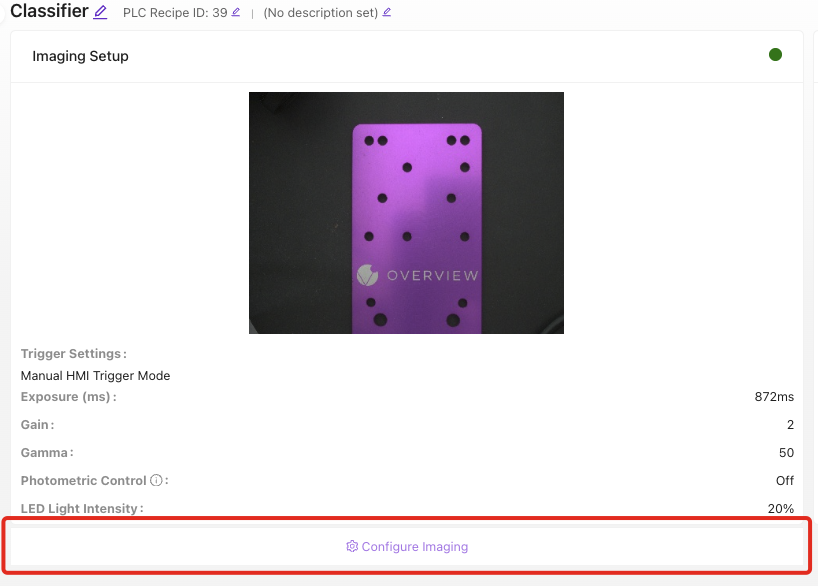
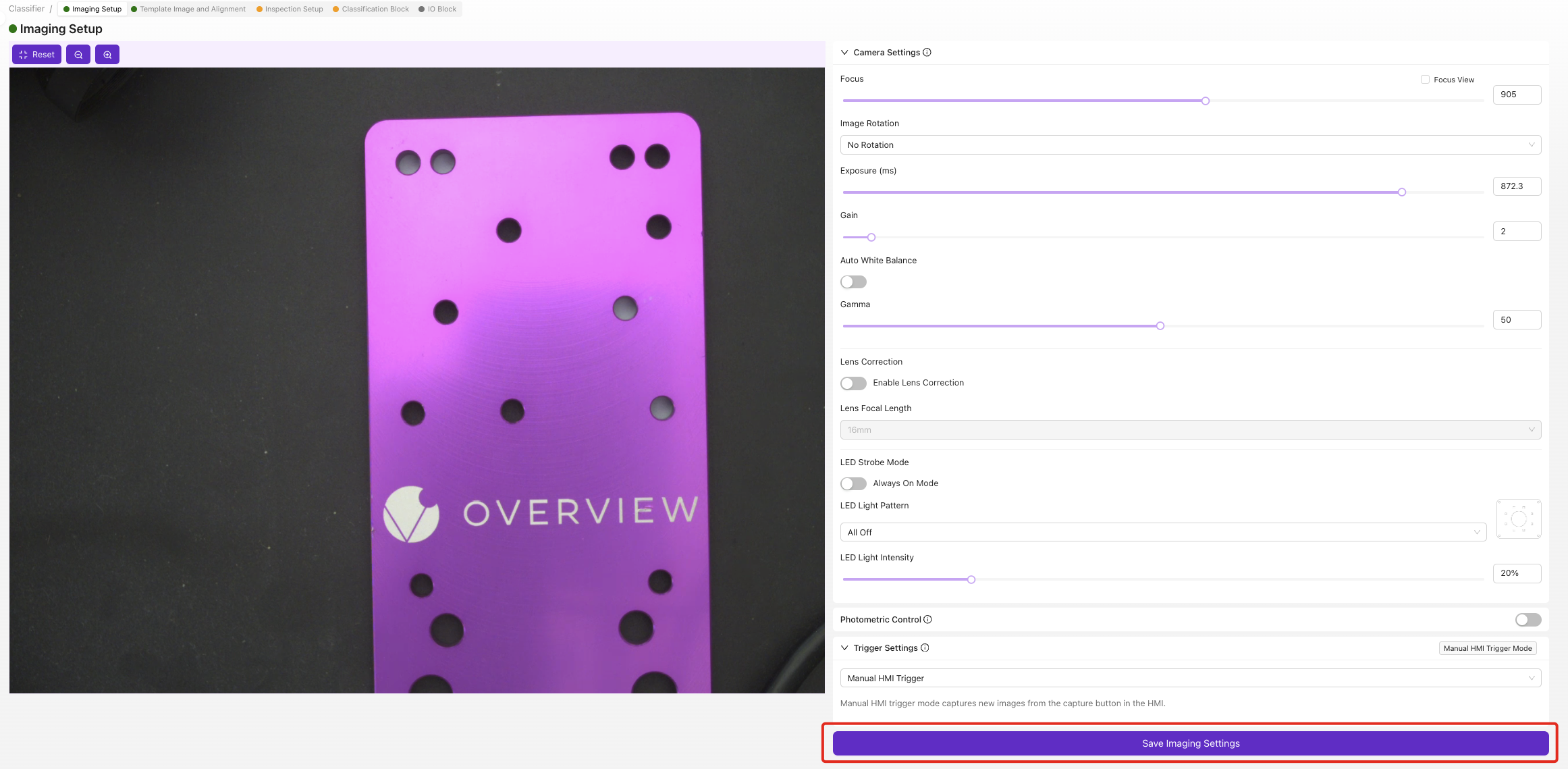
1.2 驗證先決條件
確保以下模組顯示綠色狀態:
- ✅ 影象設定
- ✅ 模板與對齊(或已跳過)
- ✅ 檢查設定
第二步:建立分類類別
2.1 定義您的類別
- 點選 "Inspection Types" 下的
Edit - 為您要檢測的每個類別新增類別
2.2 配置每個類別
對於每個類別:
- 輸入類別名稱: 使用描述性名稱(例如 "Small"、"Medium"、"Large")
- 選擇類別顏色: 選擇獨特的顏色以便於視覺識別
- 新增描述: 關於該類別的可選詳細資訊
- 點選
Save
2.3 類別命名最佳實踐
| 好的名稱 | 差的名稱 |
|---|---|
| Small_Bolt、Medium_Bolt、Large_Bolt | Type1、Type2、Type3 |
| Red_Cap、Blue_Cap、Green_Cap | Color1、Color2、Color3 |
| Good_Part、Defective_Part | Pass、Fail |
| Screw_PhillipsHead、Screw_Flathead | A、B |
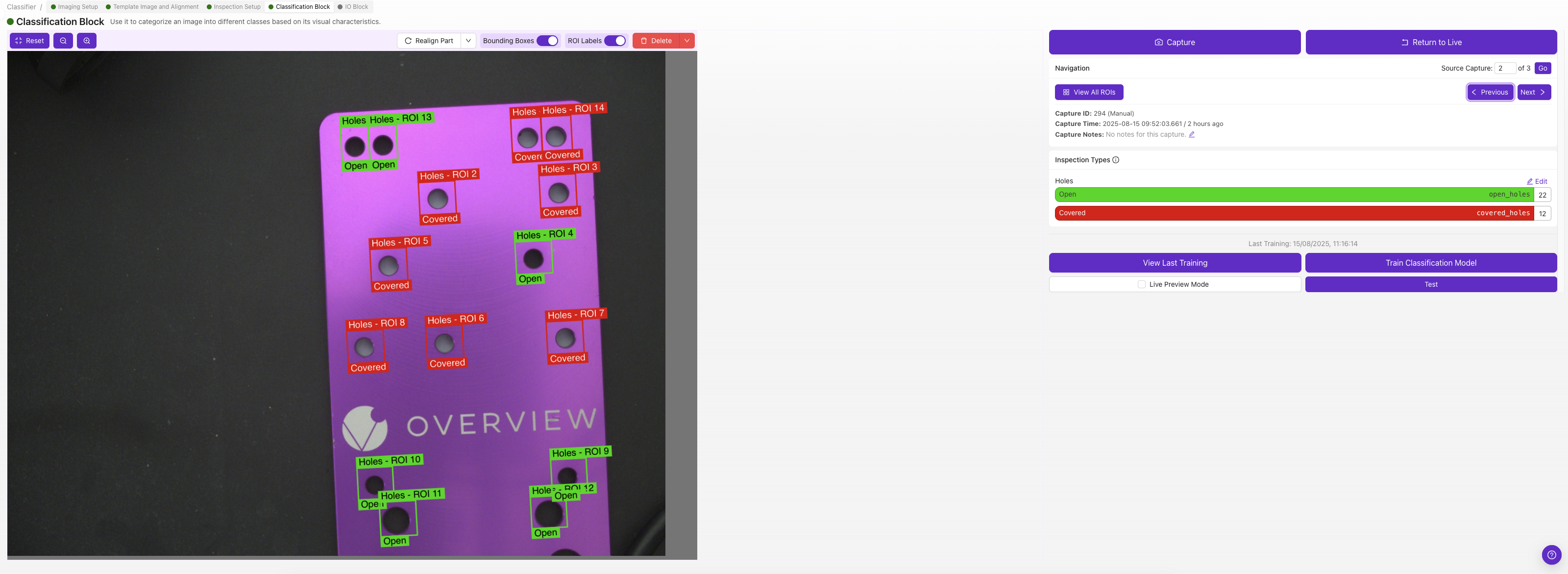
第三步:捕獲訓練影象
3.1 影象捕獲流程
為每個類別至少捕獲 5 張影象(推薦 10 張以上):
- 將代表該類別的物件放置在檢查區域
- 確認物件位於 ROI 範圍內
- 點選
Capture拍攝訓練影象 - 從下拉選單中選擇相應的類別
- 點選
Save儲存已標註的影象 - 使用同一類別的不同樣本重複操作
3.2 訓練資料要求
| 類別 | 最少影象數 | 推薦影象數 | 備註 |
|---|---|---|---|
| 每個類別 | 5 | 10-15 | 影象越多 = 準確度越高 |
| 總資料集 | 15+ | 30-50+ | 在所有類別間保持平衡 |
| 邊緣情況 | 每個類別 2-3 張 | 每個類別 5+ 張 | 臨界樣本 |
3.3 訓練影象最佳實踐
應當:
- 在每個類別中使用不同的樣本
- 變換物件的方向和位置
- 包含良好的光照條件
- 捕獲邊緣情況和臨界樣本
- 保持一致的 ROI 取景
不應:
- 重複使用相同的物件
- 在一個 ROI 中包含多個物件
- 在單張影象中混合多個類別
- 使用模糊或光線不足的影象
- 在多次捕獲之間更改 ROI 尺寸
3.4 質量控制
捕獲每張影象後:
- 在預覽中檢查影象質量
- 驗證類別標籤分配是否正確
- 使用
Delete按鈕刪除質量較差的影象 - 必要時重新拍攝
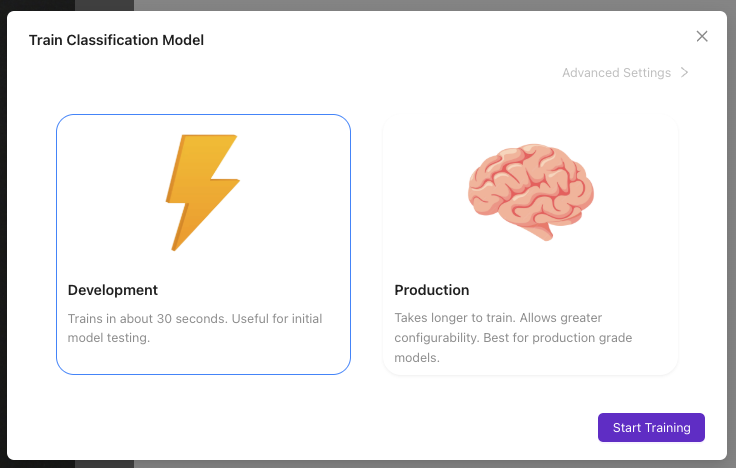
第四步:配置訓練引數
4.1 訪問訓練設定
- 點選
Train Classification Model按鈕
4.2 選擇訓練模式
根據需求選擇:
| 訓練模式 | 時長 | 準確率 | 使用場景 |
|---|---|---|---|
| Fast | 2-5 分鐘 | 適合測試 | 初始模型驗證 |
| Balanced | 5-15 分鐘 | 生產就緒 | 大多數應用 |
| Accurate | 15-30 分鐘 | 最高精度 | 關鍵應用 |
4.3 設定迭代次數
手動迭代設定:
- 低 (50-100): 快速測試,基礎準確率
- 中 (200-500): 生產質量
- 高 (500+): 最大準確率,訓練速度較慢
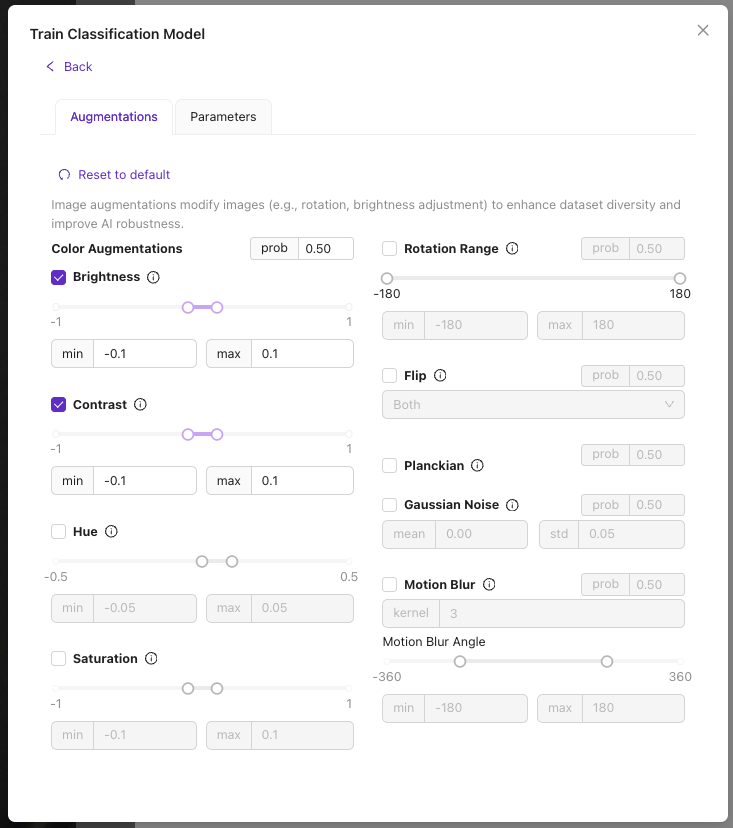
4.4 高階設定(可選)
批次大小 (Batch Size):
- 較小批次: 訓練更穩定,速度較慢
- 較大批次: 訓練更快,但可能不夠穩定
學習率 (Learning Rate):
- 較低值: 更穩定,學習速度較慢
- 較高值: 學習速度更快,但存在不穩定風險
建議: 除非您有特定的效能要求,否則請使用預設設定。
第五步:啟動訓練過程
5.1 初始化訓練
- 檢查訓練配置
- 點選
Start Training - 在訓練彈窗中監控進度
5.2 訓練進度指標
監控以下指標:
- 當前迭代 (Current Iteration): 訓練週期的進度
- 訓練準確率 (Training Accuracy): 模型在訓練資料上的效能
- 預計時間 (Estimated Time): 剩餘訓練時長
- 損失值 (Loss Value): 模型誤差(應隨時間下降)
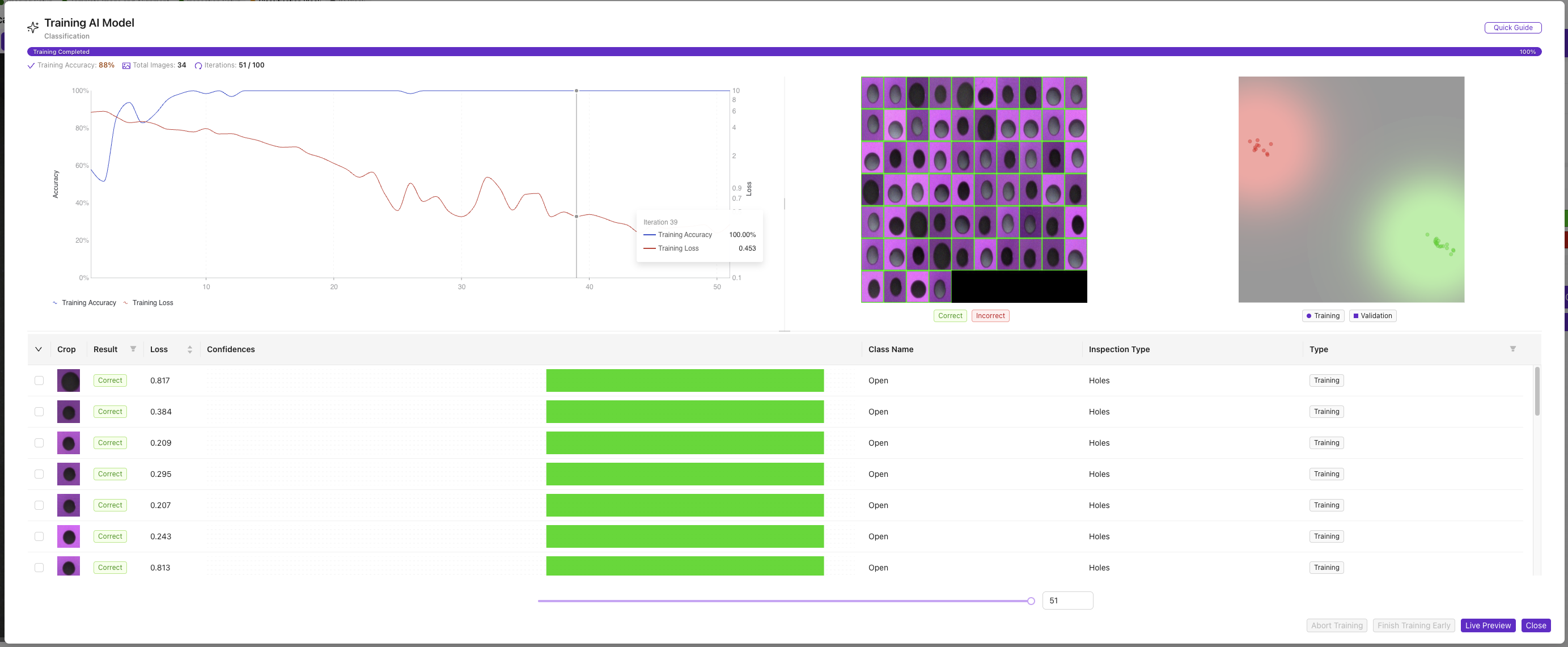
5.3 訓練控制
訓練期間可用的操作:
- Abort Training: 立即停止訓練
- Finish Early: 當前準確率足夠時停止
- Extend Training: 根據需要增加迭代次數
5.4 訓練完成
訓練在以下情況下自動停止:
- 達到目標準確率(通常為 95%+)
- 完成最大迭代次數
- 使用者手動停止訓練
第六步:評估模型效能
6.1 檢查訓練結果
檢查最終指標:
- 最終準確率: 生產使用應 >85%
- 訓練時間: 記錄時長以供將來參考
- 收斂性: 驗證準確率已穩定
6.2 模型質量指標
| 準確率範圍 | 質量等級 | 建議 |
|---|---|---|
| 95%+ | 優秀 | 可用於生產 |
| 85-94% | 良好 | 適用於大多數應用 |
| 75-84% | 一般 | 考慮增加訓練資料 |
| <75% | 較差 | 使用更多/更優影象重新訓練 |
6.3 效能不佳的故障排除
| 問題 | 可能原因 | 解決方案 |
|---|---|---|
| 準確率低 (<75%) | 訓練資料不足 | 新增更多已標註影象 |
| 訓練效果無提升 | 影象質量差 | 改善光照/對焦 |
| 類別混淆 | 物件外觀相似 | 新增更多區分性示例 |
| 過擬合 | 每個類別影象過少 | 平衡各類別的資料集 |
第 7 步:測試分類效能
7.1 實時測試
- 點選
實時預覽以進行實時測試 - 將測試物件放置 在檢查區域中
- 觀察分類結果:
- 預測的類別名稱
- 置信度百分比
- 處理時間
7.2 驗證測試
系統性驗證流程:
| 測試物件 | 預期類別 | 實際結果 | 置信度 | 透過/失敗 |
|---|---|---|---|---|
| 已知 A 類物件 | A 類 | _____ | ____% | ☐ |
| 已知 B 類物件 | B 類 | _____ | ____% | ☐ |
| 邊界示例 | A 類或 B 類 | _____ | ____% | ☐ |
| 未知物件 | 低置信度 | _____ | ____% | ☐ |
7.3 效能驗證
驗證以下方面:
- 準確性: 對已知物件的正確分類
- 置信度: 明確示例具有高置信度(>80%)
- 一致性: 對相同物件的可重複結果
- 速度: 滿足您應用所需的處理時間
第 8 步:模型最佳化
8.1 如果效能不理想
迭代改進流程:
- 識別問題區域:
- 哪些類別出現混淆?
- 哪些物件被錯誤分類?
- 置信度水平是否適當?
- 新增針對性的訓練資料:
- 更多被混淆類別的樣本
- 邊界情況和臨界示例
- 不同的照明/位置條件
- 重新訓練模型:
- 使用 "Accurate" 模式以獲得更好效能
- 增加迭代次數
- 監控準確性的改進
8.2 高階最佳化
針對關鍵應用:
- 資料增強: 使用多樣化的照明和位置
- 遷移學習: 從相似的已訓練模型開始
- 整合方法: 組合多個模型
- 定期重新訓練: 使用新的生產資料更新
第 9 步:完成配置
9.1 儲存模型
- 驗證效能令人滿意
- 訓練完成後模型自動儲存
- 記錄模型版本 以便存檔
9.2 文件記錄
記錄以下詳細資訊:
- 訓練日期和版本
- 每個類別的影象數量
- 使用的訓練模式和迭代次數
- 最終達到的準確性
- 任何特殊注意事項
9.3 備份配置
- 匯出程式 作為備份
- 單獨儲存訓練影象(如需要)
- 記錄模型引數
成功!您的分類器已就緒
您訓練好的分類模型現在可以:
- 自動分類 物件到已定義的類別中
- 提供置信度分數 用於每個預測
- 實時處理影象 以用於生產
- 與 I/O 邏輯整合 實現自動化決策
持續維護
定期模型更新
- 監控效能 隨時間變化
- 根據需要新增新的訓練資料
- 定期重新訓練 以保持準確性
- 更新類別 以適應新產品變體
效能監控
- 跟蹤生產中的準確性指標
- 識別模型效能漂移
- 根據效能下降安排重新訓練
後續步驟
訓練完分類器之後:
- 配置 I/O 邏輯 用於透過/失敗判定
- 在 IO模組中設定生產工作流
- 端到端測試完整的檢查系統
- 部署到生產 環境
常見陷阱
| 陷阱 | 影響 | 預防措施 |
|---|---|---|
| 訓練資料不足 | 準確性差 | 每個類別使用 10 張以上影象 |
| 類別不平衡 | 預測偏差 | 各類別影象數量均衡 |
| 影象質量差 | 結果不一致 | 最佳化光照和對焦 |
| 類別過於相似 | 分類混淆 | 選擇明確區分的類別定義 |
| 未進行驗證測試 | 生產環境故障 | 始終使用未見過的物件進行測試 |