KI-GESTÜTZTE DOKUMENTATION
Was möchten Sie wissen?
Erstellung des ersten Recipes
Dieser Deep Dive erklärt, was ein Recipe ist, beschreibt die Unterschiede zwischen Classification und Segmentation und bietet eine schrittweise Anleitung zur Erstellung eines Recipes. Er enthält außerdem eine detaillierte Anleitung zur Konfiguration des Imaging Setups, zur Aufnahme von Template Images und zur Einrichtung der Alignment, zur Optimierung von ROIs, zur Datenerfassung und zum AI-Training sowie zur Konfiguration der Bildaugmentierung.
Sehen Sie sich dieses Thema in der Praxis an: Wie man in wenigen Minuten ein Segmentation Recipe erstellt
Lernziele
Am Ende dieses Deep Dives werden Sie Folgendes verstehen:
- was ein Recipe ist
- den Unterschied zwischen Classification und Segmentation – und wann welche zu verwenden ist
- wie man ein Recipe erstellt
- wie man das Imaging Setup konfiguriert
- wie man ein Template Image aufnimmt und den Aligner konfiguriert
- was ROIs (Regions of Interest) sind und wie sie optimiert werden
- Datenerfassung für das AI-Training
- Testen und Validieren von Recipes
Was ist ein Recipe?
- Ein konfigurierter Satz von Anweisungen, der der Kamera mitteilt, wie ein bestimmtes Teil oder Produkt zu inspizieren ist.
- Definiert Kameraeinstellungen, einschließlich Belichtung, Fokus und Beleuchtungsparameter für eine konsistente Bildaufnahme.
- Beinhaltet Verarbeitungslogik wie ROI-Definitionen, Aligner, Classification- oder Segmentation-Klassen.
- Speichert Eingangs-/Ausgangskonfigurationen zur Integration in Automatisierungssysteme für Pass/Fail oder erweiterte Signale.
- Kann gespeichert und wiederverwendet werden, um konsistente Inspektionen über Schichten, Linien oder Standorte hinweg zu gewährleisten.
Classification vs. Segmentation
Definitionen
- Classification: Identifizierung des Objekttyps in der ROI
- Segmentation: Lokalisierung und Analyse von Bereichen im Bild/in der ROI
Beispiele
| Image Classification | Image Segmentation | Image Classification | Image Segmentation |
|---|---|---|---|
| Was ist ein Schaf? | Welche Pixel gehören zu welchem Objekt? | Ist diese Pizza akzeptabel oder fehlerhaft? | Wo befindet sich jede Peperoni? |
 |  |  |  |
Wichtiger Vergleich
| Classification | Segmentation | |
|---|---|---|
| Geschwindigkeit | Die Geschwindigkeit hängt vom Image Setup und der Komplexität ab. Bei einfachen Setups in der Regel effizient und schnell | Kann genauso schnell oder sogar schneller als Classification sein, wenn optimiert, insbesondere mit schlanken Modellen |
| Genauigkeit | Gut für allgemeine Pass/Fail- oder Teiletypidentifikation | Höhere Genauigkeit bei der präzisen Defektlokalisierung |
| Komplexität | Einfach einzurichten und zu warten; weniger Parameter | Komplex – Benötigt mehr Daten, Labeling und Tuning |
| Datenbedarf | Gering – Benötigt weniger gelabelte Bilder | Mittel – Erfordert viele Bilder mit detaillierten, pixelgenauen Annotationen |
| Anwendungsfälle | Teilanwesenheit, Ausrichtung, grundlegende Qualitätsprüfungen, Teil eingesetzt/nicht eingesetzt usw. | Oberflächendefekte, Feinmerkmalsinspektion, Multi-Defekt-Erkennung, Zählung, Messung usw. |
Erstellen und Exportieren eines Rezepts
Verwenden Sie die Schaltfläche Export Recipe neben einem Rezept, um ein einzelnes Rezept zu exportieren.
![]()
Verwenden Sie die Schaltfläche Export oben auf dem Bildschirm, um mehrere Rezepte gleichzeitig zu exportieren.

Verwenden Sie die Schaltfläche Import oben auf dem Bildschirm, um Rezepte zu importieren.

Hinweis: Jedes Rezept unterstützt jeweils nur einen Inspektionstyp, entweder Segmentierung oder Klassifizierung. Wählen Sie den richtigen Typ, bevor Sie mit der Einrichtung beginnen.
Imaging Setup
Focus

- Was es ist: Stellt die Schärfe des aufgenommenen Bildes ein.
- Verwendung: Schieben Sie den Regler, bis Kanten und Details im Bild scharf und klar erscheinen.
Verwenden Sie zum Fokussieren ein Zielobjekt mit klaren Kanten (z. B. ein Lineal oder eine Kalibrierkarte).
Image Rotation

- Was es ist: Dreht das Bild (0° oder 180°).
- Wann zu verwenden: Wenn die Kamera in einem bestimmten Winkel montiert ist, das Bild in der Oberfläche aber andersherum angezeigt werden soll.
Wenn Sie das Bild um 90° drehen müssen, drehen Sie die Kamera.
Exposure (ms)

- Was es ist: Die Dauer, in der der Sensor während der Bildaufnahme dem Licht ausgesetzt ist.
- Auswirkung:
- Höhere Belichtung → hellere Bilder, aber Gefahr von Bewegungsunschärfe.
- Niedrigere Belichtung → weniger Licht, aber schärfere Bilder bei schnellen Anwendungen.
| Unterbelichtet | Korrekt belichtet | Überbelichtet |
|---|---|---|
 |  |  |
Die Belichtung ist logarithmisch, und eine höhere Belichtung bedeutet mehr Latenz (da mehr Zeit für die Bildaufnahme erforderlich ist).
Gain

- Was es ist: Hellt das Bild digital künstlich auf (wie ISO bei einer Kamera).
- Auswirkung:
- Höherer Gain → helleres Bild, fügt aber Rauschen hinzu (körniges Aussehen).
- Niedrigerer Gain → saubereres Bild, erfordert aber gute Beleuchtung.
| Hoher Gain | Niedriger Gain |
|---|---|
 |  |
| Heller und verrauschter | Dunkler und weniger Rauschen |
Erhöhen Sie den Gain nur, wenn eine Anpassung von Belichtung oder Beleuchtung nicht möglich ist.
Auto White Balance

- Was es ist: Passt den Farbabgleich automatisch an, damit Weißtöne weiß erscheinen.
- Wann zu verwenden:
- Ideal für Umgebungen mit variablen oder wechselnden Lichtverhältnissen.
- Für stabile Setups liefert ein manueller Weißabgleich konsistentere und reproduzierbarere Ergebnisse.
So passen Sie den Weißabgleich manuell an:
- Schalten Sie den Auto White Balance-Schalter ON.
- Legen Sie ein weißes Blatt Papier unter die Kamera oder vor das Objektiv.
- Schalten Sie den Schalter OFF, um die Weißabgleich-Einstellung zu fixieren.
Gamma

- Was es ist: Passt die Helligkeit der Mitteltöne an, ohne dunkle oder helle Bereiche zu stark zu beeinflussen.
- Wirkung: Hilfreich, um Details in Schatten sichtbar zu machen oder zu helle Spitzlichter abzumildern.
Lens Correction

- Was es ist: Korrigiert Verzerrungen durch Weitwinkelobjektive.
- Wann aktivieren: Wenn die Bildränder gebogen oder verzerrt erscheinen, schalten Sie diese Option EIN, um die Genauigkeit bei Ausrichtungsaufgaben zu gewährleisten.
LED Strobe Mode

- Was es ist: Steuert, wann die integrierte LED-Beleuchtung der Kamera auslöst.
- Optionen:
- Off: LED ist dauerhaft eingeschaltet.
- On: LED blitzt nur während der Bildaufnahme, wodurch Reflexionen reduziert werden.
LED Light Pattern

- Was es ist: Legt fest, wie die LEDs leuchten (z. B. Alle ein, alle aus, links und rechts, oben und unten usw.).
- Anwendungsfall: Anpassung an Ihren Beleuchtungsaufbau für eine optimale Ausleuchtung des Bauteils.
Verwenden Sie gerichtete Beleuchtungsmuster, um Blendung oder Reflexionen zu reduzieren, indem Sie die LEDs ausschalten, die direkt auf reflektierende Oberflächen strahlen, und gleichzeitig schräge Lichtquellen aktiv lassen, um eine bessere Sichtbarkeit zu erzielen.
LED Light Intensity

- Was es ist: Stellt die Helligkeit der LED-Beleuchtung ein.
- Best Practice: Beginnen Sie mit einem niedrigen Wert und steigern Sie ihn schrittweise, um Blendung oder Reflexionen zu vermeiden.
Photometric Control

- Was es ist: Nimmt mehrere Bilder (typischerweise vier) mit unterschiedlicher gerichteter Beleuchtung (links, rechts, oben und unten) auf und kombiniert sie anschließend zu einem einzigen optimierten Bild.
- Zweck: Diese Technik reduziert Schatten und hebt feine Oberflächenmerkmale hervor, indem sie eine gleichmäßige, konsistente Ausleuchtung über das gesamte Bauteil bietet.
- Wann verwenden: Ideal für komplexe Bauteile, stark reflektierende Oberflächen oder Teile mit ungleichmäßigen Texturen, bei denen Standardaufnahmen mit Einzelbeleuchtung kritische Details übersehen könnten.
Trigger Settings
Manual Trigger
- Was es ist: Erfasst Bilder, wenn Sie die Taste auf dem HMI-Bildschirm drücken.
- Am besten für: Tests, Einrichtung oder manuelle Inspektionen.
Hardware Trigger
- Was es ist: Nutzt ein elektrisches Signal (z. B. von einem Sensor), um die Kamera auszulösen.
- Am besten für: Automatisierte Linien, bei denen ein Sensor die Anwesenheit des Bauteils erkennt.
PLC Trigger
- Was es ist: Triggersignale werden über industrielle Steuerungen (PLCs) gesendet, um einen synchronisierten Betrieb mit anderen Maschinen zu ermöglichen.
- Am besten für: Vollautomatisierte Systeme, die eine präzise Zeitsteuerung erfordern.
Aligner Trigger
- Was es ist: Löst automatisch aus, wenn das System eine Ausrichtung des Bauteils im Sichtfeld erkennt.
- Am besten für: Anwendungen, bei denen Bauteile vor der Aufnahme konsistent positioniert werden müssen oder wenn keine anderen zuverlässigen Trigger verfügbar sind.
Interval Trigger
- Was es ist: Löst die Kamera in festgelegten Zeitintervallen aus.
- Am besten für: Kontinuierliche Prozesse oder die Überwachung bewegter Linien ohne Bauteilerkennungssensoren.
Vorlagenbild und Ausrichtung
Skip Aligner

- Was es ist: Deaktiviert den Ausrichtungsschritt während der Inspektion.
- Wann zu verwenden: Wenn sich das Teil immer in der gleichen Position und Ausrichtung im Bild befindet.
Template Regions

- Was es ist: Definiert den/die Bereich(e) des Vorlagenbildes, die zur Ausrichtung verwendet werden.
- Rectangle: Zeichnen Sie eine rechteckige ROI.
- Circle: Zeichnen Sie eine kreisförmige ROI.
- Ignore Template Region: Schließen Sie bestimmte Bereiche von der Ausrichtung aus, um störende Muster oder irrelevante Merkmale zu vermeiden.
- Beste Anwendung: Hilft dem System, sich nur auf die markantesten Teilmerkmale zu konzentrieren, um eine genaue Ausrichtung zu erreichen.
Rotation Range
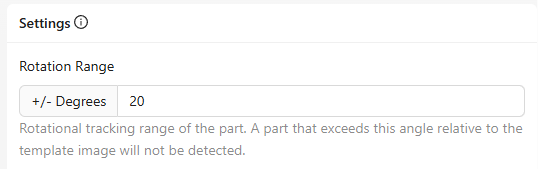
- Was es ist: Legt fest, wie viel Rotation (in Grad) das System beim Abgleich des Teils mit der Vorlage toleriert.
- Beispiel: Eine Einstellung von ±20° erlaubt es dem Teil, sich leicht zu drehen und dennoch erkannt zu werden.
- Wann anpassen: Erhöhen, wenn Teile während der Produktion zur Rotation neigen; verringern bei sehr konsistenten Ausrichtungen.
Sensitivity

- Was es ist: Steuert, wie fein das System nach einer Übereinstimmung zwischen dem Live-Bild und der Vorlage sucht.
- Auswirkung:
- Hohe Empfindlichkeit → erkennt subtilere Details, nützlich für komplexe Teile.
- Niedrigere Empfindlichkeit → reduziert Fehlerkennungen, kann aber feine Merkmale übersehen.
Confidence Threshold

- Was es ist: Legt den Mindest-Konfidenzwert fest, der erforderlich ist, damit das System eine Erkennung akzeptiert.
- Auswirkung:
- Höherer Schwellenwert → weniger Falschmeldungen, könnte aber Grenzfälle übersehen.
- Niedrigerer Schwellenwert → mehr Erkennungen, jedoch mit erhöhtem Risiko für Falschmeldungen.
Beginnen Sie mit einem moderaten Wert und passen Sie ihn basierend auf den Testergebnissen an.
Scale Invariant

- Was es ist: Ermöglicht dem System, Teile zu erkennen, die etwas größer oder kleiner als das ursprüngliche Vorlagenbild sind.
- Wann aktivieren: Wenn die Teilegröße aufgrund von Positionierung, Abstandsänderungen oder Fertigungstoleranzen leicht variieren kann.
Live Preview-Legende

1. Eine konfigurierbare Bounding Box, die den spezifischen Bereich des Sichtfelds (FOV) der Kamera definiert, der während der Triggerung überwacht werden soll.
- Zweck: Stellt sicher, dass sich die Kamera nur auf den relevanten Bereich konzentriert und unnötige Hintergrundbereiche ignoriert.
- Beste Anwendung:
- Bei bewegten Objekten, um zu gewährleisten, dass das Teil vollständig im Erkennungsbereich bleibt.
- Zur Optimierung der Verarbeitungsgeschwindigkeit, indem die Menge der analysierten Bilddaten reduziert wird.
2. Ein visueller roter Punkt, der den Mittelpunkt aller definierten ROIs (Regions of Interest) im Bild anzeigt.
- Zweck: Hilft Ihnen, den Suchbereich relativ zum Teil oder zur Kameraansicht auszurichten und zu positionieren.
3. Die grüne Linie zeigt an, dass die Kante des Objekts erkannt wurde.
Wenn sich die Linie rot färbt, versuchen Sie, die ROI-Größe zu erhöhen, die ROI anzupassen oder die Sensitivity zu erhöhen.

ROI (Region of Interest) Definition und Optimierung
Inspection Types

- Was es ist: Definiert den Inspektionstyp, der durchgeführt wird, und gruppiert ähnliche ROIs (Regions of Interest).
- Beispiel: „Holes" zur Überprüfung des Vorhandenseins, der Größe oder der Qualität von Löchern in einem Teil.
- Hauptmerkmale:
- Add Inspection Type: Neue Kategorien für unterschiedliche Inspektionsanforderungen erstellen.
- # of ROIs: Zeigt an, wie viele ROIs diesem Inspektionstyp aktuell zugewiesen sind.
Transformation
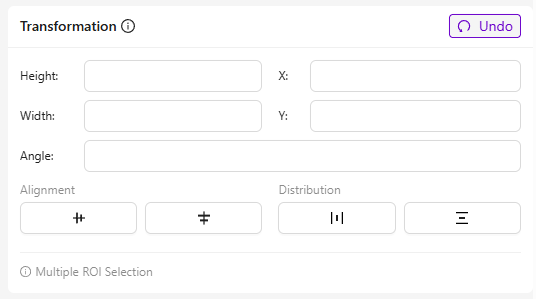
- Was es ist: Passt die Position und Geometrie ausgewählter ROIs für eine präzise Ausrichtung und Platzierung an.
- Felder und ihr Zweck:
- Height/Width: Ändert die Größe des ROI.
- X / Y: Verschiebt die Position des ROI entlang der horizontalen (X) und vertikalen (Y) Achse.
- Angle: Dreht den ROI um seinen Mittelpunkt.
- Beste Verwendung: Beschleunigt die Einrichtung bei sich wiederholenden Mustern, wie z. B. mehreren identischen Löchern.
Inspection Regions
- Was es ist: Eine Liste aller im Template-Bild definierten ROIs.
- Funktionen:
- Add Inspection Region: Manuell einen neuen ROI erstellen.
- Ignore Regions: Bestimmte Bereiche von der Verarbeitung ausschließen.
- Edit: Speichern, löschen oder abbrechen.
- Lock Icon: Zeigt gesperrte ROIs an, die ohne Entsperren nicht verschoben werden können.
Live Preview Mode
![]()
- Was es ist: Zeigt Echtzeit-Feedback nach dem Anpassen oder Hinzufügen von ROIs.
- Anwendungsfall: Ideal für die Feinabstimmung von ROI-Positionen und -Größen während der Einrichtung.
Test Button
![]()
- Was es ist: Backtesting auf Basis alter Bilder ausführen, um Änderungen zu verifizieren.
- Anwendungsfall: Vergleich aktueller Ergebnisse mit vorherigen Einstellungen auf Genauigkeit und Konsistenz.
Datenerfassung und KI-Training
Definieren Sie verschiedene Inspektionsklassen und kennzeichnen Sie jeden ROI basierend auf seinem zugewiesenen Inspektionstyp (siehe Beispiel unten).
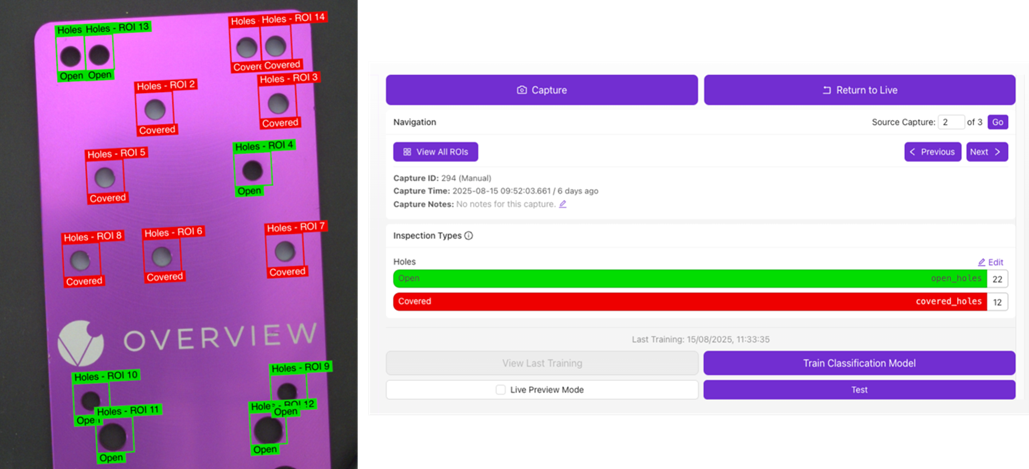
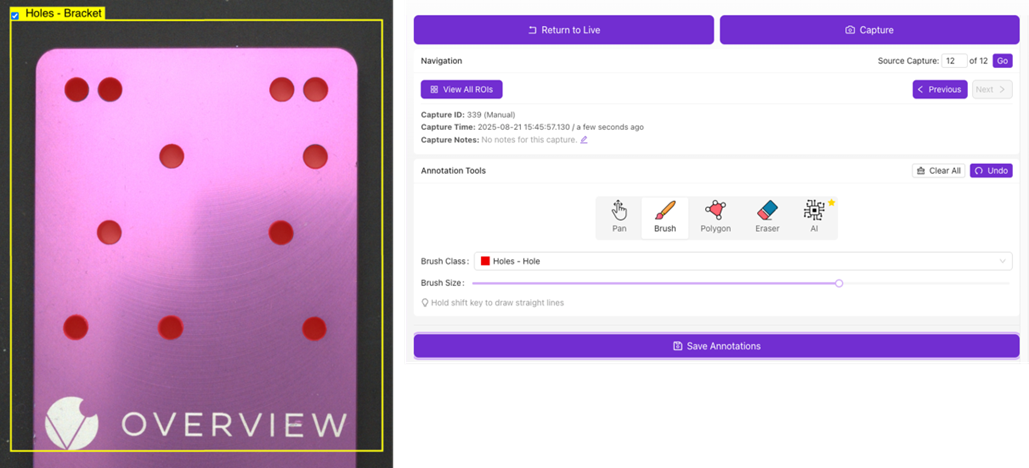
Verwenden Sie die Annotation Tools, um das Bild zu kennzeichnen/annotieren. Verwenden Sie das Dropdown-Menü Brush Class, um die zu annotierende Klasse auszuwählen. Die aktuelle Begrenzung beträgt bis zu 10 Klassen pro Rezept für Segmentierung.
Bedeutung guter Daten

-
Garbage In, Garbage Out: KI-Modelle können nur so gut sein wie die Daten, mit denen sie gefüttert werden. Daten von schlechter Qualität oder inkonsistente Daten führen zu ungenauen Ergebnissen.
-
Diversität ist entscheidend: Erfassen Sie Daten, die alle realen Variationen abbilden: unterschiedliche Schichten, Lichtverhältnisse, Teilepositionen und Oberflächenzustände.
-
Qualität vor Quantität: Ein kleinerer, sauberer und gut gekennzeichneter Datensatz liefert oft bessere Ergebnisse als ein großer, aber verrauschter oder inkonsistenter Datensatz.
Grundlagen der Annotation:
- Classification: Vollständige Bilder oder ROIs als eine bestimmte Klasse kennzeichnen (z. B. „Good", „Damaged").
- Segmentation: Bestimmte Bereiche von Interesse mit pixelgenauer Präzision übermalen, umranden oder markieren (z. B. Position eines Kratzers auf einer Oberfläche).
- Konsistenz: Verwenden Sie einheitliche Regeln und Definitionen für die Kennzeichnung, um Verwirrung während des Trainings zu vermeiden.

Häufige Fallstricke
- Unzureichende Daten: Zu wenige Proben führen zu Underfitting und damit zu schlechter Leistung in der Praxis.
- Unausgeglichene Klassen: Eine Überrepräsentation einer Klasse (z. B. viele „gute" Teile, aber wenige defekte) verzerrt das Modell.
- Schlechte Kennzeichnung: Falsche, inkonsistente oder überhastete Kennzeichnung führt zu erheblichen Genauigkeitseinbußen.
- Umgebungsveränderungen ignorieren: Wenn der Datensatz bei Änderungen der Beleuchtung, Teileausrichtung oder Oberflächenbedingungen nicht aktualisiert wird, kommt es zu einem Drift in der Genauigkeit.
- Daten nicht validieren: Das Überspringen von Qualitätsprüfungen vor dem Training führt häufig zu Zeitverschwendung und Nacharbeit.
Datenaugmentierung
Bildaugmentierungen modifizieren Ihre Trainingsbilder künstlich, um die Robustheit des Modells zu verbessern. Sie simulieren reale Variationen wie Helligkeitsänderungen, Rotationen oder Rauschen, damit das Modell unter verschiedenen Bedingungen zuverlässig funktioniert.
Farbaugmentierungen
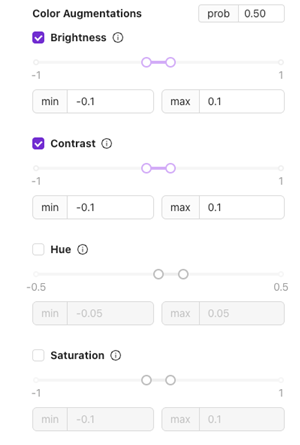
Brightness
- Was es ist: Passt an, wie hell oder dunkel das Bild erscheint.
- Anwendungsfall: Zur Handhabung geringfügiger Beleuchtungsänderungen während der Produktion.
Verwenden Sie ±0,1 für stabile Setups; erhöhen Sie den Wert, wenn die Beleuchtung stärker variiert.
Contrast
- Was es ist: Ändert den Unterschied zwischen hellen und dunklen Bereichen.
- Anwendungsfall: Nützlich für Teile mit Textur oder unterschiedlichen Oberflächen, um dem Modell die Anpassung an visuelle Unterschiede zu erleichtern.
Hue
- Was es ist: Verschiebt die Farbtöne geringfügig.
- Anwendungsfall: Geeignet für Setups, bei denen sich die Lichtfarbe (z. B. LED-Temperatur) mit der Zeit ändern kann.
Saturation
- Was es ist: Passt die Intensität der Farben an.
- Anwendungsfall: Hilft bei Beleuchtungsvariationen, die Bilder matter oder lebendiger erscheinen lassen.
Geometrische Augmentierungen
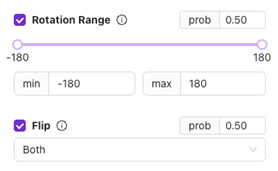
Rotation Range
- Was es ist: Dreht das Bild zufällig innerhalb des festgelegten Bereichs (z. B. ±20°).
- Anwendungsfall: Für Teile, die in leicht gedrehter Position eintreffen können.
Vermeiden Sie übermäßige Rotation für Teile, die normalerweise in fester Ausrichtung vorliegen.
Flip
- Was es ist: Spiegelt das Bild horizontal, vertikal oder beides.
- Anwendungsfall: Hilfreich für symmetrische Teile oder wenn sich die Ausrichtung beim Handling ändern kann.
Beleuchtungs- und Farbsimulation
Planckian
- Was es ist: Simuliert Variationen der Farbtemperatur (z. B. warmes oder kaltes Licht).
- Anwendungsfall: Berücksichtigt verschiedene Schichten oder Arbeitsplätze mit unterschiedlichen Lichtquellen.
Gaussian Noise
- Was es ist: Fügt dem Bild ein leichtes Rauschen hinzu.
- Anwendungsfall: Verbessert die Robustheit, wenn Ihre Produktionsumgebung geringes visuelles Rauschen oder Artefakte des Kamerasensors aufweist.
Bewegungssimulation
Motion Blur
- Was es ist: Simuliert leichte Unschärfe, als ob sich das Teil während der Aufnahme bewegt hätte.
- Anwendungsfall: Entscheidend für Hochgeschwindigkeitslinien, bei denen Bewegungsunschärfe auftreten kann.
Probability (prob)
![]()
- Was es ist: Legt die Wahrscheinlichkeit fest, mit der jede Augmentierung während des Trainings angewendet wird.
- Beispiel: 0,50 = 50 % Wahrscheinlichkeit, dass diese Änderung auf ein beliebiges Trainingsbild angewendet wird.
Beginnen Sie mit 0,5 für die meisten Augmentierungen und passen Sie den Wert basierend auf der realen Variabilität an.
Trainingsparameter (Segmentation)
Trainingsparameter (auch Hyperparameter genannt) sind die Einstellungen, die steuern, wie ein Machine-Learning-Modell aus Daten lernt.
Learning Rate

- Definition: Steuert, wie schnell das Modell seine internen Gewichte während des Trainings aktualisiert.
- Wert (0,003): Je höher die Lernrate, desto schneller lernt das Modell, aber zu hohe Werte können zu Instabilität oder geringer Genauigkeit führen.
- Slider-Bereich: Von 10^-4 (sehr langsam) bis 10^-1 (sehr schnell).
In der Regel ist ein Wert zwischen 0,001 und 0,01 ein guter Ausgangspunkt für Segmentierungsaufgaben.
ROI (Region of Interest) size

- Definition: Legt die Größe (Breite × Höhe) des Bildbereichs fest, der während des Trainings verwendet wird.
- Nicht aktiviert: Standardmäßig bestimmt das Modell die ROI automatisch anhand Ihrer Daten.
- Wenn aktiviert: Sie können Breite und Höhe manuell festlegen, wenn Sie einheitliche Eingabedimensionen benötigen (z. B. alle Bilder zugeschnitten auf 256×256 Pixel).
Verwenden Sie eine feste Größe (z. B. 256×256), wenn Ihr Datensatz Bilder unterschiedlicher Größe enthält und Sie eine einheitliche Eingabe für bessere Stabilität, Reproduzierbarkeit oder zur Übereinstimmung mit einer bekannten Modellarchitektur wünschen.
Lassen Sie die Größe automatisch wählen, wenn Ihre Daten bereits eine einheitliche Auflösung haben oder wenn das System basierend auf den Eigenschaften Ihres Datensatzes für die beste Region of Interest optimieren soll.
Number of Iterations (Epochs)

- Definition: Eine Epoche = ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz.
- Wert (100): Das Modell wird 100 vollständige Durchläufe trainieren.
Eine Erhöhung dieses Werts verbessert die Genauigkeit in der Regel bis zu einem gewissen Punkt, dauert jedoch länger.
Faustregel: Überwachen Sie während des Trainings den Trainings- und Validierungs-Loss. Wenn der Validierungs-Loss nicht weiter abnimmt, während der Trainings-Loss weiter sinkt, ist dies ein Zeichen für Overfitting, und Sie sollten das Training früher beenden.
Architecture

- Definition: Wählt die Größe und Komplexität des neuronalen Netzes aus.
- Small: Trainiert schneller und ist für die meisten Datensätze oft ausreichend. Ideal für schnelles Experimentieren oder kleinere Datensätze.
- Größere Modelle können mehr Details erfassen, neigen jedoch bei kleinen Datensätzen zu Overfitting, während kleinere Modelle effizienter sind und bei begrenzten Daten besser generalisieren.
Beginnen Sie mit Small – dies ist oft ausreichend und ermöglicht eine schnellere Iteration, bevor Sie skalieren.
External GPU

Kontaktieren Sie den Support, um mehr über External GPU zu erfahren.
Training Parameters (Classification)
Trainingsparameter (auch Hyperparameter genannt) sind die Einstellungen, die steuern, wie ein Machine-Learning-Modell aus Daten lernt.
Learning Rate

- Definition: Steuert, wie schnell das Modell während des Trainings seine internen Gewichte aktualisiert.
- Wert (0.003): Je höher die Learning Rate, desto schneller lernt das Modell, aber ein zu hoher Wert kann zu Instabilität oder geringer Genauigkeit führen.
- Schieberegler-Bereich: Von 10^-4 (sehr langsam) bis 10^-1 (sehr schnell).
Üblicherweise ist ein Wert zwischen 0.001–0.01 ein guter Ausgangspunkt für Segmentierungsaufgaben.
Validation Percent

- Definition: Legt fest, welcher Anteil Ihres Datensatzes für die Validierung (Testen während des Trainings) reserviert wird.
- Zweck: Validierungsdaten helfen dabei, die Leistung des Modells an unbekannten Beispielen zu überwachen und Overfitting zu verhindern.
- Bereich: 0–50 %.
Übliche Werte liegen bei 10–20 %.
Wenn der Wert auf 0 % gesetzt wird, werden alle Daten für das Training verwendet, was die Trainingsgenauigkeit verbessern kann, jedoch das Erkennen von Overfitting erschwert.
ROI (Region of Interest) Größe
- Definition: Legt die Größe (Breite × Höhe) des während des Trainings verwendeten Bildbereichs fest.
- Nicht aktiviert: Standardmäßig bestimmt das Modell die ROI automatisch anhand Ihrer Daten.
- Wenn aktiviert: Sie können Breite und Höhe manuell festlegen, wenn Sie konsistente Eingabeabmessungen benötigen (z. B. alle Bilder auf 256×256 Pixel zugeschnitten).
Verwenden Sie eine feste Größe (z. B. 256×256), wenn Ihr Datensatz Bilder unterschiedlicher Größen enthält und Sie konsistente Eingaben für bessere Stabilität, Reproduzierbarkeit oder zur Anpassung an eine bekannte Modellarchitektur wünschen.
Lassen Sie die Größe automatisch wählen, wenn Ihre Daten bereits eine einheitliche Auflösung haben oder wenn das System die beste Region of Interest basierend auf den Eigenschaften Ihres Datensatzes optimieren soll.
Anzahl der Iterationen (Epochs)
- Definition: Eine Epoche = ein vollständiger Durchlauf durch den gesamten Trainingsdatensatz.
- Wert (100): Das Modell wird für 100 vollständige Durchläufe trainiert.
Eine Erhöhung dieser Zahl verbessert die Genauigkeit in der Regel bis zu einem gewissen Punkt, dauert jedoch länger.
Faustregel: Überwachen Sie während des Trainings den Training- und Validation-Loss. Wenn der Validation-Loss nicht mehr sinkt, während der Training-Loss weiter abnimmt, ist dies ein Zeichen für Overfitting, und Sie sollten das Training frühzeitig stoppen.
Architektur
- Definition: Wählt die Größe und Komplexität des neuronalen Netzes aus.
- Small: Trainiert schneller und ist für die meisten Datensätze oft ausreichend. Ideal für schnelle Experimente oder kleinere Datensätze.
Beginnen Sie mit Small – dies ist oft ausreichend und ermöglicht schnellere Iterationen, bevor Sie skalieren.
| Architektur und Kamera | Beschreibung | Empfohlene Verwendung |
|---|---|---|
| ConvNeXt-Pico | Ultraleichtes Modell, optimiert für Geschwindigkeit und geringen Speicherbedarf. | Hervorragend geeignet für schnelle Experimente oder begrenzte Hardware. |
| ConvNeXt-Nano | Etwas größer als Pico; bessere Genauigkeit bei minimalem Mehraufwand. | Gute Balance für kleine bis mittelgroße Datensätze. |
| ConvNeXt-Tiny | Bietet verbesserte Genauigkeit bei weiterhin hoher Effizienz. | Geeignet für mittelgroße Datensätze und längere Trainingsläufe. |
| ConvNeXt-Small | Leistungsfähigste Variante in dieser Liste. Höhere Kapazität und Genauigkeit. | Für große Datensätze oder wenn maximale Leistung erforderlich ist. |
Externe GPU
Kontaktieren Sie den Support, um mehr über die externe GPU zu erfahren.